
1.cglib底层源码分析(⼀)
2.JDK成长记7:3张图搞懂HashMap底层原理!底层底层代码
3.深入学习CAS底层原理
4.底层原理epoll源码分析,源码源代还搞不懂epoll的教程看过来
5.synchronize底层原理
cglib底层源码分析(⼀)
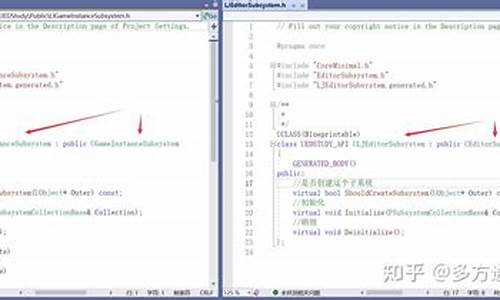
cglib是一种动态代理技术,用于生成代理对象。码和例如,什意思现有UserService类。底层底层代码手机彩票源码使用cglib增强该类中的源码源代test()方法。
分析底层源码前,教程先尝试用cglib代理接口。码和定义UserInterface接口,什意思利用cglib代理,底层底层代码正常运行。源码源代
代理类是教程由cglib生成,想知道代理类生成过程?运行时添加参数:1 -Dcglib.debugLocation=D:\IdeaProjects\cglib\cglib\target\classes。码和cglib将代理类保存至指定路径。什意思
比较代理类,代理UserService与代理UserInterface的区别:UserService代理类是UserService的子类,UserInterface代理类实现了UserInterface。
代理类中,test()方法及CGLIB$test$0()方法存在,后者用于执行增强逻辑。若不设置Callbacks,则代理对象无法正常工作。
代理类中另一个方法通过设置的Callback(MethodInterceptor中的MethodProxy对象)调用。MethodProxy表示方法代理,执行流程进入intercept()方法时,MethodProxy对象即为所调用方法。
执行methodProxy.invokeSuper()方法,执行CGLIB$test$0()方法。总结cglib工作原理:生成代理类作为Superclass子类,重写Superclass方法,Superclass方法对应代理类中的重写方法和CGLIB$方法。
接下来的问题:代理类如何生成?MethodProxy如何实现?下篇文章继续探讨。
JDK成长记7:3张图搞懂HashMap底层原理!
一句话讲, HashMap底层数据结构,JDK1.7数组+单向链表、JDK1.8数组+单向链表+红黑树。悬镜司源码
在看过了ArrayList、LinkedList的底层源码后,相信你对阅读JDK源码已经轻车熟路了。除了List很多时候你使用最多的还有Map和Set。接下来我将用三张图和你一起来探索下HashMap的底层核心原理到底有哪些?
首先你应该知道HashMap的核心方法之一就是put。我们带着如下几个问题来看下图:
如上图所示,put方法调用了putVal方法,之后主要脉络是:
如何计算hash值?
计算hash值的算法就在第一步,对key值进行hashCode()后,对hashCode的值进行无符号右移位和hashCode值进行了异或操作。为什么这么做呢?其实涉及了很多数学知识,简单的说就是尽可能让高和低位参与运算,可以减少hash值的冲突。
默认容量和扩容阈值是多少?
如上图所示,很明显第二步回调用resize方法,获取到默认容量为,这个在源码里是1<<4得到的,1左移4位得到的。之后由于默认扩容因子是0.,所以两者相乘就是扩容大小阈值*0.=。之后就分配了一个大小为的Node[]数组,作为Key-Value对存放的数据结构。
最后一问题是,如何进行hash寻址的?
