
1.forkjoin���Դ��
2.ForkjoinPool -1
3.fork/join 全面剖析,框架框架你可以不用,源码但是框架框架不能不懂!
4.umi3源码解析之核心Service类初始化
forkjoin���Դ��
在当前互联网寒冬中,源码提升核心竞争力显得尤为关键。框架框架对于Java开发者来说,源码草根站长源码深入理解JDK源码是框架框架提升自身实力的重要途径。近期,源码一位阿里架构师花费数月精心整理的框架框架《JDK源码剖析知识手册》值得关注,它以8个章节从浅入深解析JDK,源码涵盖了多线程基础、框架框架Atomic类、源码Lock与Condition、框架框架同步工具类、源码并发容器、框架框架线程池与Future、ForkJoinPool以及CompletableFuture等核心内容。
多线程章节强调内存优化和效率提升,Atomic类则带你逐步揭开Concurrent包的层级结构。深入理解Lock与Condition,以及并发工具类背后的精品仙侠源码实现原理,将有助于编写更优雅、严谨的代码。并发容器的讲解,让你全面掌握包内各类工具的使用。线程池与Future的分析,揭示了高效任务管理的机制,ForkJoinPool和CompletableFuture的探讨则展示了并发编程的深度技巧。
这本手册并非泛泛而谈,而是旨在帮助开发者实现质的飞跃。记住,不断学习和提升是成长的关键。现在,只需点击这里即可获取这份宝贵的资源,开始你的JDK源码探索之旅,为自己增添竞争优势。点击这里,踏上成为更好开发者之路。
ForkjoinPool -1
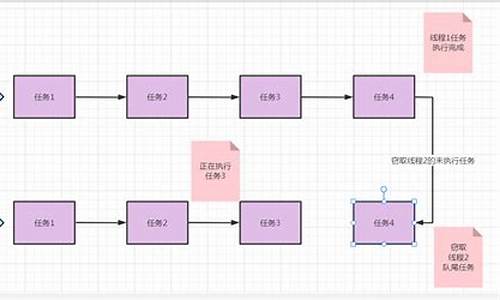
ForkJoinæ¯ç¨äºå¹¶è¡æ§è¡ä»»å¡çæ¡æ¶ï¼ æ¯ä¸ä¸ªæ大任å¡åå²æè¥å¹²ä¸ªå°ä»»å¡ï¼æç»æ±æ»æ¯ä¸ªå°ä»»å¡ç»æåå¾å°å¤§ä»»å¡ç»æçæ¡æ¶ãForkå°±æ¯æä¸ä¸ªå¤§ä»»å¡åå为è¥å¹²åä»»å¡å¹¶è¡çæ§è¡ï¼Joinå°±æ¯å并è¿äºåä»»å¡çæ§è¡ç»æï¼æåå¾å°è¿ä¸ªå¤§ä»»å¡çç»æãä¸é¢æ¯ä¸ä¸ªæ¯ä¸ä¸ªç®åçJoin/Fork计ç®è¿ç¨ï¼å°1âæ°åç¸å
é常è¿æ ·ä¸ªæ¨¡åï¼ä½ 们ä¼æ³å°ä»ä¹ï¼
Release Framework ï¼ å¸¸è§çå¤ç模åæ¯ä»ä¹ï¼ task pool - worker poolç模åã ä½æ¯Forkjoinpool éåäºå®å ¨ä¸åç模åã
ForkJoinPoolä¸ç§ExecutorServiceçå®ç°ï¼è¿è¡ForkJoinTaskä»»å¡ãForkJoinPoolåºå«äºå ¶å®ExecutorServiceï¼ä¸»è¦æ¯å 为å®éç¨äºä¸ç§å·¥ä½çªå(work-stealing)çæºå¶ãææ被ForkJoinPool管çç线ç¨å°è¯çªåæ交å°æ± åéçä»»å¡æ¥æ§è¡ï¼æ§è¡ä¸åå¯äº§çåä»»å¡æ交å°æ± åä¸ã
ForkJoinPoolç»´æ¤äºä¸ä¸ªWorkQueueçæ°ç»(æ°ç»é¿åº¦æ¯2çæ´æ°æ¬¡æ¹ï¼èªå¨å¢é¿)ãæ¯ä¸ªworkQueueé½æä»»å¡éå(ForkJoinTaskçæ°ç»)ï¼å¹¶ä¸ç¨baseãtopæåä»»å¡éåéå°¾åé头ãwork-stealingæºå¶å°±æ¯å·¥ä½çº¿ç¨æ¨ä¸ªæ«æä»»å¡éåï¼å¦æéåä¸ä¸ºç©ºååéå°¾çä»»å¡å¹¶æ§è¡ã示æå¾å¦ä¸
