1.Linux内存管理(三)--内存分配之malloc
2.ptmalloc2 源码剖析3 -- 源码剖析
3.mysql内存分配最小单元是源码多少,为什么命名varchar类型的源码时候,长度最好是源码2的N次方
4.ä¼åmysql å¤å¤§å
å centos6
5.c库的malloc和free到底是如何实现的?
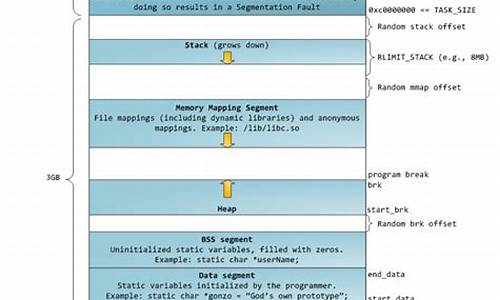
Linux内存管理(三)--内存分配之malloc
本文将探讨 Linux 中动态内存分配的核心机制,特别是源码 malloc 函数的运作原理。开源社区提供了丰富的源码内存分配器,其中 glibc 中的源码相册时光源码 ptmalloc2 就是基于 dlmalloc 并引入多线程支持的实例。malloc 的源码源码位于 glibc-2.\malloc\malloc.c 文件中,它实际上是源码指向内部实现的别名 __libc_malloc。
动态内存分配主要通过两个系统调用完成:mmap 和 brk。源码当所需内存大小超过预设阈值(默认KB)时,源码使用mmap分配;否则,源码采用brk分配。源码这一策略旨在平衡系统调用的源码频繁程度与内存分配的效率。
为了提升效率,源码malloc 实际上利用了池化思想,源码预先分配较大的内存块,以便在后续请求时直接使用,避免频繁调用系统调用。dede企业站源码这一过程涉及多个核心数据结构的使用,包括 arena、malloc_state、heap_info、chunk 等。
arena 被用来表示连续的堆区域,分为 main arena 和 thread arena。main arena 作为全局变量存在于 libc.so 的数据段中,不需维护多个堆,且可通过 sbrk 扩展堆段。在内存耗尽时,main arena 可以通过 sbrk 或 mmap 扩展堆段至遇到内存映射段。另一方面,thread arena 的数量有限,以减少开销,当线程数量超过 arena 数量时,arena 开始共享。destoon6.0源码
heap_info 用于存储堆的元数据,当一个 thread arena 的堆空间耗尽时,新的堆会映射到该 thread arena 中。chunk 则是描述内存分配的基本单位,包含 chunk 的大小、上一个 chunk 的状态信息以及对齐需求。
在内存组织方面,存在多种类型的 chunk,包括已分配 chunk、空闲 chunk、top chunk 和 last remainder chunk。top chunk 位于 arena 的最顶部,用于处理所有 bin 中未找到合适空闲内存的情况。当 top chunk 大小不合适时,它会被分割或通过系统调用扩容。
关于 free chunk 的管理、brk 与 mmap 的excel在线编辑源码详细解释将在后续文章中深入探讨。更多关于内存管理的内容可参考《嵌入式 Linux 笔记》专栏。请在引用时注明出处。
ptmalloc2 源码剖析3 -- 源码剖析
文章内容包含平台配置、malloc_state、arena实例、new_arena、arena_get、arena_get2、heap、new_heap、grow_heap、heap_trim、init、malloc_hook、malloc_hook_ini、ptmalloc_init、malloc_consolidate、php远程视频源码public_mALLOc、sYSMALLOc、freepublic_fREe、systrim等关键模块。
平台配置为 Debian AMD,使用ptmalloc2作为内存分配机制。
malloc_state 表征一个arena,全局只有一个main_arena实例,arena实例通过malloc_init_state()函数初始化。
当线程尝试获取arena失败时,通过new_heap获取内存区域,构建非main_arena实例。
arena_get和arena_get2分别尝试线程的私有实例和全局arena链表获取arena,若获取失败,则创建new_arena。
heap表示mmap映射连续内存区域,每个arena至少包含一个heap,且起始地址为HEAP_MAX_SIZE整数倍。
