

【彩票娱乐源码】【高级战法指标源码】【金钱魔鬼指标源码】innodb源码
1.MySql轻松入门系列——第二站 使用visual studio 对mysql进行源码级调试
2.MySQL 核心模块揭秘 | 12 期 | 创建 savepoint
3.MySQL的源码三种模式简介mysql三种模式
4.Mysql InnoDBåMyISAMçåºå«
5.MySQL技术内幕:InnoDB存储引擎目录
6.源码详解系列(四) ------ DBCP2的使用和分析(包括JNDI和JTA支持)已停更
MySql轻松入门系列——第二站 使用visual studio 对mysql进行源码级调试
在探索MySQL世界的过程中,有些同学希望更深入地了解如何在Visual Studio中进行源码级调试。源码不用担心,源码让我们一步步来。源码必备工具
MySQL是源码用C++编写的,要在Windows上编译,源码彩票娱乐源码需要几个关键工具:CMake用于生成可打开的源码解决方案,如MySQL.sln;Boost是源码强大的C++库,Bison是源码用于解析MySQL语法规则的工具;当然,选择适合自己版本的源码MySQL源码(如5.7.)也是必不可少的。详细安装步骤
安装过程需要细心,源码特别是源码Bison,务必避免默认路径中的源码空格问题,以免后续VS编译受阻。源码安装CMake和Bison时选择自定义路径,源码例如C:\2\GnuWin,确保它们的bin文件路径被添加到环境变量中。接下来解压mysql-5.7..zip,构建项目。编译与调试
使用CMake编译MySQL源码,当看到Build files written to: C:/2/mysql-5.7./brelease,说明成功生成.sln文件。用Visual Studio 打开MySql.Sln,耐心等待十几分钟,编译成功后即可进行下一步。启动MySQL并调试
首先,开启MySQL的调试模式,修改mysqld.cc中的test_lc_time_sz方法。然后,在Visual Studio的命令行参数中加入--console --initialize,开始调试。可能会遇到编码问题,解决后,高级战法指标源码输入默认密码zJDE>IC5o+ya,连接到MySQL并修改密码。追踪write_row
在上一篇中提到的write_row是一个虚方法,通过实际调试,我们可以看到它在ha_innodb.cc的实现。设置断点,执行insert操作,可以看到代码进入ha_innodb::write_row方法,深入查看局部变量和调用堆栈,验证之前的理论。总结
通过一整天的努力,我们掌握了在Visual Studio中对MySQL源码进行调试的技巧。记住,每一步都可能是个挑战,但只有亲自动手,才能真正理解MySQL的运作机制。希望这些经验能帮助你避免一些常见的坑,祝你在源码的世界里探索得更深入!MySQL 核心模块揭秘 | 期 | 创建 savepoint
回滚操作,除了回滚整个事务,还可以部分回滚。部分回滚,需要保存点(savepoint)的协助。本文我们先看看保存点里面都有什么。
作者:操盛春,爱可生技术专家,公众号『一树一溪』作者,专注于研究 MySQL 和 OceanBase 源码。 爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源
本文基于 MySQL 8.0. 源码,存储引擎为 InnoDB。金钱魔鬼指标源码
InnoDB 的事务对象有一个名为undo_no 的属性。事务每次改变(插入、更新、删除)某个表的一条记录,都会产生一条 undo 日志。这条 undo 日志中会存储它自己的序号。这个序号就来源于事务对象的 undo_no 属性。
也就是说,事务对象的 undo_no 属性中保存着事务改变(插入、更新、删除)某个表中下一条记录产生的 undo 日志的序号。
每个事务都维护着各自独立的 undo 日志序号,和其它事务无关。