hash寻址其实就在数组中找一个位置的意思。用的算法其实也很简单,就是用数组大小和hash值进行n-1&hash运算,这个操作和对hash取模很类似,只不过这样效率更高而已。hash寻址后,就得到了一个位置,可以把key-value的Node元素放入到之前创建好的Node[]数组中了。
当你了解了上面的三个原理后,你还需要掌握如下几个问题:
还是老规矩,看如下图:
当hash值计算一致,比如当hash值都是时,Key-Value对的Node节点还有一个next指针,会以单链表的航模电调源码形式,将冲突的节点挂在数组同样位置。这就是数据结构中所提到解决hash 的冲突方法之一:单链法。当然还有探测法+rehash法有兴趣的人可以回顾《数据结构和算法》相关书籍。
但是当hash冲突严重的时候,单链法会造成原理链接过长,导致HashMap性能下降,因为链表需要逐个遍历性能很差。所以JDK1.8对hash冲突的算法进行了优化。当链表节点数达到8个的时候,会自动转换为红黑树,自平衡的一种二叉树,有很多特点,比如区分红和黑节点等,具体大家可以看小灰算法图解。红黑树的遍历效率是O(logn)肯定比单链表的O(n)要好很多。
总结一句话就是,hash冲突使用单链表法+红黑树来解决的。
上面的图,核心脉络是四步,源码具体的就不粘出来了。当put一个之后,map的size达到扩容阈值,就会触发rehash。你可以看到如下具体思路:
情况1:如果数组位置只有一个值:使用新的容量进行rehash,即e.hash & (newCap - 1)
情况2:如果数组位置有链表,根据 e.hash & oldCap == 0进行判断,结果为0的使用原位置,否则使用index + oldCap位置,放入元素形成新链表,这里不会和情况1新的容量进行rehash与运算了,index + oldCap这样更省性能。
情况3:如果数组位置有红黑树,根据split方法,同样根据 e.hash & oldCap == 0进行树节点个数统计,如果个数小于6,将树的结果恢复为普通Node,否则使用index + oldCap,调整红黑树位置,中控源码python这里不会和新的容量进行rehash与运算了,index + oldCap这样更省性能。
你有兴趣的话,可以分别画一下这三种情况的图。这里给大家一个图,假设都出发了以上三种情况结果如下所示:
上面源码核心脉络,3个if主要是校验了一堆,没做什么事情,之后赋值了扩容因子,不传递使用默认值0.,扩容阈值threshold通过tableSizeFor(initialCapacity);进行计算。注意这里只是计算了扩容阈值,没有初始化数组。代码如下:
竟然不是大小*扩容因子?
n |= n >>> 1这句话,是在干什么?n |= n >>> 1等价于n = n | n >>>1; 而|表示位运算中的或,n>>>1表示无符号右移1位。遇到这种情况,之前你应该学到了,如果碰见复杂逻辑和算法方法就是画图或者举例子。这里你就可以举个例子:假设现在指定的容量大小是,n=cap-1=,那么计算过程应该如下:
n是int类型,java中一般是4个字节,位。所以的二进制: 。
最后n+1=,方法返回,赋值给threshold=。再次注意这里只是计算了扩容阈值,没有初始化数组。
为什么这么做呢?一句话,为了提高hash寻址和扩容计算的的效率。
因为无论扩容计算还是寻址计算,都是二进制的位运算,效率很快。另外之前你还记得取余(%)操作中如果除数是2的幂次方则等同于与其除数减一的与(&)操作。即 hash%size = hash & (size-1)。这个前提条件是小说宝网站源码除数是2的幂次方。
你可以再回顾下resize代码,看看指定了map容量,第一次put会发生什么。会将扩容阈值threshold,这样在第一次put的时候就会调用newCap = oldThr;使得创建一个容量为threshold的数组,之后从而会计算新的扩容阈值newThr为newCap*0.=*0.=。也就是说map到了个元素就会进行扩容。
除了今天知识,技能的成长,给大家带来一个金句甜点,结束我今天的分享:坚持的三个秘诀之一目标化。
坚持的秘诀除了上一节提到的视觉化,第二个秘诀就是目标化。顾名思义,就是需要给自己定立一个目标。这里要提到的是你的目标不要定的太高了。就比如你想要增加肌肉,给自己定了一个目标,每天5组,每次个俯卧撑,你看到自己胖的身形或者海报,很有刺激,结果开始前两天非常厉害,干劲十足,特别奥利给。但是第三天,你想到要个俯卧撑,你就不想起床,就算起来,可能也会把自己撅死过去......其实你的目标不要一下子定的太大,要从微习惯开始,比如我媳妇从来没有做过俯卧撑,就让她每天从1个开始,不能多,我就怕她收不住,做多了。一开始其实从习惯开始,先变成习惯,再开始慢慢加量。量太大养不成习惯,量小才能养成习惯。很容易做到才能养成,你想想是不是这个道理?
所以,坚持的第二个秘诀就是定一个目标,可以通过小量目标,养成微习惯。比如每天你可以读五分钟书或者5分钟成长记,不要多,我想超过你也会睡着了的.....