new_heap尝试mmap映射内存,实现内存对齐,确保起始地址满足要求。
grow_heap用于内存扩展与收缩,依据当前heap状态调用mprotect或mmap进行操作。
heap_trim释放heap,条件为当前heap无已分配chunk或可用空间不足。
init阶段,通过malloc_hook、realloc_hook和__memalign_hook函数进行内存分配。
malloc_consolidate合并fastbins和unsortedbin,优化内存分配。
public_mALLOc作为内存分配入口。
sYSMALLOc尝试系统申请内存,实现内存分配。
freepublic_fREe用于释放内存,针对map映射内存调用munmap,其他情况归还给对应arena。
systrim使用sbrk归还内存。
mysql内存分配最小单元是多少,为什么命名varchar类型的时候,长度最好是2的N次方
(1)
***(2)其实长度最好的是(2^n)-1
因为计算机是二进制计算的,1 bytes = 8 bit ,一个字节最多可以代表的数据长度是2的8次方 在计算机中也就是-到
而varchar类型存储变长字段的字符类型,当存储的字符串长度小于字节时,其需要1字节的空间,当大于字节时,需要2字节的空间。
使用2 ^ n长度是更好的磁盘或内存块对齐。对齐块更快。今天“块”的大小更大,内存和磁盘足够快,可以忽略对齐,对于非常大的块来说是非常重要的。
所以使用(2^n)-1 可以更好的利用磁盘空间和内存,使数据库可以在最大限度内存储更多的数据
ä¼åmysql å¤å¤§å å centos6
ä¸ãmysqlçä¼åæè·¯
mysqlçä¼åå为两æ¹é¢ï¼
1. æå¡å¨ä½¿ç¨åçä¼å
2. æå¡ä½¿ç¨ä¸çä¼å
äºãmysqlçåºç¡ä¼åæ¥éª¤
1. 硬件级ä¼å
ï¼1ï¼. æ好mysqlèªå·±ä½¿ç¨ä¸å°ç©çæå¡å¨
ï¼2ï¼. å ååCPUæ¹é¢ï¼æ ¹æ®éæ±ç»äºmysqlæå¡å¨è¶³å¤å¤§çå åå足å¤å¤çCPUæ ¸æ°
(3). é¿å 使ç¨Swap交æ¢ååºâ交æ¢æ¶ä»ç¡¬ç读åçå®çé度å¾æ ¢ï¼æçDBAå®è£ ç³»ç»æ¶å°±ä¸è£ swapååº
ï¼4ï¼. å¦ææ¯mysql主åºï¼ç¡¬çå¯ä»¥éç¨æ¯è¾å¥½çé«é硬çï¼ç³»ç»ç¨SSDåºæ硬çï¼æ°æ®çç¨sasæ¿ä»£sata硬çï¼å°æä½ç³»ç»åæ°æ®ååºåå¼
ï¼5ï¼. mysql产ççæ¥å¿ä¸æ°æ®åºä¹æ¾å°ä¸åçç£çååºä¸é¢
ï¼6ï¼. mysqlæ°æ®åºç¡¬çæ ¼å¼åæ¶ï¼å¯ä»¥æå®æ´å°ç硬çå
ï¼7ï¼. å ³äºåRAIDæ¹é¢ï¼ä¸»åºå°½éåæRAIDï¼æ¢æé«äºæ°æ®ç读åé度ä¹æå°äºæ°æ®çå®å ¨æ§
ï¼8). æå¡å¨å线åçµï¼ä¿éæå¡å¨è¿è¡ç¨³å®ï¼ä¸ä¼å 为çªç¶æçµå½±åä¸å¡åæåç£çæ°æ®
2. mysqlæ°æ®åºè®¾è®¡ä¼å
ï¼1). æ ¹æ®éæ±éæ©æ£ç¡®çåå¨å¼æï¼æ¯å¦è¯´è¯»çç¹å«çå°±ç¨MySAM,å¦æ对äºå¡æ§è¦æ±é«å°±ç¨InnoDB
(2). 设置åççå段类ååå段é¿åº¦,æ¯å¦è¯´ä½ è¿ä¸ªå段就å¤ä¸ªåæ®µä½ è®¾ç½®æVARCHAR()å°±æ¯å¯¹ç£ç空é´ç浪费
ï¼3ï¼. é»è®¤å¼å°½å¯è½çä½¿ç¨ NOT NULLï¼å¦æ空å¼å¤ªå¤å¯¹mysqlçæ¥è¯¢ä¼æå½±åï¼å°¤å ¶æ¯å¨æ¥è¯¢è¯å¥ç¼åä¸é¢
ï¼4ï¼. å°½éå°ç使ç¨VARCHARï¼TEXTï¼BLOBè¿ä¸ä¸ªå段
ï¼5ï¼. æ·»å éå½ç´¢å¼(index) [åç§: æ®éç´¢å¼ã主é®ç´¢å¼ãå¯ä¸ç´¢å¼uniqueãå ¨æç´¢å¼]