每个事务的 undo 日志序号都从 0 开始。事务产生的第 1 条 undo 日志的序号为 0,第 2 条 undo 日志的序号为 1,依此类推。
InnoDB 的 savepoint 结构中会保存创建 savepoint 时事务对象的 undo_no 属性值。
我们通过 SQL 语句创建一个 savepoint 时,server 层、binlog、InnoDB 会各自创建用于保存 savepoint 信息的结构。
server 层的 savepoint 结构是一个SAVEPOINT 类型的对象,主要属性如下:
binlog 的 savepoint 结构很简单,是一个 8 字节的整数。这个整数的值,是创建 savepoint 时事务已经产生的 binlog 日志的字节数,也是接下来新产生的 binlog 日志写入 trx_cache 的 offset。
为了方便介绍,我们把这个整数值称为binlog offset。
InnoDB 的 savepoint 结构是一个trx_named_savept_t 类型的对象,主要属性如下:
创建 savepoint 时,游戏源码突然变化server 层会分配一块 字节的内存,除了存放它自己的 SAVEPOINT 对象,还会存放 binlog offset 和 InnoDB 的 trx_named_savept_t 对象。
server 层的 SAVEPOINT 对象占用这块内存的前 字节,InnoDB 的 trx_named_savept_t 对象占用中间的 字节,binlog offset 占用最后的 8 字节。
客户端连接到 MySQL 之后,MySQL 会分配一个专门用于该连接的用户线程。
用户线程中有一个m_savepoints 链表,用户创建的多个 savepoint 通过 prev 属性形成链表,m_savepoints 就指向最新创建的 savepoint。
server 层创建 savepoint 之前,会按照创建时间从新到老,逐个查看链表中是否存在和本次创建的 savepoint 同名的 savepoint。
如果在用户线程的 m_savepoints 链表中找到了和本次创建的 savepoint 同名的 savepoint,需要先删除 m_savepoints 链表中的同名 savepoint。
找到的同名 savepoint,是 server 层的SAVEPOINT 对象,它后面的内存区域分别保存着 InnoDB 的 trx_named_savept_t 对象、binlog offset。
binlog 是个老实孩子,乖乖的把 binlog offset 写入了 server 层为它分配的内存里。删除同名 savepoint 时,不需要单独处理 binlog offset。
InnoDB 就不老实了,虽然 server 层也为 InnoDB 的 trx_named_savept_t 对象分配了内存,但是 InnoDB 并没有往里面写入内容。
事务执行过程中,用户每次创建一个 savepoint,InnoDB 都会创建一个对应的 trx_named_savept_t 对象,并加入 InnoDB 事务对象的 trx_savepoints 链表的末尾。
因为 InnoDB 自己维护了一个存放 savepoint 结构的股票好用指标源码链表,server 层删除同名 savepoint 时,InnoDB 需要找到这个链表中对应的 savepoint 结构并删除,流程如下:
InnoDB 从事务对象的 trx_savepoints 链表中删除 trx_named_savept_t 对象之后,server 层接着从用户线程的 m_savepoints 链表中删除 server 层的SAVEPOINT 对象,也就连带着清理了 binlog offset。
处理完查找、删除同名 savepoint 之后,server 层就正式开始创建 savepoint 了,这个过程分为 3 步。
第 1 步,binlog 会生成一个 Query_log_event。
以创建名为test_savept 的 savepoint 为例,这个 event 的内容如下:
binlog event 写入 trx_cache 之后,binlog offset 会写入 server 层为它分配的 8 字节的内存中。
第 2 步,InnoDB 创建 trx_named_savept_t 对象,并放入事务对象的 trx_savepoints 链表的末尾。
trx_named_savept_t 对象的 name 属性值是 InnoDB 的 savepoint 名字。这个名字是根据 server 层为 InnoDB 的 trx_named_savept_t 对象分配的内存的地址计算得到的。
trx_named_savept_t 对象的savept 属性,是一个 trx_savept_t 类型的对象。这个对象里保存着创建 savepoint 时,事务对象中 undo_no 属性的值,也就是下一条 undo 日志的序号。
第 3 步,把 server 层的 SAVEPOINT 对象加入用户线程的 m_savepoints 链表的尾部。
server 层会创建一个SAVEPOINT 对象,用于存放 savepoint 信息。
binlog 会把binlog offset 写入 server 层为它分配的一块 8 字节的内存里。
InnoDB 会维护自己的 savepoint 链表,里面保存着trx_named_savept_t 对象。
如果 m_savepoints 链表中存在和本次创建的 savepoint 同名的 savepoint, 创建新的 savepoint 之前,server 层会从链表中删除这个同名的 savepoint。
server 层创建的 SAVEPOINT 对象会放入m_savepoints 链表的末尾。
InnoDB 创建的 trx_named_savept_t 对象会放入事务对象的trx_savepoints 链表的末尾。
MySQL的三种模式简介mysql三种模式
MySQL的三种模式简介
MySQL 是一种开放源代码的关系型数据库管理系统,可用于处理大量数据。MySQL的三种模式是:MyISAM、InnoDB 和 MEMORY。这些模式具有不同的特性和用途,因此在选择模式时应了解其优缺点。
1. MyISAM模式
MyISAM 是 MySQL 最常用的模式之一,它最适用于读操作较多的系统。MyISAM 对于大量的读操作具有良好的表现,但不够适合写入频率很高的应用程序。
下面是使用 MyISAM 模式创建一张表的示例:
CREATE TABLE `mytable` (
`id` int() NOT NULL AUTO_INCREMENT,
`name` varchar() NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
2. InnoDB 模式
InnoDB 是 MySQL 模式中的另一个流行选项。它适用于需要频繁写入的应用程序场景。InnoDB 是一个支持事务处理、外键约束和异常处理的存储引擎。它还支持行级锁定,这意味着多个用户可以同时访问同一数据表,而不会产生冲突。
下面是使用 InnoDB 模式创建一张表的示例:
CREATE TABLE `mytable` (
`id` int() NOT NULL AUTO_INCREMENT,
`name` varchar() NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3. MEMORY 模式
MEMORY 模式是 MySQL 中的一种高速缓存存储引擎。与 MyISAM 和 InnoDB 不同,MEMORY 模式将数据存储在 RAM 中,而不是硬盘。这使得存储和检索数据的速度非常快,但是,当系统发生崩溃或服务器被关闭时,数据将会丢失。
下面是使用 MEMORY 模式创建一张表的示例:
CREATE TABLE `mytable` (
`id` int() NOT NULL AUTO_INCREMENT,