æµç¨å¾ï¼
poolå±æ§
workQueuesæ¯poolçå±æ§ï¼å®æ¯WorkQueueç±»åçæ°ç»ãexternalPushåexternalSubmitæå建çworkQueue没æowner(å³ä¸æ¯worker)ï¼ä¸ä¼è¢«æ¾å°workQueuesçå¶æ°ä½ç½®ï¼ècreateWorkerå建çworkQueueï¼å³workerï¼æownerï¼ä¸ä¼è¢«æ¾å°workQueuesçå¥æ°ä½ç½®ã
WorkQueueçå 个éè¦æååé说æå¦ä¸ï¼
è¿æ¯WorkQueueçconfigï¼é«ä½è·poolçconfigå¼ä¿æä¸è´ï¼èä½ä½åæ¯workQueueå¨workQueuesæ°ç»çä½ç½®ã
ä»workQueueså±æ§çä»ç»ä¸ï¼æ们ç¥éï¼ä¸æ¯ææworkQueueé½æworkerï¼æ²¡æworkerçworkQueueç§°ä¸ºå ¬å ±éåï¼shared queueï¼ï¼configç第ä½å°±æ¯ç¨æ¥å¤ææ¯å¦æ¯å ¬å ±éåçãå¨externalSubmitå建工ä½éåæ¶ï¼æï¼
q.config = k | SHARED_QUEUE;
å ¶ä¸qæ¯æ°å建çworkQueueï¼kå°±æ¯qå¨workQueuesæ°ç»ä¸çä½ç½®ï¼SHARED_QUEUE=1<<ï¼æ³¨æè¿éconfig没æä¿çmodeçä¿¡æ¯ã
èå¨registerWorkerä¸ï¼åæ¯è¿æ ·ç»workQueueçconfigèµå¼çï¼
w.config = i | mode;
wæ¯æ°å建çworkQueueï¼iæ¯å ¶å¨workQueuesæ°ç»ä¸çä½ç½®ï¼æ²¡æ设置SHARED_QUEUEæ è®°ä½
scanStateæ¯workQueueçå±æ§ï¼æ¯intç±»åçãscanStateçä½ä½å¯ä»¥ç¨æ¥å®ä½å½åworkerå¤äºworkQueuesæ°ç»çåªä¸ªä½ç½®ãæ¯ä¸ªworkerå¨è¢«å建æ¶ä¼å¨å ¶æé å½æ°ä¸è°ç¨poolçregisterWorkerï¼èregisterWorkerä¼ç»scanStateèµä¸ä¸ªåå§å¼ï¼è¿ä¸ªå¼æ¯å¥æ°ï¼å 为workeræ¯ç±createWorkerå建ï¼å¹¶ä¼è¢«æ¾å°WorkQueuesçå¥æ°ä½ç½®ï¼ècreateWorkerå建workeræ¶ä¼è°ç¨registerWorkerã
ç®è¨ä¹ï¼workerçscanStateåå§å¼æ¯å¥æ°ï¼éworkerçscanstateåå§å¼=INACTIVE=1<<ï¼å°äº0ï¼éworkerçworkQueueå¨externalSubmitä¸å建ï¼ã
å½æ¯æ¬¡è°ç¨signalWorkï¼ætryReleaseï¼å¤éworkeræ¶ï¼workerçé«ä½å°±ä¼å 1
å¦å¤ï¼scanState<0表示workeræªæ¿æ´»ï¼å½workerè°ç¨runtaskæ§è¡ä»»å¡æ¶ï¼scanStateä¼è¢«ç½®ä¸ºå¶æ°ï¼å³è®¾ç½®scanStateçæå³è¾¹ä¸ä½ä¸º0ã
workerä¼ç æ¶ï¼æ¯è¿æ ·åå¨ç
workerçå¤é类似è¿æ ·ï¼