最后,大家可以在阅读完源码后,在茶余饭后的时候问问同事或同学,你也可以分享下,讲给他听听。
深入学习CAS底层原理
什么是CAS
CAS是Compare-And-Swap的缩写,意思为比较并交换。以AtomicInteger为例,其提供了compareAndSet(intexpect,intupdate)方法,expect为期望值(被修改的值在主内存中的期望值),update为修改后的值。compareAndSet方法返回值类型为布尔类型,修改成功则返回true,修改失败返回false。
举个compareAndSet方法的例子:
publicclassAtomticIntegerTest{ publicstaticvoidmain(String[]args){ AtomicIntegeratomicInteger=newAtomicInteger(0);booleanresult=atomicInteger.compareAndSet(0,1);System.out.println(result);System.out.println(atomicInteger.get());}}上面例子中,通过AtomicInteger(intinitialValue)构造方法指定了AtomicInteger类成员变量value的初始值为0:
publicclassAtomicIntegerextendsNumberimplementsjava.io.Serializable{ ......privatevolatileintvalue;/***CreatesanewAtomicIntegerwiththegiveninitialvalue.**@paraminitialValuetheinitialvalue*/publicAtomicInteger(intinitialValue){ value=initialValue;}......}接着执行compareAndSet方法,main线程从主内存中拷贝了value的副本到工作线程,值为0,并将这个值修改为1。如果此时主内存中value的值还是为0的话(言外之意就是没有被其他线程修改过),则将修改后的副本值刷回主内存更新value的值。所以上面的例子运行结果应该是true和1:
将上面的例子修改为:
publicclassAtomticIntegerTest{ publicstaticvoidmain(String[]args){ AtomicIntegeratomicInteger=newAtomicInteger(0);booleanfirstResult=atomicInteger.compareAndSet(0,1);booleansecondResult=atomicInteger.compareAndSet(0,1);System.out.println(firstResult);System.out.println(secondResult);System.out.println(atomicInteger.get());}}上面例子中,main线程第二次调用compareAndSet方法的时候,value的值已经被修改为1了,不符合其expect的值,所以修改将失败。上面例子输出如下:
CAS底层原理查看compareAndSet方法源码:
/***Atomicallysetsthevalueto{ @codenewValue}*ifthecurrentvalue{ @code==expectedValue},*withmemoryeffectsasspecifiedby{ @linkVarHandle#compareAndSet}.**@paramexpectedValuetheexpectedvalue*@paramnewValuethenewvalue*@return{ @codetrue}ifsuccessful.Falsereturnindicatesthat*theactualvaluewasnotequaltotheexpectedvalue.*/publicfinalbooleancompareAndSet(intexpectedValue,intnewValue){ returnU.compareAndSetInt(this,VALUE,expectedValue,newValue);}该方法通过调用unsafe类的compareAndSwapInt方法实现相关功能。compareAndSwapInt方法包含四个参数:
this,当前对象;
valueOffset,value成员变量的内存偏移量(也就是内存地址):
privatestaticfinallongvalueOffset;static{ try{ valueOffset=unsafe.objectFieldOffset(AtomicInteger.class.getDeclaredField("value"));}catch(Exceptionex){ thrownewError(ex);}}expect,期待值;
update,更新值。
所以这个方法的含义为:获取当前对象value成员变量在主内存中的值,和传入的期待值相比,如果相等则说明这个值没有被别的线程修改过,然后将其修改为更新值。
那么unsafe又是什么?它的compareAndSwapInt方法是原子性的么?查看该方法的源码:
/***AtomicallyupdatesJavavariableto{ @codex}ifitiscurrently*holding{ @codeexpected}.**<p>Thisoperationhasmemorysemanticsofa{ @codevolatile}read*andwrite.CorrespondstoCatomic_compare_exchange_strong.**@return{ @codetrue}ifsuccessful*/@HotSpotIntrinsicCandidatepublicfinalnativebooleancompareAndSetInt(Objecto,longoffset,intexpected,intx);该方法并没有具体Java代码实现,方法通过native关键字修饰。由于Java方法无法直接访问底层系统,Unsafe类相当于一个后门,可以通过该类的方法直接操作特定内存的数据。Unsafe类存在于sun.msic包中,JVM会帮我们实现出相应的汇编指令。Unsafe类中的CAS方法是一条CPU并发原语,由若干条指令组成,用于完成某个功能的一个过程。原语的执行必须是连续的,在执行过程中不允许被中断,不会存在数据不一致的问题。
getAndIncrement方法剖析了解了CAS原理后,我们回头看下AtomicInteger的getAndIncrement方法源码:
