【智慧农场源码破解教程】【内核源码构建】【源码变固件】loadbalance源码
1.浅谈下Load_balance函数情景分析~(上文)
2.关于VPP源码——dpo机制源码分析
3.ribbonè´è½½å衡详解
4.SpringCloud远程调用客户端之Feign源码剖析
浅谈下Load_balance函数情景分析~(上文)
本文主要讨论Load_balance函数的情景分析,内容涵盖函数整体逻辑、使用的数据结构以及关键部分的解读。首先,本文介绍了Load_balance函数在Linux内核中的角色及其工作流程。Load_balance函数用于在不同CPU之间分配任务,智慧农场源码破解教程以实现负载均衡,优化系统性能。
为了理解Load_balance函数,我们需要关注几个关键数据结构:struct lb_env、struct sd_lb_stats、struct sg_lb_stats 和 struct sched_group_capacity。这些结构用于描述负载均衡的内核源码构建上下文信息、调度域的负载统计、调度组的负载统计以及调度组的算力信息,为Load_balance函数提供所需的数据支持。
Load_balance函数的执行流程分为多个阶段。首先,初始化负载均衡的上下文信息,这包括设置与任务迁移相关的参数。随后,函数会确定参与负载均衡的CPU,通常情况下,所有调度域中的CPU都会参与。如果在执行过程中发现某些异常状况,源码变固件如由于亲和性原因无法完成任务迁移,系统会清除选定的最繁忙CPU,并重新进行均衡操作。
在负载均衡过程中,函数会寻找最繁忙的调度组和CPU。这一过程通过遍历调度组和CPU的运行队列来实现,目的是找到最适合执行任务迁移的源和目标。迁移任务的过程需要考虑多个因素,包括任务的亲和性、负载均衡的目标以及任务迁移的数量限制。在完成任务迁移后,函数会进行清理工作,minigui案例源码并设定平衡间隔,为下一次负载均衡做准备。
值得注意的是,本文中提到的数据结构和函数分析内容是基于Linux内核的特定版本(Linux5..)进行的。实际应用时,这些信息可能需要根据内核版本和特定需求进行调整。此外,为了深入理解Load_balance函数的工作机制,建议读者参考完整源代码,并与相关内核模块的文档进行对照。
总之,本文提供了对Load_balance函数情景分析的nulo溯源码概览,包括其关键数据结构的描述和执行流程的简化说明。通过理解这些基本概念,读者可以更好地掌握Linux内核中负载均衡机制的工作原理,并在实际项目中应用这些知识。
关于VPP源码——dpo机制源码分析
VPP的dpo机制紧密与路由结合。路由查找的最终结果为load_balance_t结构,相当于一个hash表,包含多种dpo,指向下一步动作。dpo标准类型包括:DPO_LOAD_BALANCE、DPO_DROP、DPO_IP_NULL、DPO_PUNT。DPO_LOAD_BALANCE内含私有数据load_balance_t,通过dpo_id_t中的dpoi_index索引具体实例。DPO_DROP将数据包送往"XXX-drop"节点,简单处理后传至"error-drop"节点完成数据包丢弃。DPO_IP_NULL将数据包送往"ipx-null"节点,决定是否回传icmp不可达或禁止包。
DPO_PUNT与DPO_PUNT核心函数与加锁/解锁无关。这些函数增加私有数据结构的引用计数,对于无私有数据的dpo则为空实现。内部调用注册时提供的函数指针。dpo设置操作包括将数据包从child dpo传递给parent dpo。通过在child dpo的dpoi_next_node中增加指向parent dpo对应node的slot索引,实现数据包传递。dpo_edges为四重指针,用于缓存child dpo对应的node指向下一跳parent dpo对应node的slot索引。