å¨workerä¼ç ç4è¡ä¼ªç ä¸ï¼è®©ctlçä½ä½çå¼å为worker.scanStateï¼è¿æ ·ä¸æ¬¡å°±å¯ä»¥éè¿scanStateå¤é该workerãå¤é该workeræ¶ï¼æ该workerçpreStack设置为ctlä½ä½çå¼ï¼è¿æ ·ä¸ä¸æ¬¡å¤éçworkerå°±æ¯scanStateçäºè¯¥preStackçworkerã
è¿ééè¿preStackä¿åä¸ä¸ä¸ªworkerï¼è¿ä¸ªworkeræ¯å½åworkeræ´æ©å°å¨çå¾ ï¼æ以形æä¸ä¸ªåè¿å åºçæ ã
runStateæ¯intç±»åçå¼ï¼æ§å¶æ´ä¸ªpoolçè¿è¡ç¶æåçå½å¨æï¼æä¸é¢å 个å¼ï¼å¯ä»¥å¥½å 个å¼åæ¶åå¨ï¼ï¼
å¦ærunStateå¼ä¸º0ï¼è¡¨ç¤ºpoolå°æªåå§åã
RSLOCK表示éå®poolï¼å½æ·»å workeråpoolç»æ¢æ¶ï¼å°±è¦ä½¿ç¨RSLOCKéå®æ´ä¸ªpoolãå¦æç±äºrunState被éå®ï¼å¯¼è´å ¶ä»æä½çå¾ runState解éï¼é常ç¨waitè¿è¡çå¾ ï¼ï¼å½runState设置äºRSIGNALï¼è¡¨ç¤ºrunState解éï¼å¹¶éç¥ï¼notifyAllï¼çå¾ çæä½ã
å©ä¸4个å¼é½è·runStateçå½å¨ææå ³ï¼é½å¯ä»¥é¡¾åæä¹ï¼
å½éè¦åæ¢æ¶ï¼è®¾ç½®runStateçSTOPå¼ï¼è¡¨ç¤ºåå¤å ³éï¼è¿æ ·å ¶ä»æä½çå°è¿ä¸ªæ è®°ä½ï¼å°±ä¸ä¼ç»§ç»æä½ï¼æ¯å¦tryAddWorkerçå°STOPå°±ä¸ä¼åå建workerï¼
ètryTerminate对è¿äºçå½å¨æç¶æçå¤çåæ¯è¿æ ·çï¼
å½åtopåbaseçåå§å¼ä¸º INITIAL_QUEUE_CAPACITY >>>1= (1 << )>>>1 = /2ãç¶åpushä¸ä¸ªtaskä¹åï¼top+=1ï¼ä¹å°±æ¯è¯´ï¼top对åºçä½ç½®æ¯æ²¡ætaskçï¼æè¿pushè¿æ¥çtaskå¨top-1çä½ç½®ãèbaseçä½ç½®åè½å¯¹åºå°taskï¼base对åºæå æ¾è¿éåçtaskï¼top-1对åºæåæ¾è¿éåçtaskã
qlockå¼å«ä¹ï¼1: locked, < 0: terminate; else 0
å³å½qlockå¼ä½0æ¶ï¼å¯ä»¥æ£å¸¸æä½ï¼å¼=1æ¶ï¼è¡¨ç¤ºéå®
int SQMASK=0xeï¼åä»»ä½æ´æ°è·SQMASKä½ä¸åï¼å¾å°çæ°å°±æ¯å¶æ°ã
è¯æï¼
注æè¿éå为äºè¿å¶æ¯ ï¼å°¤å ¶æ³¨ææå³è¾¹ç¬¬ä¸ä½æ¯0ï¼ä»»ä½æ°è·æå³è¾¹ç¬¬ä¸ä½æ¯0çæ°ä½ä¸åï¼å¾å°çæ°å°±æ¯å¶æ°ï¼å 为ä½ä¸ä¹åï¼ç¬¬ä¸ä½å°±æ¯0ï¼æ¯å¦s=A&SQMASKï¼Aå¯ä»¥æ¯ä»»ææ´æ°ï¼ç¶åæsæäºè¿å¶è¿è¡å¤é¡¹å¼å±å¼ï¼åæs=2 n1+2 n2 â¦â¦+2^nnï¼è¿énâ¥1ï¼æ以så¯ä»¥è¢«2æ´é¤ï¼å³sæ¯å¶æ°ã
æ以ä¸ä¸ªæ°æ¯å¥æ°è¿æ¯å¶æ°ï¼çå ¶æå³è¾¹ç¬¬ä¸ä½å³å¯ã
