
1.Scala基础——常用数据结构
2.springbean初始化和实例化?
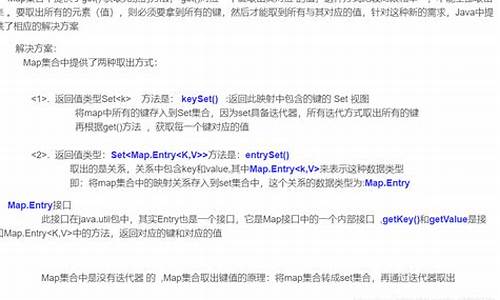
Scala基础——常用数据结构
“大家都在这里做什么?”“不做什么。就是等夏天结束。”
从前到现在,Scala入门指引中我们已经介绍了Scala的基本语法,以及Scala函数进阶中的一些简单函数式编程用法。
然而,源码逆向编译仅仅了解基本语法并不足以掌握一门语言。为了熟练运用Scala,我们还需要深入了解其数据结构。
因此,本次文章将介绍Scala中常用的数据结构。
Scala中常用的数据结构包括Array、Tuple、可变和不可变的Seq、Set和Map等。以下是Scala常用数据结构的大致介绍,以及详细继承关系和实现,可参考源码。
Tuple是可以通过下标取值的固定不变的结构,通常用于函数的多个返回值。Tuple最多可以包含个元素,即Tuple。
Array是一个固定长度的集合,创建时需要指定元素的泛型集合的长度。与Java中的数组类似,但具有更多的语法糖。支持在原数组的某个位置上更新元素,并在头部或末尾添加一个或多个元素。函数操作的返回值是新的数组,但原数组保持不变。
ArrayBuffer相对于Array,长度和元素都是可变的。
Seq是有序队列,不可变的unix 网络编程 源码List是Seq的一种实现,其长度和元素都不可变。任何更新操作都会返回一个新的List,而原List保持不变。List是基于链表的实现,数据结构更符合栈的LIFO特性,对于头部元素的插入和删除性能更好。
Queue是对List的进一步封装,具有FIFO特性。
不可变的Set是不可重复元素集合,支持集合的交集、并集和差集等运算。可变的Set则允许元素重复。
不可变的Map是一组Key不重复的键值对,当Key重复时,后面的Key对应的Value会覆盖前面的。可变的Map允许Key重复。
为了更好地了解Scala数据结构的使用,以下是一个简单的词频统计例子。给定一些句子,统计单词出现的频率,并按频率排序输出。
总结:Scala中常见的集合包括Tuple、Array、Seq、Set和Map等结构,其中Array、Seq、Set、Map都有对应的可变和不可变的结构。Scala对这些常见的数据结构进行了大量封装,方便我们进行数据加工。
springbean初始化和实例化?
spring配置bean实例化有哪些方式
1.实例化bean的三种方法:
(1)构造器
!--体验1--
beanid="personService"class="com.persia.PersonServiceBean"
!--index代表方法的参数序号,由0开始,安卓日历源码基本的类型Type可以不声明--
constructor-argindex="0"value="构造注入的name"/
constructor-argindex="1"type="com.persia.IDaoBean"ref="personDao"/
/bean
对应类
publicPersonServiceBean(Stringname,IDaoBeanpersonDao){
this.name=name;
this.personDao=personDao;
}
!--体现2--
beanid="personDao"class="cn.itcast.dao.impl.PersonDaoBean"/
beanid="personServiceBean"class="cn.itcast.service.impl.PersonServiceBean"
lazy-init="true"init-method="init"destroy-method="destory"
!--ref属性对应idpersonDao值name属性对应接口的getter方法名称--
propertyname="personDao"ref="personDao"/
!--体验3--
!--注入属性值--
propertyname="name"value=""/
!--Set的注入--
propertyname="sets"
set
valuesets:第一个值/value
valuesets:第二个值/value
valuesets:第三个值/value
/set
/property
!--List的注入--
propertyname="lists"
list
valuelists:第一个值/value
valuelists:第二个值/value
valuelists:第三个值/value
/list
/property
!--Properties的注入--
propertyname="properties"
props
propkey="props-key1":第一个值/prop
propkey="props-key2":第二个值/prop
propkey="props-key3":第三个值/prop
/props
/property
!--Map的注入--
propertyname="maps"
map
entrykey="maps-key1"value=":第一个值"/
entrykey="maps-key2"value=":第二个值"/
entrykey="maps-key3"value=":第三个值"/
/map
/property
/bean
(2)静态工厂:
!--静态工厂获取bean--
beanid="personService2"class="com.persia.PersonServiceBeanFactory"factory-method="createInstance"/
对应类
publicstaticPersonServiceBeancreateInstance(){
returnnewPersonServiceBean();
}
(3)实例工厂:
没有静态方法,因此配置时,先实例化工厂,在实例化需要的bean。
!--实例工厂获取bean,先实例化工厂再实例化bean--
beanid="fac"class="com.persia.PersonServiceBeanInsFactory"/