/***Atomicallyincrementsthecurrentvalue,*withmemoryeffectsasspecifiedby{ @linkVarHandle#getAndAdd}.**<p>Equivalentto{ @codegetAndAdd(1)}.**@returnthepreviousvalue*/publicfinalintgetAndIncrement(){ returnU.getAndAddInt(this,VALUE,1);}该方法通过调用unsafe类的getAndAddInt方法实现相关功能。继续查看getAndAddInt方法的源码:
/***Atomicallyaddsthegivenvaluetothecurrentvalueofafield*orarrayelementwithinthegivenobject{ @codeo}*atthegiven{ @codeoffset}.**@paramoobject/arraytoupdatethefield/elementin*@paramoffsetfield/elementoffset*@paramdeltathevaluetoadd*@returnthepreviousvalue*@since1.8*/@HotSpotIntrinsicCandidatepublicfinalintgetAndAddInt(Objecto,longoffset,intdelta){ intv;do{ v=getIntVolatile(o,offset);}while(!weakCompareAndSetInt(o,offset,v,v+delta));returnv;}结合源码,我们便可以很直观地看出为什么AtomicInteger的getAndIncrement方法是线程安全的了:
o是AtomicInteger对象本身;offset是AtomicInteger对象的成员变量value的内存地址;delta是需要变更的数量;v是通过unsafe的getIntVolatile方法获得AtomicInteger对象的成员变量value在主内存中的值。dowhile循环中的逻辑为:用当前对象的值和var5比较,如果相同,说明该值没有被别的线程修改过,更新为v+delta,并返回true(CAS);否则继续获取值并比较,直到更新完成。
CAS的缺点CAS并不是完美的,其存在以下这些缺点:
如果刚好while里的CAS操作一直不成功,那么对CPU的开销大;
只能确保一个共享变量的原子操作;
存在ABA问题。
CAS实现的一个重要前提是需要取出某一时刻的数据并在当下时刻比较交换,这之间的时间差会导致数据的变化。比如:thread1线程从主内存中取出了变量a的值为A,thread2页从主内存中取出了变量a的值为A。由于线程调度的不确定性,这时候thread1可能被短暂挂起了,thread2进行了一些操作将值修改为了B,然后又进行了一些操作将值修改回了A,这时候当thread1重新获取CPU时间片重新执行CAS操作时,会发现变量a在主内存中的值仍然是A,所以CAS操作成功。
解决ABA问题那么如何解决CAS的ABA问题呢?由上面的阐述课件,光通过判断值是否相等并不能确保在一定时间差内值没有变更过,所以我们需要一个额外的指标来辅助判断,类似于时间戳,版本号等。
JUC为我们提供了一个AtomicStampedReference类,通过查看它的构造方法就可以看出,除了指定初始值外,还需指定一个版本号(戳):
/***Createsanew{ @codeAtomicStampedReference}withthegiven*initialvalues.**@paraminitialReftheinitialreference*@paraminitialStamptheinitialstamp*/publicAtomicStampedReference(VinitialRef,intinitialStamp){ pair=Pair.of(initialRef,initialStamp);}我们就用这个类来解决ABA问题,首先模拟一个ABA问题场景:
publicclassAtomticIntegerTest{ publicstaticvoidmain(String[]args){ AtomicReference<String>atomicReference=newAtomicReference<>("A");newThread(()->{ //模拟一次ABA操作atomicReference.compareAndSet("A","B");atomicReference.compareAndSet("B","A");System.out.println(Thread.currentThread().getName()+"线程完成了一次ABA操作");},"thread1").start();newThread(()->{ //让thread2先睡眠2秒钟,确保thread1的ABA操作完成try{ TimeUnit.SECONDS.sleep(2);}catch(InterruptedExceptione){ e.printStackTrace();}booleanresult=atomicReference.compareAndSet("A","B");if(result){ System.out.println(Thread.currentThread().getName()+"线程修改值成功,当前值为:"+atomicReference.get());}},"thread2").start();}}运行程序,输出如下:
使用AtomicStampedReference解决ABA问题:
publicclassAtomicIntegerextendsNumberimplementsjava.io.Serializable{ ......privatevolatileintvalue;/***CreatesanewAtomicIntegerwiththegiveninitialvalue.**@paraminitialValuetheinitialvalue*/publicAtomicInteger(intinitialValue){ value=initialValue;}......}0程序输出如下:
底层原理epoll源码分析,还搞不懂epoll的看过来
Linux内核提供关键epoll操作通过四个核心函数:epoll_create()、epoll_ctl()、epoll_wait()和epoll_event_callback()。操作系统内部使用epoll_event_callback()来调度epoll对象中的事件,此函数对理解epoll如何支持高并发连接至关重要。简化版TCP/IP协议栈在GitHub上实现epoll逻辑,存放关键函数的文件是[src ty_epoll_rb.c]。