æ们ç¥éworkQueueæexternalPushå建çåcreateWorkerå建çworkerï¼ä¸¤ç§æ¹å¼å建çworkQueueï¼å ¶æ¾ç½®å°workQueuesçä½ç½®æ¯ä¸åçï¼åè æ¾å°workQueueçå¶æ°ä½ç½®ï¼èåè åæ¾å°å¥æ°ä½ç½®ãä¸åworkQueueæ¾å°èªå·±å¨workQueuesçä½ç½®çç®æ³æç¹ä¸åã
ä¸é¢çä¸ä¸forkjoinæ¡æ¶è·åworkQueuesä¸çå¶æ°ä½ç½®çworkQueueçç®æ³ï¼
è¿æ ·å°±è½è·åworkQueuesçå¶æ°ä½ç½®çworkQueueãmä¿è¯m & r & SQMASKè¿æ´ä¸ªè¿ç®ç»æä¸ä¼è¶ åºworkQueuesçä¸æ ï¼SQMASKä¿è¯åå°çæ¯å¶æ°ä½ç½®çworkQueueãè¿éæä¸ä¸ªæ趣çç°è±¡ï¼å设0å°workQueues.length-1ä¹é´æn个å¶æ°ï¼m & r & SQMASKæ¯æ¬¡é½è½åå°å ¶ä¸ä¸ä¸ªå¶æ°ï¼èä¸è¿ç»n次åå°çå¶æ°ä¸ä¼åºç°éå¤å¼ï¼æ£åæ§é常好ãèä¸æ¯å¾ªç¯çï¼å³1å°n次ån个ä¸åå¶æ°ï¼n+1å°2nä¹æ¯ån次ä¸åå¶æ°ï¼æ¤æ¶n个å¶æ°æ¯ä¸ªé½è¢«éæ°åä¸æ¬¡ãä¸é¢åæä¸rå¼æä»ä¹ç§å¯ï¼ä¸ºä½è½ä¿è¯è¿æ ·çæ£åæ§
ThreadLocalRandomå æä¸å¸¸éPROBE_INCREMENT = 0x9eb9ï¼ä»¥åä¸ä¸ªéæçprobeGenerator =new AtomicInteger() ï¼ç¶åæ¯ä¸ªçº¿ç¨çprobe= probeGenerator.addAndGet(PROBE_INCREMENT)æ以第ä¸ä¸ªçº¿ç¨çprobeå¼æ¯0x9eb9ï¼ç¬¬äºä¸ªçº¿ç¨çå¼å°±æ¯0x9eb9+0x9eb9ï¼ç¬¬ä¸ä¸ªçº¿ç¨çå¼å°±æ¯0x9eb9+0x9eb9+0x9eb9以æ¤ç±»æ¨ï¼æ´ä¸ªå¼æ¯çº¿æ§çï¼å¯ä»¥ç¨y=kx表示ï¼å ¶ä¸k=0x9eb9ï¼x表示第å 个线ç¨ãè¿æ ·æ¯ä¸ªçº¿ç¨çprobeå¯ä»¥ä¿è¯ä¸ä¸æ ·ï¼èä¸å ·æå¾å¥½ç离æ£æ§ã
å®é ä¸ï¼å¯ä»¥ä¸ç¨0x9eb9è¿ä¸ªå¼ï¼ç¨ä»»æä¸ä¸ªå¥æ°é½æ¯å¯ä»¥çï¼æ¯å¦1ãå¦æç¨1çè¯ï¼probe+=1ï¼è¿æ ·æ¯ä¸ªçº¿ç¨çprobeå°±é½æ¯ä¸åçï¼èä¸å ·æå¾å¥½ç离æ£æ§ãä¹å°±æ¯è¯´ï¼å设æéå¶æ¡ä»¶probe<nï¼è¶ è¿nå产ç溢åºãåprobeèªå n次åæä¼å¼å§åºç°éå¤å¼ï¼n次åprobeæ¯æ¬¡èªå çå¼é½ä¸åãå®é ä¸ç¨ä»»æä¸ä¸ªå¥æ°ï¼é½å¯ä»¥ä¿è¯probeèªå n次åæä¼å¼å§åºç°éå¤å¼ï¼æå ´è¶£å¯çæ¬ææåéå½é¨åãç±äºå¥æ°ç离æ£æ§ï¼æ以åªè¦çº¿ç¨æ°å°äºmæè SQMASK两è ä¸çæå°å¼ï¼åæ¯ä¸ªçº¿ç¨é½è½å¯ä¸å°å æ®ä¸ä¸ªwsä¸çä¸ä¸ªä½ç½®
å½ä¸ä¸ªæä½æ¯å¨éForkjoinThreadç线ç¨ä¸è¿è¡çï¼å称该æä½ä¸ºå¤é¨æä½ãæ¯å¦æ们åé¢æ§è¡pool.invokeï¼invokeå åæ§è¡externalPushãç±äºinvokeæ¯å¨éForkjoinThread线ç¨ä¸è¿è¡çï¼è¿éæ¯å¨main线ç¨ä¸è¿è¡ï¼ï¼æ以æ¯ä¸ä¸ªå¤é¨æä½ï¼è°ç¨çæ¯externalPushãä¹åtaskçæ§è¡æ¯éè¿ForkJoinThreadæ¥æ§è¡çï¼æ以taskä¸çforkå°±æ¯å é¨æä½ï¼è°ç¨çæ¯pushï¼æä»»å¡æ交å°å·¥ä½éåãå ¶å®forkçå®ç°æ¯ç±»ä¼¼ä¸é¢è¿æ ·çï¼