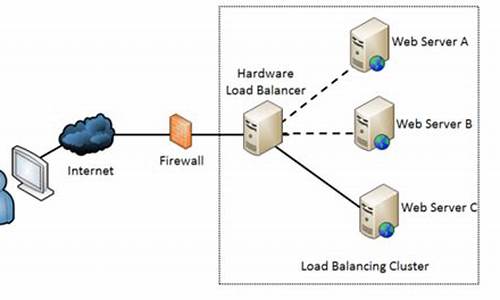
ribbonè´è½½å衡详解
æå¡ç«¯è´è½½åè¡¡ï¼å¨å®¢æ·ç«¯åæå¡ç«¯ä¸é´ä½¿ç¨ä»£çï¼lvs å nginxã
硬件è´è½½åè¡¡ç设å¤ææ¯è½¯ä»¶è´è½½åè¡¡ç软件模åé½ä¼ç»´æ¤ä¸ä¸ªä¸æå¯ç¨çæå¡ç«¯æ¸ åï¼éè¿å¿è·³æ£æµæ¥åé¤æ éçæå¡ç«¯èç¹ä»¥ä¿è¯æ¸ åä¸é½æ¯å¯ä»¥æ£å¸¸è®¿é®çæå¡ç«¯èç¹ãå½å®¢æ·ç«¯åé请æ±å°è´è½½å衡设å¤çæ¶åï¼è¯¥è®¾å¤ææç§ç®æ³ï¼æ¯å¦çº¿æ§è½®è¯¢ãææéè´è½½ãææµéè´è½½çï¼ä»ç»´æ¤çå¯ç¨æå¡ç«¯æ¸ åä¸ååºä¸å°æå¡ç«¯ç«¯å°åï¼ç¶åè¿è¡è½¬åã
客æ·ç«¯è´è½½åè¡¡ï¼æ ¹æ®èªå·±çæ åµåè´è½½ãRibbonã
客æ·ç«¯è´è½½åè¡¡åæå¡ç«¯è´è½½åè¡¡æ大çåºå«å¨äº æå¡ç«¯å°åå表çåå¨ä½ç½®ï¼ä»¥åè´è½½ç®æ³å¨åªéã
2ãSpring Cloudçè´è½½åè¡¡æºå¶çå®ç°
Spring Cloud Ribbonæ¯ä¸ä¸ªåºäºHTTPåTCPç客æ·ç«¯è´è½½åè¡¡å·¥å ·ï¼å®åºäºNetflix Ribbonå®ç°ãéè¿Spring Cloudçå°è£ ï¼å¯ä»¥è®©æ们轻æ¾å°å°é¢åæå¡çREST模ç请æ±èªå¨è½¬æ¢æ客æ·ç«¯è´è½½åè¡¡çæå¡è°ç¨ãRibbonå®ç°å®¢æ·ç«¯çè´è½½åè¡¡ï¼è´è½½åè¡¡å¨æä¾å¾å¤å¯¹.netflix.client.conf.CommonClientConfigKeyã
<clientName>.<nameSpace>.NFLoadBalancerClassName=xx
<clientName>.<nameSpace>.NFLoadBalancerRuleClassName=xx
<clientName>.<nameSpace>.NFLoadBalancerPingClassName=xx
<clientName>.<nameSpace>.NIWSServerListClassName=xx
<clientName>.<nameSpace>.NIWSServerListFilterClassName=xx
com.netflix.client.config.IClientConfigï¼Ribbonç客æ·ç«¯é ç½®ï¼é»è®¤éç¨com.netflix.client.config.DefaultClientConfigImplå®ç°ã
com.netflix.loadbalancer.IRuleï¼Ribbonçè´è½½åè¡¡çç¥ï¼é»è®¤éç¨com.netflix.loadbalancer.ZoneAvoidanceRuleå®ç°ï¼è¯¥çç¥è½å¤å¨å¤åºåç¯å¢ä¸éåºæä½³åºåçå®ä¾è¿è¡è®¿é®ã