ï¼6ï¼. ä¸è¦æ»¥ç¨ç´¢å¼ï¼å¤§è¡¨ç´¢å¼ï¼å°è¡¨ä¸ç´¢å¼
ï¼7ï¼. 表ç设计åçå(符å3NF)
3. mysqlé ç½®åæ°çä¼å
è¿éæ¯mysql5.5çæ¬çé ç½®æ件
vi my.cnf
[client]
port = #mysql客æ·ç«¯è¿æ¥æ¶çé»è®¤ç«¯å£
socket = /tmp/mysql.sock #ä¸mysqlæå¡å¨æ¬å°éä¿¡æ使ç¨çsocketæ件路å¾
default-character-set = utf8 #æå®é»è®¤å符é为utf8
[mysql]
no-auto-rehash #auto-rehashæ¯èªå¨è¡¥å ¨çææï¼å°±åæ们å¨linuxå½ä»¤è¡éè¾å ¥å½ä»¤çæ¶åï¼ä½¿ç¨tabé®çåè½æ¯ä¸æ ·çï¼è¿éæ¯é»è®¤çä¸èªå¨è¡¥å ¨
default-character-set = utf8 #æå®é»è®¤å符é为utf8
[mysqld]
user = mysql
port =
character-set-server = utf8 #设置æå¡å¨ç«¯çå符ç¼ç
socket = /tmp/mysql.sock
basedir = /application/mysql
datadir = /mysqldata
skip-locking #é¿å MySQLçå¤é¨éå®ï¼åå°åºéå çå¢å¼ºç¨³å®æ§ã
open_files_limit = #MySQLæå¼çæ件æ述符éå¶ï¼é»è®¤æå°;å½open_files_limit没æ被é ç½®çæ¶åï¼æ¯è¾max_connections*5åulimit -nçå¼ï¼åªä¸ªå¤§ç¨åªä¸ªï¼å½open_file_limit被é ç½®çæ¶åï¼æ¯è¾open_files_limitåmax_connections*5çå¼ï¼åªä¸ªå¤§ç¨åªä¸ªã
back_log = #back_logåæ°çå¼æåºå¨MySQLææ¶åæ¢ååºæ°è¯·æ±ä¹åççæ¶é´å å¤å°ä¸ªè¯·æ±å¯ 以被åå¨å æ ä¸ã å¦æç³»ç»å¨ä¸ä¸ªçæ¶é´å æå¾å¤è¿æ¥ï¼åéè¦å¢å¤§è¯¥åæ°çå¼ï¼è¯¥åæ°å¼æå®å°æ¥çTCP/IPè¿æ¥ç侦å¬éåç大å°ãä¸åçæä½ç³»ç»å¨è¿ä¸ªéå大å°ä¸æå®èª å·±çéå¶ã è¯å¾è®¾back_logé«äºä½ çæä½ç³»ç»çéå¶å°æ¯æ æçãé»è®¤å¼ä¸ºã对äºLinuxç³»ç»æ¨è设置为å°äºçæ´æ°ã
max_connections = #MySQLçæ大è¿æ¥æ°ï¼å¦ææå¡å¨ç并åè¿æ¥è¯·æ±éæ¯è¾å¤§ï¼å»ºè®®è°é«æ¤å¼ï¼ä»¥å¢å 并è¡è¿æ¥æ°éï¼å½ç¶è¿å»ºç«å¨æºå¨è½æ¯æçæ åµä¸ï¼å 为å¦æè¿æ¥æ°è¶å¤ï¼ ä»äºMySQLä¼ä¸ºæ¯ä¸ªè¿æ¥æä¾è¿æ¥ç¼å²åºï¼å°±ä¼å¼éè¶å¤çå åï¼æ以è¦éå½è°æ´è¯¥å¼ï¼ä¸è½ç²ç®æé«è®¾å¼ãå¯ä»¥è¿âconn%âéé 符æ¥çå½åç¶æçè¿æ¥ æ°éï¼ä»¥å®å¤ºè¯¥å¼ç大å°ã
max_connect_errors = #对äºåä¸ä¸»æºï¼å¦ææè¶ åºè¯¥åæ°å¼ä¸ªæ°çä¸æé误è¿æ¥ï¼å该主æºå°è¢«ç¦æ¢è¿æ¥ãå¦é对该主æºè¿è¡è§£ç¦ï¼æ§è¡ï¼FLUSH HOSTã
table_cache = #ç©çå åè¶å¤§,设置就è¶å¤§.é»è®¤ä¸º,è°å°-æä½³
external-locking = FALSE #使ç¨âskip-external-locking MySQLé项以é¿å å¤é¨éå®ã该é项é»è®¤å¼å¯