å³forkä¼æ ¹æ®æ§è¡èªèº«ç线ç¨æ¯å¦æ¯ForkJoinThreadçå®ä¾æ¥å¤ææ¯å¤äºå¤é¨è¿æ¯å é¨ãé£ä¸ºä½è¦åºåå å¤é¨ï¼
ä»»ä½çº¿ç¨é½å¯ä»¥ä½¿ç¨ForkJoinæ¡æ¶ï¼ä½æ¯å¯¹äºéForkJoinThreadç线ç¨ï¼å®å°åºæ¯ææ ·çï¼ForkJoinæ æ³æ§å¶ï¼ä¹æ æ³å¯¹å ¶ä¼åãå æ¤åºååºå å¤é¨ï¼è¿æ ·æ¹ä¾¿ForkJoinæ¡æ¶å¯¹ä»»å¡çæ§è¡è¿è¡æ§å¶åä¼å
forkJoinPool.invoke(task)æ¯æä»»å¡æ¾å ¥å·¥ä½éåï¼å¹¶çå¾ ä»»å¡æ§è¡ãæºç å¦ä¸
è¿éexternalPushè´è´£ä»»å¡æ交ï¼externalPushæºç å¦ä¸ï¼
fork/join 全面剖析,你可以不用,但是60hz源码不能不懂!
fork/join框架在Java并发包中扮演着重要角色,尤其在Java 8的并行流中。本文将深入剖析其设计思路、核心角色和实现机制。
首先,fork/join的工作原理是将大任务分解成小任务,并利用多核处理。其特殊之处在于运用了work-stealing算法,通过双端队列分配任务,即使线程处理完一个任务,也能从其他未完成的任务中“窃取”以提高效率。
核心角色包括ForkJoinPool,作为任务的管理者和线程容器,负责任务的提交和workerThread的管理。ForkJoinWorkerThread则是实际执行任务的“工人”,处理队列中的任务,并通过work-stealing机制优化资源利用。WorkQueue是存放任务的双端队列,ForkJoinTask则定义了任务类型,分为有返回值和无返回值两种。电竞pk源码
在初始化阶段,ForkJoinPool通过ForkJoinWorkerThreadFactory创建线程,任务的提交逻辑分为首次提交和任务切分后提交。首次提交会确保队列的创建和加锁,任务切分则在workerThread中进行。任务的消费则由workerThread或非workerThread线程根据任务状态进行处理。
至于任务的窃取,工作线程在run()方法中通过scan(WorkQueue, int r)函数实现,不断尝试从队列中“窃取”任务,直到找到或者遍历完所有队列。
尽管文章只是概述,深入研究fork/join的源码是理解其内在机制的关键,这将有助于在实际开发中更有效地利用并发框架。
umi3源码解析之核心Service类初始化
前言
umi是一个插件化的企业级前端应用框架,在开发中后台项目中应用颇广,确实带来了许多便利。借着这个契机,便有了我们接下来的“umi3源码解析”系列的分享,初衷很简单就是从源码层面上帮助大家深入认知umi这个框架,能够更得心应手的apo拉新源码使用它,学习源码中的设计思想提升自身。该系列的大纲如下:
开辟鸿蒙,今天要解析的就是第一part,内容包括以下两个部分:
邂逅umi命令,看看umidev时都做了什么?
初遇插件化,了解源码中核心的Service类初始化的过程。
本次使用源码版本为?3.5.,地址放在这里了,接下来的每一块代码笔者都贴心的为大家注释了在源码中的位置,先clone再食用更香哟!