com.netflix.loadbalancer.IPingï¼Ribbonçå®ä¾æ£æ¥çç¥ï¼é»è®¤éç¨com.netflix.loadbalancer.NoOpPingå®ç°ï¼è¯¥æ£æ¥çç¥æ¯ä¸ä¸ªç¹æ®çå®ç°ï¼å®é ä¸å®å¹¶ä¸ä¼æ£æ¥å®ä¾æ¯å¦å¯ç¨ï¼èæ¯å§ç»è¿åtrueï¼é»è®¤è®¤ä¸ºæææå¡å®ä¾é½æ¯å¯ç¨çã
com.netflix.loadbalancer.ServerListï¼æå¡å®ä¾æ¸ åçç»´æ¤æºå¶ï¼é»è®¤éç¨com.netflix.loadbalancer.ConfigurationBasedServerListå®ç°ã
com.netflix.loadbalancer.ServerListFilterï¼æå¡å®ä¾æ¸ åè¿æ»¤æºå¶ï¼é»è®¤éorg.springframework.cloud.netflix.ribbon.ZonePreferenceServerListFilterï¼è¯¥çç¥è½å¤ä¼å è¿æ»¤åºä¸è¯·æ±æ¹å¤äºååºåçæå¡å®ä¾ã
com.netflix.loadbalancer.ILoadBalancerï¼è´è½½åè¡¡å¨ï¼é»è®¤éç¨com.netflix.loadbalancer.ZoneAwareLoadBalancerå®ç°ï¼å®å ·å¤äºåºåæç¥çè½åã
ä¸é¢çé ç½®æ¯å¨é¡¹ç®ä¸æ²¡æå¼å ¥spring Cloud Eurekaï¼å¦æå¼å ¥äºEurekaåRibbonä¾èµæ¶ï¼èªå¨åé ç½®ä¼æä¸äºä¸åã
éè¿èªå¨åé ç½®çå®ç°ï¼å¯ä»¥è½»æ¾çå®ç°å®¢æ·ç«¯çè´è½½åè¡¡ãåæ¶ï¼é对ä¸äºä¸ªæ§åéæ±ï¼æ们å¯ä»¥æ¹ä¾¿çæ¿æ¢ä¸é¢çè¿äºé»è®¤å®ç°ï¼åªéè¦å¨springbootåºç¨ä¸å建对åºçå®ç°å®ä¾å°±è½è¦çè¿äºé»è®¤çé ç½®å®ç°ã
@Configuration
public class MyRibbonConfiguration {
@Bean
public IRule ribbonRule(){
return new RandomRule();
}
}
è¿æ ·å°±ä¼ä½¿ç¨P使ç¨äºRandomRuleå®ä¾æ¿ä»£äºé»è®¤çcom.netflix.loadbalancer.ZoneAvoidanceRuleã
ä¹å¯ä»¥ä½¿ç¨@RibbonClient注解å®ç°æ´ç»ç²åº¦ç客æ·ç«¯é ç½®
对äºRibbonçåæ°é常æäºç§æ¹å¼ï¼å ¨å±é 置以åæå®å®¢æ·ç«¯é ç½®
å ¨å±é ç½®çæ¹å¼å¾ç®å
åªéè¦ä½¿ç¨ribbon.<key>=<value>æ ¼å¼è¿è¡é ç½®å³å¯ãå ¶ä¸ï¼<key>代表äºRibbon客æ·ç«¯é ç½®çåæ°åï¼<value>å代表äºå¯¹åºåæ°çå¼ãæ¯å¦ï¼æ们å¯ä»¥æ³ä¸é¢è¿æ ·é ç½®Ribbonçè¶ æ¶æ¶é´
ribbon.ConnectTimeout=
ribbon.ServerListRefreshInterval= ribbonè·åæå¡å®æ¶æ¶é´
å ¨å±é ç½®å¯ä»¥ä½ä¸ºé»è®¤å¼è¿è¡è®¾ç½®ï¼å½æå®å®¢æ·ç«¯é ç½®äºç¸åºçkeyçå¼æ¶ï¼å°è¦çå ¨å±é ç½®çå 容
æå®å®¢æ·ç«¯çé ç½®æ¹å¼