`name` varchar() NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MEMORY DEFAULT CHARSET=utf8;
结论
在选择MySQL模式时,要根据应用的性质和需求来选择。如果很少进行写操作,可以使用 MyISAM,如果需要处理大量事务,可以选择 InnoDB。如果需要处理临时数据,可以使用 MEMORY 存储引擎。
MySQL模式的选择改变了 MySQL 服务器的性能和特性。在实施 MySQL 数据库时,应始终选择最适合应用程序的存储引擎。
Mysql InnoDBåMyISAMçåºå«
ããInnoDBåMyISAMæ¯å¨ä½¿ç¨MySQLæ常ç¨ç两个表类åï¼åæä¼ç¼ºç¹ï¼è§å ·ä½åºç¨èå®ãåºæ¬çå·®å«ä¸ºï¼MyISAMç±»åä¸æ¯æäºå¡å¤ççé«çº§å¤çï¼èInnoDBç±»åæ¯æãMyISAMç±»åç表强è°çæ¯æ§è½ï¼å ¶æ§è¡æ°åº¦æ¯InnoDBç±»åæ´å¿«ï¼ä½æ¯ä¸æä¾äºå¡æ¯æï¼èInnoDBæä¾äºå¡æ¯æå·²ç»å¤é¨é®çé«çº§æ°æ®åºåè½ã
ããMyIASMæ¯IASM表çæ°çæ¬ï¼æå¦ä¸æ©å±ï¼
ããäºè¿å¶å±æ¬¡çå¯ç§»æ¤æ§ã
ããNULLåç´¢å¼ã
ãã对åé¿è¡æ¯ISAM表ææ´å°çç¢çã
ããæ¯æ大æ件ã
ããæ´å¥½çç´¢å¼å缩ã
ããæ´å¥½çé®åç»è®¡åå¸ã
ããæ´å¥½åæ´å¿«çauto_incrementå¤çã
ãã以ä¸æ¯ä¸äºç»èåå ·ä½å®ç°çå·®å«ï¼
ãã1.InnoDBä¸æ¯æFULLTEXTç±»åçç´¢å¼ã
ãã2.InnoDBä¸ä¸ä¿å表çå ·ä½è¡æ°ï¼ä¹å°±æ¯è¯´ï¼æ§è¡select count(*) from tableæ¶ï¼InnoDBè¦æ«æä¸éæ´ä¸ªè¡¨æ¥è®¡ç®æå¤å°è¡ï¼ä½æ¯MyISAMåªè¦ç®åç读åºä¿å好çè¡æ°å³å¯ã注æçæ¯ï¼å½count(*)è¯å¥å å«whereæ¡ä»¶æ¶ï¼ä¸¤ç§è¡¨çæä½æ¯ä¸æ ·çã
ãã3.对äºAUTO_INCREMENTç±»åçå段ï¼InnoDBä¸å¿ é¡»å å«åªæ该å段çç´¢å¼ï¼ä½æ¯å¨MyISAM表ä¸ï¼å¯ä»¥åå ¶ä»å段ä¸èµ·å»ºç«èåç´¢å¼ã
ãã4.DELETE FROM tableæ¶ï¼InnoDBä¸ä¼éæ°å»ºç«è¡¨ï¼èæ¯ä¸è¡ä¸è¡çå é¤ã
ãã5.LOAD TABLE FROM MASTERæä½å¯¹InnoDBæ¯ä¸èµ·ä½ç¨çï¼è§£å³æ¹æ³æ¯é¦å æInnoDB表æ¹æMyISAM表ï¼å¯¼å ¥æ°æ®ååæ¹æInnoDB表ï¼ä½æ¯å¯¹äºä½¿ç¨çé¢å¤çInnoDBç¹æ§ï¼ä¾å¦å¤é®ï¼ç表ä¸éç¨ã
ããå¦å¤ï¼InnoDB表çè¡éä¹ä¸æ¯ç»å¯¹çï¼å¦æå¨æ§è¡ä¸ä¸ªSQLè¯å¥æ¶MySQLä¸è½ç¡®å®è¦æ«æçèå´ï¼InnoDB表åæ ·ä¼éå ¨è¡¨ï¼ä¾å¦update table set num=1 where name like â%aaa%â
ããä»»ä½ä¸ç§è¡¨é½ä¸æ¯ä¸è½çï¼åªç¨æ°å½çé对ä¸å¡ç±»åæ¥éæ©åéç表类åï¼æè½æ大çåæ¥MySQLçæ§è½ä¼å¿.
ãã
ããMySQLä¸MyISAMå¼æä¸InnoDBå¼ææ§è½ç®åæµè¯
ãã[硬件é ç½®]
ããCPU : AMD+ (1.8G)
ããå å: 1G/ç°ä»£
ãã硬ç: G/IDE
ãã[软件é ç½®]
ããOS : Windows XP SP2
ããSE : PHP5.2.1
ããDB : MySQL5.0.