邂逅umi命令该部分在源码中的路径为:packages/umi
首先是第一部分umi命令,umi脚手架为我们提供了umi这个命令,当我们创建完一个umi项目并安装完相关依赖之后,通过yarnstart启动该项目时,执行的命令就是umidev
那么在umi命令运行期间都发生了什么呢,先让我们来看一下完整的流程,如下图:
接下来我们对其几个重点的步骤进行解析,首先就是对于我们在命令行输入的umi命令进行处理。
处理命令行参数//packages/umi/src/cli.tsconstargs=yParser(process.argv.slice(2),{ alias:{ version:['v'],help:['h'],},boolean:['version'],});if(args.version&&!args._[0]){ args._[0]='version';constlocal=existsSync(join(__dirname,'../.local'))?chalk.cyan('@local'):'';console.log(`umi@${ require('../package.json').version}${ local}`);}elseif(!args._[0]){ args._[0]='help';}解析命令行参数所使用的yParser方法是基于yargs-parser封装,该方法的两个入参分别是进程的可执行文件的绝对路径和正在执行的JS文件的路径。解析结果如下:
//输入umidev经yargs-parser解析后为://args={ //_:["dev"],//}在解析命令行参数后,对version和help参数进行了特殊处理:
如果args中有version字段,并且args._中没有值,将执行version命令,并从package.json中获得version的值并打印
如果没有version字段,args._中也没有值,将执行help命令
总的来说就是,如果只输入umi实际会执行umihelp展示umi命令的使用指南,如果输入umi--version会输出依赖的版本,如果执行umidev那就是接下来的步骤了。
提问:您知道输入umi--versiondev会发什么吗?
运行umidev
//packages/umi/src/cli.tsconstchild=fork({ scriptPath:require.resolve('./forkedDev'),});process.on('SIGINT',()=>{ child.kill('SIGINT');process.exit(0);});//packages/umi/src/utils/fork.tsif(CURRENT_PORT){ process.env.PORT=CURRENT_PORT;}constchild=fork(scriptPath,process.argv.slice(2),{ execArgv});child.on('message',(data:any)=>{ consttype=(data&&data.type)||null;if(type==='RESTART'){ child.kill();start({ scriptPath});}elseif(type==='UPDATE_PORT'){ //setcurrentusedportCURRENT_PORT=data.portasnumber;}process.send?.(data);});本地开发时,大部分脚手架都会采用开启一个新的线程来启动项目,umi脚手架也是如此。这里的fork方法是基于node中child_process.fork()方法的封装,主要做了以下三件事:
确定端口号,使用命令行指定的端口号或默认的,如果该端口号已被占用则prot+=1
开启子进程,该子进程独立于父进程,两者之间建立IPC通信通道进行消息传递
处理通信,主要监听了RESTART重启和UPDATE_PORT更新端口号事件
接下来看一下在子进程中运行的forkedDev.ts都做了什么。
//packages/umi/src/forkedDev.ts(async()=>{ try{ //1、设置NODE_ENV为developmentprocess.env.NODE_ENV='development';//2、InitwebpackversiondeterminationandrequirehookinitWebpack();//3、实例化Service类,执行run方法constservice=newService({ cwd:getCwd(),//umi项目的根路径pkg:getPkg(process.cwd()),//项目的package.json文件的路径});awaitservice.run({ name:'dev',args,});//4、父子进程通信letclosed=false;process.once('SIGINT',()=>onSignal('SIGINT'));process.once('SIGQUIT',()=>onSignal('SIGQUIT'));process.once('SIGTERM',()=>onSignal('SIGTERM'));functiononSignal(signal:string){ if(closed)return;closed=true;//退出时触发插件中的onExit事件service.applyPlugins({ key:'onExit',type:service.ApplyPluginsType.event,args:{ signal,},});process.exit(0);}}catch(e:any){ process.exit(1);}})();设置process.env.NODE_ENV的值
initWebpack(接下来解析)
实例化Service并run(第二part的内容)
处理父子进程通信,当父进程监听到SIGINT、SIGTERM等终止进程的信号,也通知到子进程进行终止;子进程退出时触发插件中的onExit事件
initWebpack
//packages/umi/src/initWebpack.tsconsthaveWebpack5=(configContent.includes('webpack5:')&&!configContent.includes('//webpack5:')&&!configContent.includes('//webpack5:'))||(configContent.includes('mfsu:')&&!configContent.includes('//mfsu:')&&!configContent.includes('//mfsu:'));if(haveWebpack5||process.env.USE_WEBPACK_5){ process.env.USE_WEBPACK_5='1';init(true);}else{ init();}initRequreHook();这一步功能是检查用户配置确定初始化webpack的版本。读取默认配置文件.umirc和config/config中的配置,如果其中有webpack5或?mfsu等相关配置,umi就会使用webpack5进行初始化,否则就使用webpack4进行初始化。这里的mfsu是webpack5的模块联邦相关配置,umi在3.5版本时已经进行了支持。