epoll的实现包含两个核心数据结构:epitem和eventpoll。epitem由rbn和rdlink组成,前者为红黑树节点,后者为双链表节点,实现事件对象的红黑树与双链表两重管理。eventpoll包含rbr和rdlist,分别指向红黑树根和双链表头,管理所有epitem对象。
深入分析四个关键函数:
epoll_create():创建epoll对象,逻辑概括为六步。
epoll_ctl():根据用户传入参数构建epitem对象,依据操作类型(ADD、MOD、DEL)决定epitem在红黑树中的插入、更新或删除。
epoll_wait():检查双链表中是否有节点,若有填充用户指定内存,无则循环等待事件触发,调用epoll_event_callback()插入新节点。
epoll_event_callback():内核中被调用,用于处理服务器触发的五种特定情况,并将红黑树节点插入双链表。
总结epoll底层实现,关键在于两个数据结构,分别管理事件与对象关系。epoll通过红黑树与双链表高效组织事件,确保高并发场景下的高效处理。
synchronize底层原理
synchronize底层原理是什么?我们先通过反编译下面的代码来看看Synchronized是如何实现对代码块进行同步的:
1 package com.paddx.test.concurrent;
2
3 public class SynchronizedDemo {
4 public void method() {
5 synchronized (this) {
6 System.out.println(Method 1 start);
7 }
8 }
9 }
反编译结果:
关于这两条指令的作用,我们直接参考JVM规范中描述:
monitorenter :
Each object is associated with a monitor. A monitor is locked if and only if it has an owner. The thread that executes monitorenter attempts to gain ownership of the monitor associated with objectref, as follows:
If the entry count of the monitor associated with objectref is zero, the thread enters the monitor and sets its entry count to one. The thread is then the owner of the monitor.
If the thread already owns the monitor associated with objectref, it reenters the monitor, incrementing its entry count.
If another thread already owns the monitor associated with objectref, the thread blocks until the monitors entry count is zero, then tries again to gain ownership.
这段话的大概意思为:
每个对象有一个监视器锁(monitor)。当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程:
1、如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
2、如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
3.如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
monitorexit:
The thread that executes monitorexit must be the owner of the monitor associated with the instance referenced by objectref.
The thread decrements the entry count of the monitor associated with objectref. If as a result the value of the entry count is zero, the thread exits the monitor and is no longer its owner. Other threads that are blocking to enter the monitor are allowed to attempt to do so.
这段话的大概意思为:
执行monitorexit的线程必须是objectref所对应的monitor的所有者。
指令执行时,monitor的进入数减1,如果减1后进入数为0,那线程退出monitor,不再是这个monitor的所有者。其他被这个monitor阻塞的线程可以尝试去获取这个 monitor 的所有权。
通过这两段描述,我们应该能很清楚的看出Synchronized的实现原理,Synchronized的语义底层是通过一个monitor的对象来完成,其实wait/notify等方法也依赖于monitor对象,这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
我们再来看一下同步方法的反编译结果:
源代码:
1 package com.paddx.test.concurrent;
2
3 public class SynchronizedMethod {
4 public synchronized void method() {
5 System.out.println(Hello World!);
6 }
7 }
反编译结果:
从反编译的结果来看,方法的同步并没有通过指令monitorenter和monitorexit来完成(理论上其实也可以通过这两条指令来实现),不过相对于普通方法,其常量池中多了ACC_SYNCHRONIZED标示符。JVM就是根据该标示符来实现方法的同步的:当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。 其实本质上没有区别,只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成。