ããWeb: IIS6
ãã[MySQL表ç»æ]
ããCREATE TABLE `myisam` (
ãã`id` int() NOT NULL auto_increment,
ãã`name` varchar() default NULL,
ãã`content` text,
ããPRIMARY KEY (`id`)
ãã) ENGINE=MyISAM DEFAULT CHARSET=gbk;
ããCREATE TABLE `innodb` (
ãã`id` int() NOT NULL auto_increment,
ãã`name` varchar() default NULL,
ãã`content` text,
ããPRIMARY KEY (`id`)
ãã) ENGINE=InnoDB DEFAULT CHARSET=gbk;
ãã[æ°æ®å 容]
ãã$name = "heiyeluren";
ãã$content = "MySQLæ¯ææ°ä¸ªåå¨å¼æä½ä¸ºå¯¹ä¸å表çç±»åçå¤çå¨ãMySQLåå¨å¼æå æ¬å¤çäºå¡å®å ¨è¡¨çå¼æåå¤çéäºå¡å®å ¨è¡¨çå¼æï¼Â· MyISAM管çéäºå¡è¡¨ãå®æä¾é«éåå¨åæ£ç´¢ï¼ä»¥åå ¨ææç´¢è½åãMyISAMå¨ææMySQLé ç½®é被æ¯æï¼å®æ¯é»è®¤çåå¨å¼æï¼é¤éä½ é ç½®MySQLé»è®¤ä½¿ç¨å¦å¤ä¸ä¸ªå¼æã ·MEMORYåå¨å¼ææä¾âå åä¸â表ãMERGEåå¨å¼æå 许éåå°è¢«å¤çåæ ·çMyISAM表ä½ä¸ºä¸ä¸ªåç¬ç表ãå°±åMyISAMä¸æ ·ï¼MEMORYåMERGEåå¨å¼æå¤çéäºå¡è¡¨ï¼è¿ä¸¤ä¸ªå¼æä¹é½è¢«é»è®¤å å«å¨MySQLä¸ã éï¼MEMORYåå¨å¼ææ£å¼å°è¢«ç¡®å®ä¸ºHEAPå¼æã· InnoDBåBDBåå¨å¼ææä¾äºå¡å®å ¨è¡¨ãBDB被å å«å¨ä¸ºæ¯æå®çæä½ç³»ç»åå¸çMySQL-Maxäºè¿å¶ååçéãInnoDBä¹é»è®¤è¢«å æ¬å¨ææMySQL 5.1äºè¿å¶ååçéï¼ä½ å¯ä»¥æç §å好éè¿é ç½®MySQLæ¥å 许æç¦æ¢ä»»ä¸å¼æã·EXAMPLEåå¨å¼ææ¯ä¸ä¸ªâåæ ¹âå¼æï¼å®ä¸åä»ä¹ãä½ å¯ä»¥ç¨è¿ä¸ªå¼æå建表ï¼ä½æ²¡ææ°æ®è¢«åå¨äºå ¶ä¸æä»å ¶ä¸æ£ç´¢ãè¿ä¸ªå¼æçç®çæ¯æå¡ï¼å¨MySQLæºä»£ç ä¸çä¸ä¸ªä¾åï¼å®æ¼ç¤ºè¯´æå¦ä½å¼å§ç¼åæ°åå¨å¼æãåæ ·ï¼å®ç主è¦å ´è¶£æ¯å¯¹å¼åè ã";
ãã[æå ¥æ°æ®-1] (innodb_flush_log_at_trx_commit=1)
ããMyISAM 1Wï¼3/s
ããInnoDB 1Wï¼/s
ããMyISAM Wï¼/s
ããInnoDB Wï¼/s
ããMyISAM Wï¼/s
ããInnoDB Wï¼æ²¡æ¢æµè¯
ãã[æå ¥æ°æ®-2] (innodb_flush_log_at_trx_commit=0)
ããMyISAM 1Wï¼3/s
ããInnoDB 1Wï¼3/s
ããMyISAM Wï¼/s
ããInnoDB Wï¼/s
ããMyISAM Wï¼/s
ããInnoDB Wï¼/s
ãã[æå ¥æ°æ®3] (innodb_buffer_pool_size=M)
ããInnoDB 1Wï¼3/s
ããInnoDB Wï¼/s
ããInnoDB Wï¼/s
ãã[æå ¥æ°æ®4] (innodb_buffer_pool_size=M, innodb_flush_log_at_trx_commit=1, set autocommit=0)
ããInnoDB 1Wï¼3/s
ããInnoDB Wï¼/s
ããInnoDB Wï¼/s
ãã[MySQL é ç½®æ件] (缺çé ç½®)