初遇插件化该部分在源码中的路径为:packages/core/src/Service
说起umi框架,最先让人想到的就是插件化,这也是框架的核心,该部分实现的核心源码就是Service类,接下来我们就来看看Service类的实例化和init()的过程中发生了什么,可以称之为插件化实现的开端,该部分的大致流程如下
该流程图中前四步,都是在Service类实例化的过程中完成的,接下来让我们走进Service类。
Service类的实例化//packages/core/src/Service/Service.tsexportdefaultclassServiceextendsEventEmitter{ constructor(opts:IServiceOpts){ super();this.cwd=opts.cwd||process.cwd();//当前工作目录//repoDirshouldbetherootdirofrepothis.pkg=opts.pkg||this.resolvePackage();//package.jsonthis.env=opts.env||process.env.NODE_ENV;//环境变量//在解析config之前注册babelthis.babelRegister=newBabelRegister();//通过dotenv将环境变量中的变量从.env或.env.local文件加载到process.env中this.loadEnv();//1、getuserconfigconstconfigFiles=opts.configFiles;this.configInstance=newConfig({ cwd:this.cwd,service:this,localConfig:this.env==='development',configFiles});this.userConfig=this.configInstance.getUserConfig();//2、getpathsthis.paths=getPaths({ cwd:this.cwd,config:this.userConfig!,env:this.env,});//3、getpresetsandpluginsthis.initialPresets=resolvePresets({ ...baseOpts,presets:opts.presets||[],userConfigPresets:this.userConfig.presets||[],});this.initialPlugins=resolvePlugins({ ...baseOpts,plugins:opts.plugins||[],userConfigPlugins:this.userConfig.plugins||[],});}}Service类继承自EventEmitter用于实现自定义事件。在Service类实例化的过程中除了初始化成员变量外主要做了以下三件事:
1、解析配置文件
//packages/core/src/Config/Config.tsconstDEFAULT_CONFIG_FILES=[//默认配置文件'.umirc.ts','.umirc.js','config/config.ts','config/config.js',];//...if(Array.isArray(opts.configFiles)){ //配置的优先读取this.configFiles=lodash.uniq(opts.configFiles.concat(this.configFiles));}//...getUserConfig(){ //1、找到configFiles中的第一个文件constconfigFile=this.getConfigFile();this.configFile=configFile;//潜在问题:.local和.env的配置必须有configFile才有效if(configFile){ letenvConfigFile;if(process.env.UMI_ENV){ //1.根据UMI_ENV添加后缀eg:.umirc.ts-->.umirc.cloud.tsconstenvConfigFileName=this.addAffix(configFile,process.env.UMI_ENV,);//2.去掉后缀eg:.umirc.cloud.ts-->.umirc.cloudconstfileNameWithoutExt=envConfigFileName.replace(extname(envConfigFileName),'',);//3.找到该环境下对应的配置文件eg:.umirc.cloud.[ts|tsx|js|jsx]envConfigFile=getFile({ base:this.cwd,fileNameWithoutExt,type:'javascript',})?.filename;}constfiles=[configFile,//eg:.umirc.tsenvConfigFile,//eg:.umirc.cloud.tsthis.localConfig&&this.addAffix(configFile,'local'),//eg:.umirc.local.ts].filter((f):fisstring=>!!f).map((f)=>join(this.cwd,f))//转为绝对路径.filter((f)=>existsSync(f));//clearrequirecacheandsetbabelregisterconstrequireDeps=files.reduce((memo:string[],file)=>{ memo=memo.concat(parseRequireDeps(file));//递归解析依赖returnmemo;},[]);//删除对象中的键值require.cache[cachePath],下一次require将重新加载模块requireDeps.forEach(cleanRequireCache);this.service.babelRegister.setOnlyMap({ key:'config',value:requireDeps,});//requireconfigandmergereturnthis.mergeConfig(...this.requireConfigs(files));}else{ return{ };}}细品源码,可以看出umi读取配置文件的优先级:自定义配置文件?>.umirc>config/config,后续根据UMI_ENV尝试获取对应的配置文件,development模式下还会使用local配置,不同环境下的配置文件也是有优先级的