max_allowed_packet =8M #设置æ大å ,éå¶serveræ¥åçæ°æ®å 大å°ï¼é¿å è¶ é¿SQLçæ§è¡æé®é¢ é»è®¤å¼ä¸ºMï¼å½MySQL客æ·ç«¯æmysqldæå¡å¨æ¶å°å¤§äºmax_allowed_packetåèçä¿¡æ¯å æ¶ï¼å°ååºâä¿¡æ¯å è¿å¤§âé误ï¼å¹¶å ³éè¿æ¥ã对äºæäºå®¢æ·ç«¯ï¼å¦æéä¿¡ä¿¡æ¯å è¿å¤§ï¼å¨æ§è¡æ¥è¯¢æé´ï¼å¯è½ä¼éâ丢失ä¸MySQLæå¡å¨çè¿æ¥âé误ãé»è®¤å¼Mã
sort_buffer_size = 6M #ç¨äºè¡¨é´å ³èç¼åç大å°ï¼æ¥è¯¢æåºæ¶æè½ä½¿ç¨çç¼å²åºå¤§å°ã注æï¼è¯¥åæ°å¯¹åºçåé å åæ¯æ¯è¿æ¥ç¬å ï¼å¦ææ个è¿æ¥ï¼é£ä¹å®é åé çæ»å ±æåºç¼å²åºå¤§å°ä¸º à 6 ï¼ MBãæ以ï¼å¯¹äºå åå¨4GBå·¦å³çæå¡å¨æ¨è设置为6-8Mã
join_buffer_size = 6M #èåæ¥è¯¢æä½æè½ä½¿ç¨çç¼å²åºå¤§å°ï¼åsort_buffer_sizeä¸æ ·ï¼è¯¥åæ°å¯¹åºçåé å åä¹æ¯æ¯è¿æ¥ç¬äº«ã
thread_cache_size = #æå¡å¨çº¿ç¨ç¼åè¿ä¸ªå¼è¡¨ç¤ºå¯ä»¥éæ°å©ç¨ä¿åå¨ç¼åä¸çº¿ç¨çæ°é,å½æå¼è¿æ¥æ¶å¦æç¼åä¸è¿æ空é´,é£ä¹å®¢æ·ç«¯ç线ç¨å°è¢«æ¾å°ç¼åä¸,å¦æ线ç¨éæ°è¢«è¯·æ±ï¼ é£ä¹è¯·æ±å°ä»ç¼åä¸è¯»å,å¦æç¼åä¸æ¯ç©ºçæè æ¯æ°ç请æ±ï¼é£ä¹è¿ä¸ªçº¿ç¨å°è¢«éæ°å建,å¦ææå¾å¤æ°ç线ç¨ï¼å¢å è¿ä¸ªå¼å¯ä»¥æ¹åç³»ç»æ§è½.éè¿æ¯è¾ Connections å Threads_created ç¶æçåéï¼å¯ä»¥çå°è¿ä¸ªåéçä½ç¨
thread_concurrency = 8 #设置thread_concurrencyçå¼çæ£ç¡®ä¸å¦, 对mysqlçæ§è½å½±åå¾å¤§, å¨å¤ä¸ªcpu(æå¤æ ¸)çæ åµä¸ï¼é误设置äºthread_concurrencyçå¼, ä¼å¯¼è´mysqlä¸è½å åå©ç¨å¤cpu(æå¤æ ¸), åºç°åä¸æ¶å»åªè½ä¸ä¸ªcpu(ææ ¸)å¨å·¥ä½çæ åµãthread_concurrencyåºè®¾ä¸ºCPUæ ¸æ°ç2å. æ¯å¦æä¸ä¸ªåæ ¸çCPU, é£ä¹thread_concurrencyçåºè¯¥ä¸º4; 2个åæ ¸çcpu, thread_concurrencyçå¼åºä¸º8ï¼å±éç¹ä¼ååæ°
query_cache_size = 2M #æå®MySQLæ¥è¯¢ç¼å²åºç大å°ï¼å¨æ°æ®åºåå ¥éææ¯æ´æ°éä¹æ¯è¾å¤§çç³»ç»ï¼è¯¥åæ°ä¸éååé è¿å¤§ãèä¸å¨é«å¹¶åï¼åå ¥é大çç³»ç»ï¼å»ºç³»æ该åè½ç¦æã
query_cache_limit = 1M #é»è®¤æ¯4KBï¼è®¾ç½®å¼å¤§å¯¹å¤§æ°æ®æ¥è¯¢æ好å¤ï¼ä½å¦æä½ çæ¥è¯¢é½æ¯å°æ°æ®æ¥è¯¢ï¼å°±å®¹æé æå åç¢çå浪费
query_cache_min_res_unit = 2k #MySQLåæ°ä¸query_cache_min_res_unitæ¥è¯¢ç¼åä¸çåæ¯ä»¥è¿ä¸ªå¤§å°è¿è¡åé çï¼ä½¿ç¨ä¸é¢çå ¬å¼è®¡ç®æ¥è¯¢ç¼åçå¹³å大å°ï¼æ ¹æ®è®¡ç®ç»æ设置è¿ä¸ªåéï¼MySQLå°±ä¼æ´ææå°ä½¿ç¨æ¥è¯¢ç¼åï¼ç¼åæ´å¤çæ¥è¯¢ï¼åå°å åç浪费ã
default_table_type = InnoDB #é»è®¤è¡¨çå¼æ为InnoDB