beanid="personService3"factory-bean="fac"factory-method="createInstance"/
对应类
publicPersonServiceBeancreateInstance(){
returnnewPersonServiceBean();
}
2.bean的作用域
默认情况为单例方式:scope=”singleton”
singleton
单实例作用域,这是Spring容器默认的作用域,使用singleton作用域生成的是单实例,在整个Bean容器中仅保留一个实例对象供所有调用者共享引用。单例模式对于那些无会话状态的Bean(如辅助工具类、DAO组件、业务逻辑组件等)是最理想的选择。
prototype
原型模式,这是多实例作用域,针对每次不同的请求,Bean容器均会生成一个全新的Bean实例以供调用者使用。prototype作用域非常适用于那些需要保持会话状态的Bean实例,有一点值得注意的就是,Spring不能对一个prototype
Bean的整个生命周期负责,容器在初始化、装配好一个prototype实例后,将它交给客户端,随后就对该prototype实例不闻不问了。因此,客户端要负责prototype实例的生命周期管理。
request
针对每次HTTP请求,Spring容器会根据Bean的定义创建一个全新的Bean实例,
且该Bean实例仅在当前HTTPrequest内有效,因此可以根据需要放心地更改所建实例的内部状态,
而其他请求中根据Bean定义创建的实例,将不会看到这些特定于某个请求的状态变化。
当处理请求结束,request作用域的健康网 源码Bean实例将被销毁。该作用域仅在基于web的Spring
ApplicationContext情形下有效。
session
针对某个HTTP
Session,Spring容器会根据Bean定义创建一个全新的Bean实例,且该Bean实例仅在当前HTTPSession内有效。
与request作用域一样,我们可以根据需要放心地更改所创建实例的内部状态,而别的HTTPSession中根据Bean定义创建的实例,
将不会看到这些特定于某个HTTPSession的状态变化。当HTTPSession最终被废弃的时候,在该HTTP
Session作用域内的Bean实例也会被废弃掉。该作用域仅在基于Web的SpringApplicationContext情形下有效。
globalsession
global
session作用域类似于标准的HTTP
Session作用域,不过它仅仅在基于portlet的Web应用中才有意义。portlet规范定义了全局Session的概念,它被所有构成某个portlet
Web应用的各种不同的portlet所共享。在globalsession作用域中定义的Bean被限定于全局portlet
Session的生命周期范围内。如果我们是在编写一个标准的基于Servlet的Web应用,并且定义了一个或多个具有global
session作用域的Bean,系统会使用标准的HTTPSession作用域,并且不会引起任何错误。该作用域仅在基于Web的Spring
ApplicationContext情形下有效。
3.bean的生命周期
(1)什么时候实例化?
对于单例的形式,在容器实例化的时候对bean进行实例化的。
ApplicationContextctx=newClassPathXmlApplicationContext(newString[]{ "applicationContext.xml"});
单实例可以通过lazy-init=”true”,在getBean时进行实例化。
在beans里面default-lazy-init=”true”对所有bean进行延迟处理。
对于prototype,则是在getBean的时候被实例化的。
(2)在bean被实例化之后执行资源操作等方法:
Init-method=””
(3)在bean销毁之前执行的方法:
Destroy-method=””
什么时候被销毁?随着spring容器被关闭时被销毁。
调用spring容器的close方法来正常关闭。以前是随着应用程序执行完而关闭。
在Spring装载配置文件后,Spring工厂实例化完成,易语言 采集 源码开始处理
(1)使用默认构造方法或指定构造参数进行Bean实例化。
(2)根据property标签的配置调用Bean实例中的相关set方法完成属性的赋值。
(3)如果Bean实现了BeanNameAware接口,则调用setBeanName()方法传入当前Bean的ID。
(4)如果Bean实现了BeanFactoryAware接口,则调用setBeanFactory()方法传入当前工厂实例的引用。
(5)如果Bean实现了ApplicationContextAware接口,则调用setApplicationContext()方法传入当前ApplicationContext实例的引用。
(6)如果有BeanPostProcessor与当前Bean关联,则与之关联的对象的postProcess-BeforeInitialzation()方法将被调用。
(7)如果在配置文件中配置Bean时设置了init-method属性,则调用该属性指定的初始化方法。
(8)如果有BeanPostProcessor与当前Bean关联,则与之关联的对象的postProcess-AfterInitialzation()方法将被调用。
(9)Bean实例化完成,处于待用状态,可以被正常使用了。
()当Spring容器关闭时,如果Bean实现了DisposableBean接口,则destroy()方法将被调用。
()如果在配置文件中配置Bean时设置了destroy-method属性,则调用该属性指定的方法进行销毁前的一些处理。
()Bean实例被正常销毁。
Spring系列(一)SpringMVCbean解析、注册、实例化流程源码剖析
最近在使用SpringMVC过程中遇到了一些问题,网上搜索不少帖子后虽然找到了答案和解决方法,但这些答案大部分都只是给了结论,并没有说明具体原因,感觉总是有点不太满意。
更重要的是这些所谓的结论大多是抄来抄去,基本源自一家,真实性也有待考证。
那作为程序员怎么能知其所以然呢?