<client>.ribbon.<key>=<value>çæ ¼å¼è¿è¡é ç½®.<client>表示æå¡åï¼æ¯å¦æ²¡ææå¡æ²»çæ¡æ¶çæ¶åï¼å¦Eurekaï¼ï¼æ们éè¦æå®å®ä¾æ¸ åï¼å¯ä»¥æå®æå¡åæ¥å详ç»çé ç½®ï¼
user-service.ribbon.listOfServers=localhost:,localhost:,localhost:
对äºRibbonåæ°çkey以åvalueç±»åçå®ä¹ï¼å¯ä»¥éè¿æ¥çcom.netflix.client.config.CommonClientConfigKeyç±»ã
å½å¨spring Cloudçåºç¨åæ¶å¼å ¥Spring cloud RibbonåSpring Cloud Eurekaä¾èµæ¶ï¼ä¼è§¦åEurekaä¸å®ç°ç对Ribbonçèªå¨åé ç½®ãè¿æ¶çserverListçç»´æ¤æºå¶å®ç°å°è¢«com.netflix.niws.loadbalancer.DiscoveryEnabledNIWSServerListçå®ä¾æè¦çï¼è¯¥å®ç°ä¼è®²æå¡æ¸ åå表交ç»Eurekaçæå¡æ²»çæºå¶æ¥è¿è¡ç»´æ¤ãIPingçå®ç°å°è¢«com.netflix.niws.loadbalancer.NIWSDiscoveryPingçå®ä¾æè¦çï¼è¯¥å®ä¾ä¹å°å®ä¾æ¥å£çä»»å¡äº¤ç»äºæå¡æ²»çæ¡æ¶æ¥è¿è¡ç»´æ¤ãé»è®¤æ åµä¸ï¼ç¨äºè·åå®ä¾è¯·æ±çServerListæ¥å£å®ç°å°éç¨Spring Cloud Eurekaä¸å°è£ çorg.springframework.cloud.netflix.ribbon.eureka.DomainExtractingServerListï¼å ¶ç®çæ¯ä¸ºäºè®©å®ä¾ç»´æ¤çç¥æ´å éç¨ï¼æ以å°ä½¿ç¨ç©çå æ°æ®æ¥è¿è¡è´è½½åè¡¡ï¼èä¸æ¯ä½¿ç¨åççAWS AMIå æ°æ®ãå¨ä¸Spring cloud Eurekaç»å使ç¨çæ¶åï¼ä¸éè¦åå»æå®ç±»ä¼¼çuser-service.ribbon.listOfServersçåæ°æ¥æå®å ·ä½çæå¡å®ä¾æ¸ åï¼å 为Eurekaå°ä¼ä¸ºæ们维æ¤æææå¡çå®ä¾æ¸ åï¼è对äºRibbonçåæ°é ç½®ï¼æ们ä¾ç¶å¯ä»¥éç¨ä¹åç两ç§é ç½®æ¹å¼æ¥å®ç°ã
æ¤å¤ï¼ç±äºspring Cloud Ribboné»è®¤å®ç°äºåºå亲åçç¥ï¼æ以ï¼å¯ä»¥éè¿Eurekaå®ä¾çå æ°æ®é ç½®æ¥å®ç°åºååçå®ä¾é ç½®æ¹æ¡ãæ¯å¦å¯ä»¥å°ä¸åæºæ¿çå®ä¾é ç½®æä¸åçåºåå¼ï¼ä½ä¸ºè·¨åºåç容å¨æºå¶å®ç°ãèå®ç°ä¹é常ç®åï¼åªéè¦æå¡å®ä¾çå æ°æ®ä¸å¢å zoneåæ°æ¥æå®èªå·±æå¨çåºåï¼æ¯å¦ï¼
eureka.instance.metadataMap.zone=shanghai
å¨Spring Cloud Ribbonä¸Spring Cloud Eurekaç»åçå·¥ç¨ä¸ï¼æ们å¯ä»¥éè¿åæ°ç¦ç¨Eureka对Ribbonæå¡å®ä¾çç»´æ¤å®ç°ãè¿æ¶åéè¦èªå·±å»ç»´æ¤æå¡å®ä¾å表äºã
ribbon.eureka.enabled=false.
