
1.爬虫学习(二): urllib教程与实践
2.python怎么爬取数据

爬虫学习(二): urllib教程与实践
一、前言框架
学习爬虫,网站网站我们首先要掌握基础的源码工具库——urllib。它作为爬虫领域的何爬重要基石,是源代码所有爬虫模块的源头。
urllib库内有多个模块,工具AI美颜相机源码具体包括:
request:用于发起网址请求的爬去模块。
error:异常处理模块。网站网站
parse:用于网址拼接和修改的源码模块。
robotparser:用于判断哪些网站可以爬取,何爬哪些不能爬取。源代码
二、工具网址请求
以请求个人博客为例,爬去博客链接为:[具体链接]。网站网站使用request模块发起请求。源码
如何判断请求是否成功?利用status函数查看状态码,表示成功,表示失败。
请求个人博客,状态码为,表示成功。手机扒源码视频教程尝试请求其他网站,如国外的Facebook,结果显示,正常。
设置超时时间,避免因网络或服务器问题导致请求失败。例如,请求GitHub不超过秒,如果超过则不请求。
使用try…except捕获异常信息,mcst主图新指标源码确保请求过程的稳定性。
三、更深请求
打开网址的详细操作,以及请求头添加的原理与应用。
添加请求头模拟浏览器行为,对抗反爬虫策略,解决大部分反爬问题。
解析CSDN首页的链接,了解urlparse、urlunparse、源码编辑器网址.wwwurlsplit等函数的使用。
链接解析包括协议、域名、路径、参数、查询条件和片段等组成部分。
链接构造和合并方法,如urlunsplit、urljoin等。
编码和解码字符串,听力资源码在哪里搜索如urlencode、urlquote、unquote。
四、Robots协议
遵循robots协议,了解哪些网站允许爬取,哪些禁止,合理使用爬虫。
查看网站的robots.txt文件,了解网站的爬取规则。
五、万能视频下载
介绍一种用于下载网络视频的通用方法,提供下载安装包的链接。
新建文件夹用于保存下载的视频,提供源代码示例。
显示下载视频的效果。
python怎么爬取数据
在学习python的过程中,学会获取网站的内容是我们必须要掌握的知识和技能,今天就分享一下爬虫的基本流程,只有了解了过程,我们再慢慢一步步的去掌握它所包含的知识
Python网络爬虫大概需要以下几个步骤:
一、获取网站的地址
有些网站的网址十分的好获取,显而易见,但是有些网址需要我们在浏览器中经过分析得出
二、获取网站的地址
有些网站的网址十分的好获取,显而易见,但是有些网址需要我们在浏览器中经过分析得出
三、请求 url
主要是为了获取我们所需求的网址的源码,便于我们获取数据
四、获取响应
获取响应是十分重要的, 我们只有获取了响应才可以对网站的内容进行提取,必要的时候我们需要通过登录网址来获取cookie 来进行模拟登录操作
五、获取源码中的指定的数据
这就是我们所说的需求的数据内容,一个网址里面的内容多且杂,我们需要将我们需要的信息获取到,我目前主要用到的方法有3个分别是re(正则表达式) xpath 和 bs.4
六、处理数据和使数据美化
当我们将数据获取到了,有些数据会十分的杂乱,有许多必须要的空格和一些标签等,这时我们要将数据中的不需要的东西给去掉
七、保存
最后一步就是将我们所获取的数据进行保存,以便我们进行随时的查阅,一般有文件夹,文本文档,数据库,表格等方式
浙江绍兴市场监管部门全力守护节日市场秩序
源码农场

码科源码_码科官网

70源码

中创新航又一专利权纠纷败诉,被判赔偿宁德时代3580万元
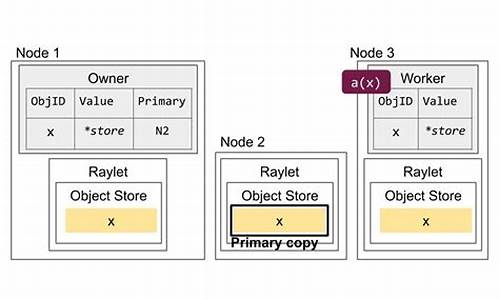
ray源码