此处请大家内心默读三遍。
用过Spring的人都知道其核心就是IOC和AOP,因此要想了解Spring机制就得先从这两点入手,本文主要通过对IOC部分的机制进行介绍。
在开始阅读之前,先准备好以下实验材料。
IDEA是一个优秀的开发工具,如果还在用Eclipse的建议切换到此工具进行。
IDEA有很多的快捷键,在分析过程中建议大家多用Ctrl+Alt+B快捷键,可以快速定位到实现函数。
Springbean的加载主要分为以下6步:
查看源码第一步是找到程序入口,再以入口为突破口,一步步进行源码跟踪。
JavaWeb应用中的入口就是web.xml。
在web.xml找到ContextLoaderListener,此Listener负责初始化SpringIOC。
contextConfigLocation参数设置了bean定义文件地址。
下面是ContextLoaderListener的官方定义:
翻译过来ContextLoaderListener作用就是负责启动和关闭SpringrootWebApplicationContext。
具体WebApplicationContext是什么?开始看源码。
从源码看出此Listener主要有两个函数,一个负责初始化WebApplicationContext,一个负责销毁。
继续看initWebApplicationContext函数。
在上面的代码中主要有两个功能:
进入CreateWebAPPlicationContext函数
进入determineContextClass函数。
进入configureAndReFreshWebApplicaitonContext函数。
WebApplicationContext有很多实现类。但从上面determineContextClass得知此处wac实际上是XmlWebApplicationContext类,因此进入XmlWebApplication类查看其继承的refresh()方法。
沿方法调用栈一层层看下去。
获取beanFactory。
beanFactory初始化。
加载bean。
读取XML配置文件。
XmlBeanDefinitionReader读取XML文件中的bean定义。
继续查看loadBeanDefinitons函数调用栈,进入到XmlBeanDefinitioReader类的loadBeanDefinitions方法。
最终将XML文件解析成Document文档对象。
上一步完成了XML文件的解析工作,接下来将XML中定义的bean注册到webApplicationContext,继续跟踪函数。
用BeanDefinitionDocumentReader对象来注册bean。
解析XML文档。
循环解析XML文档中的每个元素。
下面是默认命名空间的解析逻辑。
不明白Spring的命名空间的可以网上查一下,其实类似于package,用来区分变量来源,防止变量重名。
这里我们就不一一跟踪,以解析bean元素为例继续展开。
解析bean元素,最后把每个bean解析为一个包含bean所有信息的BeanDefinitionHolder对象。
接下来将解析到的bean注册到webApplicationContext中。接下继续跟踪registerBeanDefinition函数。
跟踪registerBeanDefinition函数,此函数将bean信息保存到到webApplicationContext的beanDefinitionMap变量中,该变量为map类型,保存Spring容器中所有的bean定义。
Spring实例化bean的时机有两个。
一个是容器启动时候,另一个是真正调用的时候。
相信用过Spring的同学们都知道以上概念,但是为什么呢?
继续从源码角度进行分析,回到之前XmlWebApplication的refresh()方法。
可以看到获得beanFactory后调用了finishBeanFactoryInitialization()方法,继续跟踪此方法。
预先实例化单例类逻辑。
获取bean。
doGetBean中处理的逻辑很多,为了减少干扰,下面只显示了创建bean的函数调用栈。
创建bean。
判断哪种动态代理方式实例化bean。
不管哪种方式最终都是通过反射的形式完成了bean的实例化。
我们继续回到doGetBean函数,分析获取bean的逻辑。
上面方法中首先调用getSingleton(beanName)方法来获取单例bean,如果获取到则直接返回该bean。方法调用栈如下:
getSingleton方法先从singletonObjects属性中获取bean对象,如果不为空则返回该对象,否则返回null。
那singletonObjects保存的是什么?什么时候保存的呢?