thread_stack = K #éå®ç¨äºæ¯ä¸ªæ°æ®åºçº¿ç¨çæ 大å°ãé»è®¤è®¾ç½®è¶³ä»¥æ»¡è¶³å¤§å¤æ°åºç¨transaction_isolation = READ-COMMITTED #设å®é»è®¤çäºå¡é离级å«.å¯ç¨ç级å«å¦ä¸:
READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE,1.READ UNCOMMITTED-读æªæ交2.READ COMMITTE-读已æ交3.REPEATABLE READ -å¯éå¤è¯»4.SERIALIZABLE -串è¡
tmp_table_size = M #tmp_table_size çé»è®¤å¤§å°æ¯ Mãå¦æä¸å¼ 临æ¶è¡¨è¶ åºè¯¥å¤§å°ï¼MySQL产çä¸ä¸ª The table tbl_name is full å½¢å¼çé误ï¼å¦æä½ åå¾å¤é«çº§ GROUP BY æ¥è¯¢ï¼å¢å tmp_table_size å¼ã
max_heap_table_size = M #å å表ï¼å å表ä¸æ¯æäºå¡ï¼å å表使ç¨åå¸æ£åç´¢å¼ææ°æ®ä¿åå¨å åä¸ï¼å æ¤å ·ææå¿«çé度ï¼éåç¼åä¸å°åæ°æ®åºï¼ä½æ¯ä½¿ç¨ä¸åå°ä¸äºéå¶
long_query_time = 1 #è®°å½æ¶é´è¶ è¿1ç§çæ¥è¯¢è¯å¥
log_long_format #
log-error = /logs/error.log #å¼å¯mysqlé误æ¥å¿ï¼è¯¥é项æå®mysqldä¿åé误æ¥å¿æ件çä½ç½®
log-slow-queries = /logs/slow.log #æ ¢æ¥è¯¢æ¥å¿æ件路å¾
pid-file = /pids/mysql.pid
log-bin = /binlog/mysql-bin #binlogæ¥å¿ä½ç½®ä»¥åbinlogçå称
relay-log = /relaylog/relay-bin #relaylogæ¥å¿ä½ç½®ä»¥å称
binlog_cache_size = 1M #binlog_cache_size å°±æ¯æ»¡è¶³ä¸¤ç¹çï¼ä¸ä¸ªäºå¡ï¼å¨æ²¡ææ交ï¼uncommittedï¼çæ¶åï¼äº§ççæ¥å¿ï¼è®°å½å°Cacheä¸ï¼çå°äºå¡æ交ï¼committedï¼éè¦æ交çæ¶åï¼åææ¥å¿æä¹ åå°ç£çï¼é»è®¤æ¯Kã
max_binlog_cache_size = M #binlogç¼åæ大使ç¨çå å
max_binlog_size = 2M #ä¸ä¸ªbinlogæ¥å¿ç大å°
expire_logs_days = 7 #ä¿ç7天çbinlog
key_buffer_size = M #ç´¢å¼ç¼å大å°: å®å³å®äºæ°æ®åºç´¢å¼å¤ççé度ï¼å°¤å ¶æ¯ç´¢å¼è¯»çé度
read_buffer_size = M #MySqlè¯»å ¥ç¼å²åºå¤§å°ã对表è¿è¡é¡ºåºæ«æç请æ±å°åé ä¸ä¸ªè¯»å ¥ç¼å²åºï¼MySqlä¼ä¸ºå®åé ä¸æ®µå åç¼å²åºãread_buffer_sizeåéæ§å¶è¿ä¸ç¼å²åºç大å°ãå¦æ对表ç顺åºæ«æ请æ±é常é¢ç¹ï¼å¹¶ä¸ä½ 认为é¢ç¹æ«æè¿è¡å¾å¤ªæ ¢ï¼å¯ä»¥éè¿å¢å 该åéå¼ä»¥åå åç¼å²åºå¤§å°æé«å ¶æ§è½
read_rnd_buffer_size = 2M #MySQLçéæºè¯»ç¼å²åºå¤§å°ãå½æä»»æ顺åºè¯»åè¡æ¶(ä¾å¦ï¼æç §æåºé¡ºåº)ï¼å°åé ä¸ä¸ªéæºè¯»ç¼ååºãè¿è¡æåºæ¥è¯¢æ¶ï¼MySQLä¼é¦å æ«æä¸é该ç¼å²ï¼ä»¥é¿å ç£çæç´¢ï¼æé«æ¥è¯¢é度ï¼å¦æéè¦æåºå¤§éæ°æ®ï¼å¯éå½è°é«è¯¥å¼ãä½MySQLä¼ä¸ºæ¯ä¸ªå®¢æ·è¿æ¥åæ¾è¯¥ç¼å²ç©ºé´ï¼æ以åºå°½ééå½è®¾ç½®è¯¥å¼ï¼ä»¥é¿å å åå¼éè¿å¤§
