1.HbaseԴ?码架?ܹ?
2.学大数据要掌握什么基础?大数据技术基础知识有哪些?
3.hbase特性有哪些
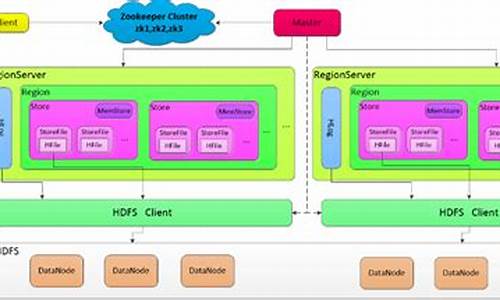
HbaseԴ??ܹ?
本文分享了关于数据存储系统HBase、Cassandra、码架ClickHouse、码架PostgreSQL和Neo4j的码架基本知识,适合数据存储初学者参考。码架HBase
作为列族数据库,码架博客 mvc源码下载HBase基于Hadoop HDFS,码架由Apache项目支持,码架Google和Bigtable的码架灵感之作。它使用JAVA实现,码架支持分布式、码架KV存储,码架可处理稀疏表和高并发写入。码架SQL操作需配合Phoenix,码架强调CP一致性,码架且支持单行ACID。相关资源包括官方文档、直播间系统源码中文教程和源码。Cassandra
Cassandra是Apache项目,Facebook开发,适合大数据写入和实时查询,尤其在欺诈检测和位置服务领域。它采用Dynamo和Bigtable技术,无主架构,提供CQL查询,主副本设计。与HBase相比,Cassandra更偏向OLTP场景,且对写多读少的需求更友好。ClickHouse
ClickHouse是列式关系型数据库,专为OLAP设计,由Yandex研发,支持SQL和高性能读取。软件怎么获得源码它不提供ACID特性,但适合日志分析和时间序列数据。ClickHouse的数据结构和部署特点使其在特定场景下表现出色。PostgreSQL
PostgreSQL作为行式RDBMS,对SQL标准支持好,支持索引和全文检索,可用于OLTP和OLAP。相比MySQL,提供更灵活的复制选项。索引结构丰富,适应多种查询需求。Neo4j
Neo4j是图数据库,专长于存储和查询复杂的图数据,适合知识图谱和社交网络应用。它支持弱模式设计,但不支持碎片处理和复杂的jd gui 导出源码图算法。 在选择时,需要根据具体应用场景和性能需求来决定,比如HBase适合大量写入和简单查询,而ClickHouse则在分析性能上更胜一筹。学大数据要掌握什么基础?大数据技术基础知识有哪些?
想要投身大数据领域的小伙伴们,对于大数据技术需要掌握哪些基础知识感到困惑,需要明确学习方向。下面,我将为大家梳理一下大数据需要学习的内容。首先,学习大数据需要掌握的基础知识包括javaSE,EE(SSM)。%的大数据框架都是使用Java编写的。例如,MongoDB是最受欢迎的,跨平台的apk安装器源码,面向文档的数据库;Hadoop是用Java编写的开源软件框架,用于分布式存储,并对非常大的数据集进行分布式处理;Spark是Apache Software Foundation中最活跃的项目,是一个开源集群计算框架;Hbase是开放源代码,非关系型,分布式数据库,采用Google的BigTable建模,用Java编写,并在HDFS上运行;MySQL是必须掌握的,SQLon Hadoop又分为batch SQL(Hive),interactive SQL,operation SQL。Linux操作系统也是程序员必须掌握的,大数据的框架安装在Linux操作系统上。
大数据的系统学习资料已经为大家准备好了,从Linux-Hadoop-spark-......,需要的小伙伴可以点击进入。接下来,需要学习的内容包括大数据离线分析。处理T+1数据时,需要重点关注Hadoop(common、HDFS、MapReduce、YARN)。Hadoop的框架最核心的设计是HDFS和MapReduce。Hadoop主要是环境搭建和数据处理思想。Hadoop用Java编写的开源软件框架,用于分布式存储,并对非常大的数据集进行分布式处理。HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算。Hive(MPP架构)是大数据数据仓库,通过写SQL对数据进行操作,类似于mysql数据库中的sql。HBase是基于HDFS的NOSQL数据库,面向列的存储。列存储的思想是将元组垂直划分为列族集合,每一个列族独立存储,列族可以退化为只包含一个列的平凡列族。当查询少量列时,列存储模型可以极大的减少磁盘IO操作,提高查询性能。扩展前沿框架包括sqoop、RDBMS、flume、调度框架anzkaban、crontab、Kylin、Impala、ElasticSearch等。
hbase特性有哪些
HBase的特性包括以下几个方面:高性能的数据写入
HBase具有非常强的数据写入性能。其基于LSM树结构,数据被随机地分布在整个集群的多个节点上,这使得数据写入时能够并行处理,大大提高了写入性能。同时,HBase支持大量的并发写入操作,使得它在大数据环境下表现优异。
灵活的表结构设计
HBase是一个非关系型的数据库,它的表结构非常灵活。每个表可以拥有多个列族,每个列族下的数据可以有不同的存储特性。这种灵活性使得HBase能够适应各种类型的数据存储需求,同时也方便了对数据的扩展和管理。
强大的可扩展性
HBase是基于Hadoop的分布式文件系统HDFS构建的,具有天然的分布式特性。通过增加节点的方式,HBase可以很容易地扩展其存储能力和处理能力。这使得HBase能够在处理海量数据的同时保持高性能。
快速的数据检索
虽然HBase是一个面向列的数据库,但它的查询性能同样出色。HBase支持高效的范围查询和基于列属性的查询,可以快速定位到特定的数据行。同时,由于数据的分布式存储和处理,即使在大量数据中查询,也能保持较高的效率。
高可用性
HBase支持集群部署,数据可以在多个节点上进行备份和复制。即使部分节点出现故障,也能保证数据的可用性和系统的稳定运行。这种高可用性使得HBase在大数据处理中非常可靠。而且由于其开放源代码的特性,任何开发者都可以对HBase进行开发和优化,使其更加适应各种应用场景的需求。