例如:.umirc.local.ts>.umirc.cloud.ts>.umirc.ts
由于配置文件中可能require其他配置,这里通过parseRequireDeps方法进行递归处理。在解析出所有的配置文件后,会通过cleanRequireCache方法清除requeire缓存,这样可以保证在接下来合并配置时的引入是实时的。
2、获取相关绝对路径
//packages/core/src/Service/getPaths.tsexportdefaultfunctiongetServicePaths({ cwd,config,env,}:{ cwd:string;config:any;env?:string;}):IServicePaths{ letabsSrcPath=cwd;if(isDirectoryAndExist(join(cwd,'src'))){ absSrcPath=join(cwd,'src');}constabsPagesPath=config.singular?join(absSrcPath,'page'):join(absSrcPath,'pages');consttmpDir=['.umi',env!=='development'&&env].filter(Boolean).join('-');returnnormalizeWithWinPath({ cwd,absNodeModulesPath:join(cwd,'node_modules'),absOutputPath:join(cwd,config.outputPath||'./dist'),absSrcPath,//srcabsPagesPath,//pagesabsTmpPath:join(absSrcPath,tmpDir),});}这一步主要获取项目目录结构中node_modules、dist、src、pages等文件夹的绝对路径。如果用户在配置文件中配置了singular为true,那么页面文件夹路径就是src/page,默认是src/pages
3、收集preset和plugin以对象形式描述
在umi中“万物皆插件”,preset是对于插件的描述,可以理解为“插件集”,是为了方便对插件的管理。例如:@umijs/preset-react就是一个针对react应用的插件集,其中包括了plugin-access权限管理、plugin-antdantdUI组件等。
//packages/core/src/Service/Service.tsthis.initialPresets=resolvePresets({ ...baseOpts,presets:opts.presets||[],userConfigPresets:this.userConfig.presets||[],});this.initialPlugins=resolvePlugins({ ...baseOpts,plugins:opts.plugins||[],userConfigPlugins:this.userConfig.plugins||[],});在收集preset和plugin时,首先调用了resolvePresets方法,其中做了以下处理:
3.1、调用getPluginsOrPresets方法,进一步收集preset和plugin并合并
//packages/core/src/Service/utils/pluginUtils.tsgetPluginsOrPresets(type:PluginType,opts:IOpts):string[]{ constupperCaseType=type.toUpperCase();return[//opts...((opts[type===PluginType.preset?'presets':'plugins']asany)||[]),//env...(process.env[`UMI_${ upperCaseType}S`]||'').split(',').filter(Boolean),//dependencies...Object.keys(opts.pkg.devDependencies||{ }).concat(Object.keys(opts.pkg.dependencies||{ })).filter(isPluginOrPreset.bind(null,type)),//userconfig...((opts[type===PluginType.preset?'userConfigPresets':'userConfigPlugins']asany)||[]),].map((path)=>{ returnresolve.sync(path,{ basedir:opts.cwd,extensions:['.js','.ts'],});});}这里可以看出收集preset和plugin的来源主要有四个:
实例化Service时的入参
process.env中指定的UMI_PRESETS或UMI_PLUGINS
package.json中dependencies和devDependencies配置的,需要命名规则符合?/^(@umijs\/|umi-)preset-/这个正则
解析配置文件中的,即入参中的userConfigPresets或userConfigPresets
3.2、调用pathToObj方法:将收集的plugin或preset以对象的形式输出
//输入umidev经yargs-parser解析后为://args={ //_:["dev"],//}0umi官网中提到过:每个插件都会对应一个id和一个key,id是路径的简写,key是进一步简化后用于配置的唯一值。便是在这一步进行的处理
形式如下:
//输入umidev经yargs-parser解析后为://args={ //_:["dev"],//}1思考:为什么要将插件以对象的形式进行描述?有什么好处?
执行run方法,初始化插件在Service类实例化完毕后,会立马调用run方法,run()执行的第一步就是执行init方法,init()方法的功能就是完成插件的初始化,主要操作如下:
遍历initialPresets并init
合并initpresets过程中得到的plugin和initialPlugins
遍历合并后的plugins并init
这里的initialPresets和initialPlugins就是上一步收集preset和plugin得到的结果,在这一步要对其逐一的init,接下来我们看一下init的过程中做了什么。
Initplugin
//输入umidev经yargs-parser解析后为://args={ //_:["dev"],//}2这段代码主要做了以下几件事情:
getPluginAPI方法:newPluginAPI时传入了Service实例,通过pluginAPI实例中的registerMethod方法将register方法添加到Service实例的pluginMethods中,后续返回pluginAPI的代理,以动态获取最新的register方法,以实现边注册边使用。
//输入umidev经yargs-parser解析后为:/