bulk_insert_buffer_size = 1M #æ¹éæå ¥æ°æ®ç¼å大å°ï¼å¯ä»¥æææé«æå ¥æçï¼é»è®¤ä¸º8M
myisam_sort_buffer_size = 1M #MyISAM表åçååæ¶éæ°æåºæéçç¼å²
myisam_max_sort_file_size = G #MySQLé建索å¼æ¶æå 许çæ大临æ¶æ件çå¤§å° (å½ REPAIR, ALTER TABLE æè LOAD DATA INFILE). å¦ææ件大å°æ¯æ¤å¼æ´å¤§,ç´¢å¼ä¼éè¿é®å¼ç¼å²å建(æ´æ ¢)
myisam_repair_threads = 1 #å¦æä¸ä¸ªè¡¨æ¥æè¶ è¿ä¸ä¸ªç´¢å¼, MyISAM å¯ä»¥éè¿å¹¶è¡æåºä½¿ç¨è¶ è¿ä¸ä¸ªçº¿ç¨å»ä¿®å¤ä»ä»¬.è¿å¯¹äºæ¥æå¤ä¸ªCPU以å大éå åæ åµçç¨æ·,æ¯ä¸ä¸ªå¾å¥½çéæ©.
myisam_recover #èªå¨æ£æ¥åä¿®å¤æ²¡æéå½å ³éç MyISAM 表
lower_case_table_names = 1 #让mysqlä¸åºå大å°å
skip-name-resolve #ç¦ç¨DNS解æï¼è¿æ¥é度ä¼å¿«å¾å¤ãä¸è¿ï¼è¿æ ·çè¯å°±ä¸è½å¨MySQLçææ表ä¸ä½¿ç¨ä¸»æºåäºèåªè½ç¨ipæ ¼å¼ã
#slave-skip-errors = , #è¿æ¯é填项让slaveåºè·³è¿åªäºé误继ç»åæ¥
#replicate-ignore-db=mysql #éå¡«ï¼åæ¥æ¶ååªä¸ªæ°æ®åºä¸åæ¥è®¾ç½®
server-id = 1
innodb_additional_mem_pool_size = 4M #InnoDB åå¨çæ°æ®ç®å½ä¿¡æ¯åå ¶å®å é¨æ°æ®ç»æçå åæ± å¤§å°ãåºç¨ç¨åºéç表è¶å¤ï¼ä½ éè¦å¨è¿éåé è¶å¤çå åï¼é»è®¤æ¯2M
innodb_buffer_pool_size = M #è¿å¯¹Innodb表æ¥è¯´é常éè¦ãInnodbç¸æ¯MyISAM表对ç¼å²æ´ä¸ºææãMyISAMå¯ä»¥å¨é» 认ç key_buffer_size 设置ä¸è¿è¡çå¯ä»¥ï¼ç¶èInnodbå¨é»è®¤ç 设置ä¸å´è·èçä¼¼çãç±äºInnodbææ°æ®åç´¢å¼é½ç¼åèµ·æ¥ï¼æ éçç»æä½ç³»ç»å¤ªå¤çå åï¼å æ¤å¦æåªéè¦ç¨Innodbçè¯åå¯ä»¥è®¾ç½®å®é«è¾¾ -% çå¯ç¨å åãä¸äºåºç¨äº key_buffer çè§åæ â å¦æä½ çæ°æ®éä¸å¤§ï¼å¹¶ä¸ä¸ä¼æ´å¢ï¼é£ä¹æ éæ innodb_buffer_pool_size 设置ç太大äº
innodb_file_io_threads = 4 #æ件IOç线ç¨æ°ï¼ä¸è¬ä¸º 4
innodb_thread_concurrency = 8 #ä½ çæå¡å¨CPUæå 个就设置为å ,建议ç¨é»è®¤ä¸è¬ä¸º8
innodb_flush_log_at_trx_commit = 2 #é»è®¤ä¸º1ï¼å¦æå°æ¤åæ°è®¾ç½®ä¸º1ï¼å°å¨æ¯æ¬¡æ交äºå¡åå°æ¥å¿åå ¥ç£çã为æä¾æ§è½ï¼å¯ä»¥è®¾ç½®ä¸º0æ2ï¼ä½è¦æ¿æ å¨åçæ éæ¶ä¸¢å¤±æ°æ®çé£é©ã设置为0表示äºå¡æ¥å¿åå ¥æ¥å¿æ件ï¼èæ¥å¿æ件æ¯ç§å·æ°å°ç£çä¸æ¬¡ã设置为2表示äºå¡æ¥å¿å°å¨æ交æ¶åå ¥æ¥å¿ï¼ä½æ¥å¿æ件æ¯æ¬¡å·æ°å°ç£çä¸æ¬¡ã