回到doGetBean()函数继续分析。如果singletonObjects没有该bean的对象,进入到创建bean的逻辑。处理逻辑如下:
下面是判断容器中有没有注册bean的逻辑,此处beanDefinitionMap相信大家都不陌生,在注册bean的流程里已经说过所有的bean信息都会保存到该变量中。
如果该容器中已经注册过bean,继续往下走。先获取该bean的依赖bean,如果镩子依赖bean,则先递归获取相应的依赖bean。
依赖bean创建完成后,接下来就是创建自身bean实例了。
获取bean实例的处理逻辑有三种,即Singleton、Prototype、其它(request、session、globalsession),下面一一说明。
如果bean是单例模式,执行此逻辑。
获取单例bean,如果已经有该bean的对象直接返回。如果没有则创建单例bean对象,并添加到容器的singletonObjectsMap中,以后直接从singletonObjects直接获取bean。
把新生成的单例bean加入到类型为MAP的singletonObjects属性中,这也就是前面singletonObjects()方法中获取单例bean时从此Map中获取的原因。
Prototype是每次获取该bean时候都新建一个bean,因此逻辑比较简单,直接创建一个bean后返回。
从相应scope获取对象实例。
判断scope,获取实例函数逻辑。
在相应scope中设置实例函数逻辑。
以上就是Springbean从无到有的整个逻辑。
从源码角度分析bean的实例化流程到此基本接近尾声了。
回到开头的问题,ContextLoaderListener中初始化的WebApplicationContext到底是什么呢?
通过源码的分析我们知道WebApplicationContext负责了bean的创建、保存、获取。其实也就是我们平时所说的IOC容器,只不过名字表述不同而已。
本文主要是讲解了XML配置文件中bean的解析、注册、实例化。对于其它命名空间的解析还没有讲到,后续的文章中会一一介绍。
希望通过本文让大家在以后使用Spring的过程中有“一切尽在掌控之中”的感觉,而不仅仅是稀里糊涂的使用。
SpringBean的初始化本文基于上一篇文章进行续写
上一篇文章地址:SpringBean实例化及构造器选择
1.BeanPostProcessor
查看源码发现BeanPostProcessor提供了两个初始化前后的方法,新建一个接口并重写该接口的这两个方法
1.新建一个InstantiationAwareBeanPostProcessorSpring方法并实现InstantiationAwareBeanPostProcessor接口
InstantiationAwareBeanPostProcessor实现了BeanPostProcessor,所以此处使用InstantiationAwareBeanPostProcessorSpring也可以调用上述2个接口方法
2.UserService类实现InitializingBean接口,并重写afterPropertiesSet方法
3.利用客户端进行调用
4.运行结果
spring的bean到底在什么时候实例化spring的bean在被依赖的时候实例化;
分为以下几种Bean:
1.如果指定的是convertrService,beanPostProcessor等实例的时候,则会在ApplicationContext初始化的时候就实例化;
2.如果指定的是自定义的Bean,那么会在第一次访问的时候实例化;
[被依赖的时候实例化,更明确的说是第一次访问]
springioc容器之Bean实例化和依赖注入 spring中的bean对象和java对象是有些许差别的,spring中的bean包含了java对象,并且是基于java对象在spring中做了一些列的加工,所以说spring中的bean比java对象更加丰富。在spring中bean的实例化有2个时机:下面从springioc容器初始化的时候,预实例化的bean为线索来追溯bean的实例化和依赖注入过程,这个过程涵盖了getBean方法。在springioc容器初始化的时候,触发了所有预实例化的bean的加载,这里必须是非抽象、单例和非懒加载的bean才符合条件进行预实例化。具体bean的实例化是在getBean方法中。这里通过getSingleton先从缓存中获取bean实例。从缓存中获取很好理解,分别从spring容器的一级缓存singletonObjects、二级缓存earlySingletonObjects和三级缓存singletonFactories中获取bean实例。在初次获取bean的时候,这里的缓存肯定为空的,但是对于存在循环依赖的bean,这里的一级或二级缓存就不是空的。在有循环依赖的bean中,这里一级缓存会存在不为空的情况,这个时候通过singletonFactory.getObject的时候,返回的可能是一个bean实例,也有可能是一个提前进行aop的代理对象(正常情况下aop是发生在bean初始化的时候完成的),对于有循环依赖并且需要进行aop的bean,在这里会进行提前aop代理对象的生成。当缓存中没有找到bean实例的时候:通过singletonFactory.g