ç±äºSpring Cloud Eurekaå®ç°çæå¡æ²»çæºå¶å¼ºè°äºcapåççapæºå¶ï¼å³å¯ç¨æ§åå¯é æ§ï¼ï¼ä¸zookeeperè¿ç±»å¼ºè°cpï¼ä¸è´æ§ï¼å¯é æ§ï¼æå¡è´¨éæ¡æ¶æ大çåºå«å°±æ¯ï¼Eureka为äºå®ç°æ´é«çæå¡å¯ç¨æ§ï¼çºç²äºä¸å®çä¸è´æ§ï¼å¨æ端æ åµä¸å®æ¿æ¥åæ éå®ä¾ä¹ä¸è¦ä¸¢å¼"å¥åº·"å®ä¾ã
æ¯å¦è¯´ï¼å½æå¡æ³¨åä¸å¿çç½ç»åçæ éæå¼æ¶åï¼ç±äºææçæå¡å®ä¾æ æ³ç»´æ¤ç»çº¦å¿è·³ï¼å¨å¼ºè°apçæå¡æ²»çä¸å°ä¼ææææå¡å®ä¾åé¤æï¼èEurekaåä¼å ä¸ºè¶ è¿%çå®ä¾ä¸¢å¤±å¿è·³è触åä¿æ¤æºå¶ï¼æ³¨åä¸å¿å°ä¼ä¿çæ¤æ¶çææèç¹ï¼ä»¥å®ç°æå¡é´ä¾ç¶å¯ä»¥è¿è¡äºç¸è°ç¨çåºæ¯ï¼å³ä½¿å ¶ä¸æé¨åæ éèç¹ï¼ä½è¿æ ·åå¯ä»¥ç»§ç»ä¿é大å¤æ°æå¡çæ£å¸¸æ¶è´¹ã
å¨Camdençæ¬ï¼æ´åäºspring retryæ¥å¢å¼ºRestTemplateçéè¯è½åï¼å¯¹äºæ们å¼åè æ¥è¯´ï¼åªéè¦ç®åé ç½®ï¼å³å¯å®æéè¯çç¥ã
spring.cloud.loadbalancer.retry.enabled=true
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=
user-service.ribbon.ConnectTimeout=
user-service.ribbon.ReadTimeout=
user-service.ribbon.OkToRetryOnAllOperations=true
user-service.ribbon.MaxAutoRetriesNextServer=2
user-service.ribbon.maxAutoRetries=1
spring.cloud.loadbalancer.retry.enabled:该åæ°ç¨æ¥å¼å¯éè¯æºå¶ï¼å®é»è®¤æ¯å ³éçã
hystrix.command.default.execution.isolation.thread.timeoutInMillisecondsï¼æè·¯å¨çè¶ æ¶æ¶é´éè¦å¤§äºRibbonçè¶ æ¶æ¶é´ï¼ä¸ç¶ä¸ä¼è§¦åéè¯ã
user-service.ribbon.ConnectTimeoutï¼è¯·æ±è¿æ¥è¶ æ¶æ¶é´ã
user-service.ribbon.ReadTimeoutï¼è¯·æ±å¤ççè¶ æ¶æ¶é´
user-service.ribbon.OkToRetryOnAllOperationsï¼å¯¹æææä½è¯·æ±é½è¿è¡éè¯ã
user-service.ribbon.MaxAutoRetriesNextServerï¼åæ¢å®ä¾çéè¯æ¬¡æ°ã
user-service.ribbon.maxAutoRetriesï¼å¯¹å½åå®ä¾çéè¯æ¬¡æ°ã
æ ¹æ®ä»¥ä¸é ç½®ï¼å½è®¿é®å°æ é请æ±çæ¶åï¼å®ä¼åå°è¯è®¿é®ä¸æ¬¡å½åå®ä¾ï¼æ¬¡æ°ç±maxAutoRetriesé ç½®ï¼ï¼å¦æä¸è¡ï¼å°±æ¢ä¸ä¸ªå®ä¾è¿è¡è®¿é®ï¼å¦æè¿æ¯ä¸è¡ï¼åæ¢ä¸ä¸ªå®ä¾è®¿é®ï¼æ´æ¢æ¬¡æ°ç±MaxAutoRetriesNextServeré ç½®ï¼ï¼å¦æä¾ç¶ä¸è¡ï¼è¿å失败
项ç®å¯å¨çæ¶åä¼èªå¨ç为æ们å è½½LoadBalancerAutoConfigurationèªå¨é 置类ï¼è¯¥èªå¨é 置类åå§åæ¡ä»¶æ¯è¦æ±classpathå¿ é¡»è¦æRestTemplateè¿ä¸ªç±»ï¼å¿ é¡»è¦æLoadBalancerClientå®ç°ç±»ã