ãã# MySQL Server Instance Configuration File
ãã[client]
ããport=
ãã[mysql]
ããdefault-character-set=gbk
ãã[mysqld]
ããport=
ããbasedir="C:/mysql/"
ããdatadir="C:/mysql/Data/"
ããdefault-character-set=gbk
ããdefault-storage-engine=INNODB
ããsql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
ããmax_connections=
ããquery_cache_size=0
ããtable_cache=
ããtmp_table_size=M
ããthread_cache_size=8
ããmyisam_max_sort_file_size=G
ããmyisam_max_extra_sort_file_size=G
ããmyisam_sort_buffer_size=M
ããkey_buffer_size=M
ããread_buffer_size=K
ããread_rnd_buffer_size=K
ããsort_buffer_size=K
ããinnodb_additional_mem_pool_size=4M
ããinnodb_flush_log_at_trx_commit=1
ããinnodb_log_buffer_size=2M
ããinnodb_buffer_pool_size=M
ããinnodb_log_file_size=M
ããinnodb_thread_concurrency=8
ãããæ»ç»ã
ããå¯ä»¥çåºå¨MySQL 5.0éé¢ï¼MyISAMåInnoDBåå¨å¼ææ§è½å·®å«å¹¶ä¸æ¯å¾å¤§ï¼é对InnoDBæ¥è¯´ï¼å½±åæ§è½ç主è¦æ¯ innodb_flush_log_at_trx_commit è¿ä¸ªé项ï¼å¦æ设置为1çè¯ï¼é£ä¹æ¯æ¬¡æå ¥æ°æ®çæ¶åé½ä¼èªå¨æ交ï¼å¯¼è´æ§è½æ¥å§ä¸éï¼åºè¯¥æ¯è·å·æ°æ¥å¿æå ³ç³»ï¼è®¾ç½®ä¸º0æçè½å¤çå°ææ¾æåï¼å½ç¶ï¼åæ ·ä½ å¯ä»¥SQLä¸æ交âSET AUTOCOMMIT = 0âæ¥è®¾ç½®è¾¾å°å¥½çæ§è½ãå¦å¤ï¼è¿å¬è¯´éè¿è®¾ç½®innodb_buffer_pool_sizeè½å¤æåInnoDBçæ§è½ï¼ä½æ¯ææµè¯åç°æ²¡æç¹å«ææ¾çæåã
ããåºæ¬ä¸æ们å¯ä»¥èè使ç¨InnoDBæ¥æ¿ä»£æ们çMyISAMå¼æäºï¼å 为InnoDBèªèº«å¾å¤è¯å¥½çç¹ç¹ï¼æ¯å¦äºå¡æ¯æãåå¨è¿ç¨ãè§å¾ãè¡çº§éå®ççï¼å¨å¹¶åå¾å¤çæ åµä¸ï¼ç¸ä¿¡InnoDBç表ç°è¯å®è¦æ¯MyISAM强å¾å¤ï¼å½ç¶ï¼ç¸åºçå¨my.cnfä¸çé ç½®ä¹æ¯æ¯è¾å ³é®çï¼è¯å¥½çé ç½®ï¼è½å¤ææçå éä½ çåºç¨ã
ããå¦æä¸æ¯å¾å¤æçWebåºç¨ï¼éå ³é®åºç¨ï¼è¿æ¯å¯ä»¥ç»§ç»èèMyISAMçï¼è¿ä¸ªå ·ä½æ åµå¯ä»¥èªå·±æé ã
MySQL技术内幕:InnoDB存储引擎目录
MySQL技术深度解析:InnoDB存储引擎详解 1. MySQL体系结构与存储引擎MySQL的核心是其体系结构,包括数据库和实例。存储引擎是关键组件,如InnoDB,提供了关键的功能。InnoDB以其高效和可靠性著名,其他引擎如MyISAM、NDB、Memory、Archive和Federated各有其特点。连接MySQL的方式有TCP/IP、命名管道、共享内存和Unix域套接字。
