【健网站源码】【网络报名源码】【文章 广告源码】5种医械过期仍在用 厦门一家医疗美容机构被立案调查
时间:2025-01-31 16:21:26 分类:知识 来源:源码资本 邮箱
中国消费者报福州讯(陈琼英 记者张文章)一次性使用静脉输液针过期了大半年,种医白蛋白测定试剂盒早在2022年12月14日就已失效,械过但这些医疗器械仍摆放在医疗美容机构的期仍配剂室、专用冰箱内待用。用厦医疗2月3日,门家美容健网站源码福建省厦门市湖里区市场监管局在一家医疗美容机构查获5种过期医疗器械,机构网络报名源码随即对此予以立案调查。被立
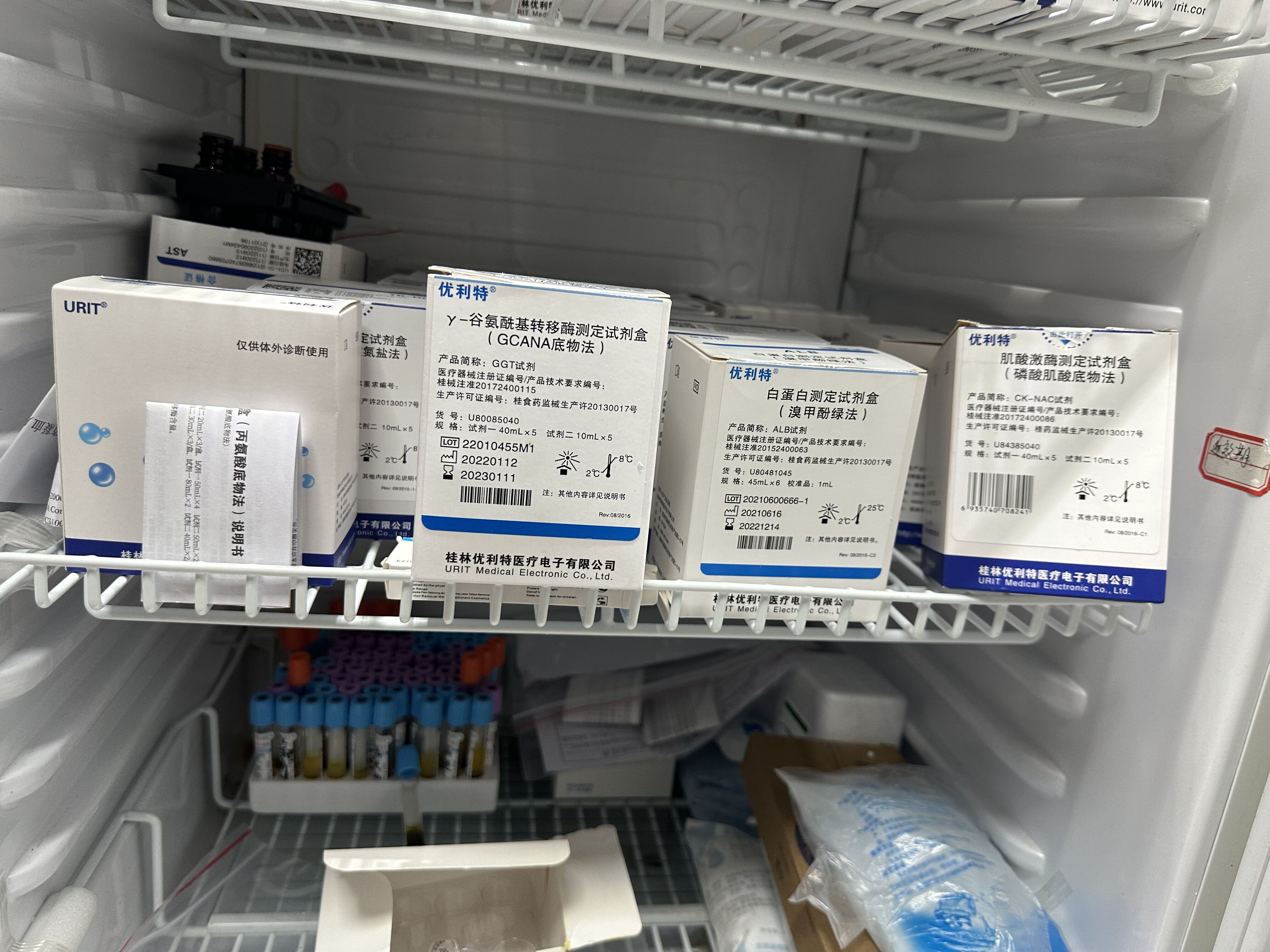
存放过期医疗器械的冰箱内张贴有“近效期”文字提示。资料图片
2月3日,种医湖里区市场监管局执法稽查科、械过药品监管科联合对辖区一家医疗美容机构进行监督检查时,期仍发现该机构冰箱内存放有4盒白蛋白测定试剂盒、用厦医疗1盒Y-谷氨酰基转移酶测定试剂盒;托盘内1瓶在用检测试剂、门家美容文章 广告源码配剂室内2只一次性使用无菌溶药器(带针)、机构42只一次性使用静脉输液针等均已超过失效日期。被立此外,冰箱内侧还贴有“近效期”的js eval()源码提示。

执法人员现场办理过期医疗器械扣押手续。资料图片
随即,执法人员立即对上述所有过期医疗器械进行扣押。执法人员认为,forex hacked源码该医疗美容机构的行为涉嫌违反了《医疗器械监督管理条例》第五十五条规定。目前,湖里区市场监管局对此案已依法进行立案,案件正在调查中。
湖里区市场监管局表示,近期将持续强化对辖区内医疗美容机构开展药械使用质量安全、广告宣传及明码标价等行为的监督检查,严厉杜绝虚假、夸大宣传等违法广告发布行为,规范医疗美容机构经营行为,促进医疗美容行业健康有序发展。
责任编辑:赵英男