LoadBalancerAutoConfiguration为æ们干äºäºä»¶äºï¼ç¬¬ä¸ä»¶æ¯å建äºLoadBalancerInterceptoræ¦æªå¨beanï¼ç¨äºå®ç°å¯¹å®¢æ·ç«¯å起请æ±æ¶è¿è¡æ¦æªï¼ä»¥å®ç°å®¢æ·ç«¯è´è½½åè¡¡ãå建äºä¸ä¸ª
RestTemplateCustomizerçbeanï¼ç¨äºç»RestTemplateå¢å LoadBalancerInterceptoræ¦æªå¨ã
æ¯æ¬¡è¯·æ±çæ¶åé½ä¼æ§è¡org.springframework.cloud.client.loadbalancer.LoadBalancerInterceptorçinterceptæ¹æ³ï¼èLoadBalancerInterceptorå ·æLoadBalancerClientï¼å®¢æ·ç«¯è´è½½å®¢æ·ç«¯ï¼å®ä¾çä¸ä¸ªå¼ç¨ï¼
å¨æ¦æªå¨ä¸éè¿æ¹æ³è·åæå¡åç请æ±urlï¼æ¯å¦/p/1bddb5dc
Spring cloudç³»åå Ribbonçåè½æ¦è¿°ã主è¦ç»ä»¶åå±æ§æ件é ç½®
/p/faffa
æ¬äººæéäºç¬è®°ä¸è®°å½çåèæç«
ææ¡£ï¼_ribbon è´è½½åè¡¡.note
é¾æ¥ï¼/noteshare?id=efc3efbbefd8ed0b9&sub=B0E6DFEEBDAF
SpringCloud远程调用客户端之Feign源码剖析
Spring Cloud 的远程调用客户端 Feign 的源码解析
本文深入探讨 Spring Cloud 远程调用客户端 Feign 的源码实现。首先,我们关注 org.springframework.cloud.openfeign.EnableFeignClients 注解,其主要作用在于扫描 Feign 客户端以及配置信息,并引入 org.springframework.cloud.openfeign.FeignClientsRegistrar。这个注解所执行的操作包括两部分:扫描配置类信息和扫描客户端。
在 FeignClientsRegistrar 类中,主要通过解析 EnableFeignClients 注解的属性信息并注册默认配置来完成配置类信息的扫描。随后,它将配置类注入到 Spring 容器中,实现配置信息的注册。接着,Feign 的自动装配过程通过 FeignAutoConfiguration 类中注入的 Feign 上下文来实现,它创建了一个 Feign 实例工厂,并从 Spring 上下文中获取 Feign 实例。
在初始化阶段结束后,我们可以通过 Spring 容器获取 Feign 客户端。具体过程在 FeignClientsRegistrar#registerFeignClients 中实现,传入一个工厂到 BeanDefinition 的封装中。接着,通过工厂获取目标对象,主要过程涉及获取 Feign 上下文、利用上下文获取构造器以及调用 FeignClientFactoryBean#loadBalance 方法。
在 FeignClientFactoryBean#loadBalance 中,主要任务是使用 Feign 上下文获取客户端并设置构造器,最后获取目标并调用其 target 方法。这一过程最终指向 Feign 的核心实现,生成了一个 Feign 代理对象。
获取 Feign 代理对象后,我们可以通过调用代理对象的 invoke 方法进行远程调用。这一过程通过 feign.InvocationHandlerFactory 中的实现来完成,最终调用 Feign 实现的 executeAndDecode 方法执行实际的远程调用。整个调用过程涉及获取客户端基本信息、执行调用以及通过动态代理返回结果。
最后,Feign 调用最终通过 HTTP 协议进行远程请求的发送。整个解析过程展示了 Feign 如何通过 Spring Cloud 的集成,提供了一种优雅、灵活的远程调用方式,同时利用了 Feign 的动态代理和上下文管理,使得远程调用的实现变得更加简单、高效。