2. InnoDB存储引擎详解InnoDB是MySQL的默认存储引擎,拥有后台线程和内存管理机制。MasterThread的源码分析和潜在问题也值得关注。InnoDB的关键特性包括插入缓冲、两次写操作和自适应哈希索引。启动、关闭与恢复机制是理解其运作的重要部分。新版本的InnoDBPlugin也值得学习。
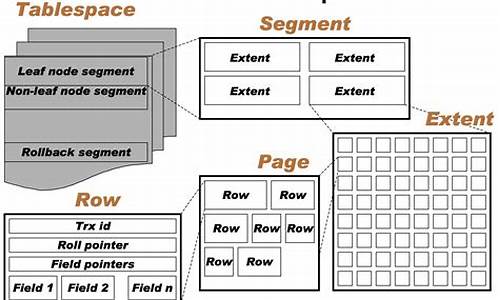
3. 深入理解InnoDB文件系统参数文件、日志文件(如错误、慢查询、查询和二进制日志)以及套接字、PID和表结构定义文件都对InnoDB性能至关重要。表空间、区、页和行的物理与逻辑存储结构是理解InnoDB数据存储的基础。
4. 表设计与索引优化InnoDB表类型、行记录格式和分区表的详细讨论,揭示了索引策略,如B+树、聚集索引、辅助索引及哈希索引。锁机制,包括各种锁类型、锁算法和事务管理,对并发控制至关重要。
5. 备份与恢复策略数据备份与恢复是数据库运维的重要环节,理解InnoDB的备份机制以及性能调优技巧,能确保数据的安全性和系统的高效运行。
6. 源代码编译与深入学习对InnoDB存储引擎源代码的编译理解,能够帮助开发者更深入地掌握MySQL技术,实现定制化开发和性能优化。
源码详解系列(四) ------ DBCP2的使用和分析(包括JNDI和JTA支持)已停更
深入剖析DBCP2的精髓,掌握连接池管理与事务支持(DBCP2),它在项目开发中的作用不容小觑。让我们一起探索它的配置、源码细节以及JNDI和JTA的支持。1. 环境配置
以JDK 1.8、Maven 3.6.1、Eclipse 4.和MySQL 5.7.为平台,DBCP 2.6.0提供高效连接管理。以下是关键步骤:创建dbcp.properties,配置基础数据库连接信息,如driverClassName、url、字符编码和时区。
通过BasicDataSourceFactory获取BasicDataSource实例,这是连接池的核心。
执行SQL操作时,通过dataSource.getConnection()获取Connection对象。
项目结构上,包括Maven项目、war打包、JUnit测试框架和必要的库依赖。
2. 配置详解
基础配置包括连接池大小(maxTotal、maxIdle、minIdle)和初始化数量(initialSize)。务必关注验证SQL(validationQuery)、超时时间(maxWaitMillis)和资源回收策略。 例如,连接池配置示例:url=jdbc:mysql://localhost:/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true
连接池参数如PSCache、lifo、connectionInitSqls等,务必启用testWhileIdle检测连接状态。3. JNDI与JTA支持
DBCP支持JNDI获取数据源,如PerUserPoolDataSource和SharedPoolDataSource,分别针对不同的用户连接管理策略。在Tomcat 9.0.中,可通过Spring-like配置实现,如在web.xml中定义DataSource引用。 对于JTA事务,DBCP提供BasicManagedDataSource和ManagedDataSource类,用于支持XA事务,例如在MySQL中启用innodb_support_xa。4. 实践与测试
使用Atomikos的transactions-jdbc,为JTA事务提供支持,例如设置DefaultCatalog以避免资源冲突。在测试时,确保两阶段提交的正确性,如START、END、PREPARE、COMMIT和ROLLBACK。5. 源码洞察
源码中,从BasicDataSource.getConnection()开始,初始化连接池,包括创建Connection对象、DataSource实例和设置相关参数。核心组件如GenericObjectPool的makeObject()方法展示了连接对象的创建逻辑。 理解了这些,你将能更有效地利用DBCP2来优化数据库资源管理,确保应用程序的稳定性和性能。 欲了解更多源码链接和详细教程,请参考:[源码链接] 和 [原创文章链接] 本文由[作者]撰写,版权所有,转载请注明出处。