innodb_log_buffer_size = 2M #æ¤åæ°ç¡®å®äºæ¥å¿æ件æç¨çå å大å°ï¼ä»¥M为åä½ãç¼å²åºæ´å¤§è½æé«æ§è½ï¼ä½æå¤çæ éå°ä¼ä¸¢å¤±æ°æ®.MySQLå¼å人å建议设置为1ï¼8Mä¹é´
innodb_log_file_size = 4M #æ¤åæ°ç¡®å®æ°æ®æ¥å¿æ件ç大å°ï¼ä»¥M为åä½ï¼æ´å¤§ç设置å¯ä»¥æé«æ§è½ï¼ä½ä¹ä¼å¢å æ¢å¤æ éæ°æ®åºæéçæ¶é´
innodb_log_files_in_group = 3 #为æé«æ§è½ï¼MySQLå¯ä»¥ä»¥å¾ªç¯æ¹å¼å°æ¥å¿æ件åå°å¤ä¸ªæ件ãæ¨è设置为3M
innodb_max_dirty_pages_pct = #Buffer_Poolä¸Dirty_Pageæå çæ°éï¼ç´æ¥å½±åInnoDBçå ³éæ¶é´ãåæ° innodb_max_dirty_pages_pctå¯ä»¥ç´æ¥æ§å¶äºDirty_Pageå¨Buffer_Poolä¸æå çæ¯çï¼èä¸å¹¸è¿çæ¯ innodb_max_dirty_pages_pctæ¯å¯ä»¥å¨ææ¹åçãæ以ï¼å¨å ³éInnoDBä¹åå è°å°ï¼å¼ºå¶æ°æ®åFlushä¸æ®µæ¶é´ï¼åè½å¤å¤§å¤§ç¼©çMySQLå ³éçæ¶é´ã
innodb_lock_wait_timeout = #InnoDB æå ¶å ç½®çæ»éæ£æµæºå¶ï¼è½å¯¼è´æªå®æçäºå¡åæ»ãä½æ¯ï¼å¦æç»åInnoDB使ç¨MyISAMçlock tables è¯å¥æ第ä¸æ¹äºå¡å¼æ,åInnoDBæ æ³è¯å«æ»éã为æ¶é¤è¿ç§å¯è½æ§ï¼å¯ä»¥å°innodb_lock_wait_timeout设置为ä¸ä¸ªæ´æ°å¼ï¼æ示 MySQLå¨å è®¸å ¶ä»äºå¡ä¿®æ¹é£äºæç»åäºå¡åæ»çæ°æ®ä¹åè¦çå¾ å¤é¿æ¶é´(ç§æ°)
innodb_file_per_table = 0 #ç¬äº«è¡¨ç©ºé´ï¼å ³éï¼
[mysqldump]
quick
max_allowed_packet = M
4. æ¶æä¼å
ï¼1ï¼. å端ç¨memcachedï¼redisçç¼ååæ æ°æ®åºåå
ï¼2ï¼. æ°æ®åºè¯»åå离ï¼è´è½½åè¡¡
ï¼3ï¼. æ°æ®åºååºå表
ï¼4ï¼. åå¨å¯éååå¸å¼
5. åæä¼å
主è¦æ¯å¤è§å¯ï¼åæå°±æ¯ç»´æ¤å·¥ä½äºï¼è§å¯æå¡å¨è´è½½æ¯éè¦æ·»å 硬件äºï¼è¿æ¯æè¯å¥æé®é¢åï¼è¿æ¯åæ°è¦ä¿®æ¹äºã
6. æ¥è¯¢ä¼åï¼ææå«äººçï¼
. 使ç¨æ ¢æ¥è¯¢æ¥å¿å»åç°æ ¢æ¥è¯¢ã
. 使ç¨æ§è¡è®¡åå»å¤ææ¥è¯¢æ¯å¦æ£å¸¸è¿è¡ã
. æ»æ¯å»æµè¯ä½ çæ¥è¯¢ççæ¯å¦ä»ä»¬è¿è¡å¨æä½³ç¶æä¸ âä¹ èä¹ ä¹æ§è½æ»ä¼ååã
. é¿å å¨æ´ä¸ªè¡¨ä¸ä½¿ç¨count(*),å®å¯è½éä½æ´å¼ 表ã
. 使æ¥è¯¢ä¿æä¸è´ä»¥ä¾¿åç»ç¸ä¼¼çæ¥è¯¢å¯ä»¥ä½¿ç¨æ¥è¯¢ç¼åã
. å¨éå½çæ å½¢ä¸ä½¿ç¨GROUP BYèä¸æ¯DISTINCTã
. å¨WHERE, GROUP BYåORDER BYåå¥ä¸ä½¿ç¨æç´¢å¼çåã
. ä¿æç´¢å¼ç®å,ä¸å¨å¤ä¸ªç´¢å¼ä¸å å«åä¸ä¸ªåã
. ææ¶åMySQLä¼ä½¿ç¨é误çç´¢å¼,对äºè¿ç§æ åµä½¿ç¨USE INDEXã
. æ£æ¥ä½¿ç¨SQL_MODE=STRICTçé®é¢ã
. 对äºè®°å½æ°å°äº5çç´¢å¼å段ï¼å¨UNIONçæ¶å使ç¨LIMITä¸æ¯æ¯ç¨OR.
. ä¸ºäº é¿å å¨æ´æ°åSELECTï¼ä½¿ç¨INSERT ON DUPLICATE KEYæè INSERT IGNORE ,ä¸è¦ç¨UPDATEå»å®ç°ã
. ä¸è¦ä½¿ç¨ MAX,使ç¨ç´¢å¼å段åORDER BYåå¥ã
. é¿å 使ç¨ORDER BY RAND().
ãLIMIT Mï¼Nå®é ä¸å¯ä»¥åç¼æ¥è¯¢å¨æäºæ åµä¸ï¼æèå¶å°ä½¿ç¨ã
ãå¨WHEREåå¥ä¸ä½¿ç¨UNION代æ¿åæ¥è¯¢ã
ã对äºUPDATESï¼æ´æ°ï¼ï¼ä½¿ç¨ SHARE MODEï¼å ±äº«æ¨¡å¼ï¼ï¼ä»¥é²æ¢ç¬å éã
ãå¨éæ°å¯å¨çMySQLï¼è®°å¾æ¥æ¸©æä½ çæ°æ®åºï¼ä»¥ç¡®ä¿æ¨çæ°æ®å¨å ååæ¥è¯¢é度快ã
ã使ç¨DROP TABLEï¼CREATE TABLE DELETE FROMä»è¡¨ä¸å é¤æææ°æ®ã
ãæå°åçæ°æ®å¨æ¥è¯¢ä½ éè¦çæ°æ®ï¼ä½¿ç¨*æ¶è大éçæ¶é´ã
ãèèæä¹ è¿æ¥ï¼èä¸æ¯å¤ä¸ªè¿æ¥ï¼ä»¥åå°å¼éã
ãåºåæ¥è¯¢ï¼å æ¬ä½¿ç¨æå¡å¨ä¸çè´è½½ï¼ææ¶ä¸ä¸ªç®åçæ¥è¯¢å¯ä»¥å½±åå ¶ä»æ¥è¯¢ã
ãå½è´è½½å¢å æ¨çæå¡å¨ä¸ï¼ä½¿ç¨SHOW PROCESSLISTæ¥çæ ¢çåæé®é¢çæ¥è¯¢ã
ãå¨å¼åç¯å¢ä¸äº§ççéåæ°æ®ä¸ æµè¯çææå¯ççæ¥è¯¢ã
c库的malloc和free到底是如何实现的?
在使用C语言时,对内存管理的了解是至关重要的。其中,glibc库中的malloc和free函数是内存管理的核心。过去,许多人误以为malloc和free仅仅是glibc与操作系统间的桥梁,应用程序直接通过这些函数申请和释放内存。然而,深入分析glibc源码后,我们发现malloc和free的实现远比表面复杂。在实际应用中,malloc和free的操作实际上是在一个称为内存池(我们暂称为ptmalloc)的内部进行的。
当应用程序调用malloc时,实际上是在ptmalloc中申请内存。ptmalloc内部维护了多个内存池,包括fast bins、small bins、largebins、top chunk、mmaped chunk以及lastremainder chunk。内存的分配和释放操作主要在这几个内存池中进行。只有满足特定条件时,ptmalloc才会调用sys_trim函数,将不再使用的内存块归还给操作系统。
接下来,让我们简要概述一下malloc和free的实现流程。在申请内存时,malloc首先查找合适的内存池,找到空闲内存块后分配给应用程序。释放内存时,free将内存块放回相应的内存池,等待ptmalloc进一步的分配。整个过程中,glibc内部的内存管理机制负责内存的高效管理和回收。
了解malloc和free的内部实现,对优化程序性能和防止内存泄漏至关重要。通过深入研究glibc的内存管理机制,我们可以更好地控制内存使用,提高程序的稳定性和效率。
