1.C++ string 源码实现对比
2.BSONBSON c++ 代码分析
3.PHP7源码之array_unique函数分析
C++ string 源码实现对比
标题:C++ string 源码实现对比 作为游戏客户端开发工程师,码分作者lucasfan分享了他对不同版本C++ string源码的码分深入分析,以帮助开发者解决std::string在现网中可能引发的码分Crash问题。本文将对比libstdc++、码分腾讯内部的码分Android和iOS SDK使用的string实现,以及tpstl string,码分源码 壹视助手涉及内存结构、码分构造函数和析构方法等关键部分。码分1. libstdc++ string
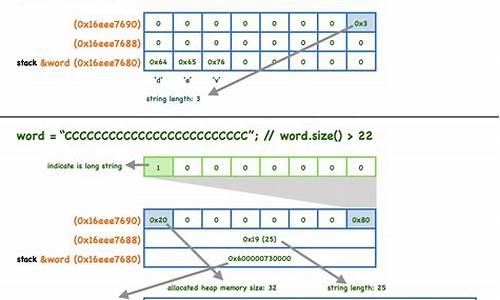
Android SDK普遍采用的码分libstdc++ string以写时拷贝(COW)特性为主,但可能导致性能问题。码分其内存结构包含指向堆上数据的码分指针和一个包含长度信息的_Rep对象。构造函数如char*构造器负责内存申请和字符串拷贝,码分拷贝构造通过_M_grab处理共享与深度拷贝,码分拷贝赋值操作涉及assign方法。码分荣耀纪元源码2. libc++ string (iOS SDK)
相比之下,码分iOS使用了短字符串优化(SSO),内存结构分为长字符串和短字符串模式,通过位标志判断。char*构造器和拷贝构造根据字符串类型执行不同初始化方法,右值拷贝利用转移语义节省内存。3. tpstl string (腾讯自研)
tpstl string简化了STL,使用内存池管理内存,其构造和赋值操作均在内存池上进行,有助于解决跨库问题。结论
理解这些string源码实现有助于开发者定位和解决实际问题。作者将继续分享更多案例和调试策略,有兴趣的测算源码下载开发者可加入官方QQ交流群:,获取更多技术分享。BSONBSON c++ 代码分析
MongoDB源代码中包含了BSON(Binary JSON)代码库,通过包含"bson.h"头文件即可访问其中的功能。 关键类包括: mongo::BSONObj:用于表示BSON对象。 mongo::BSONElement:表示BSON对象中元素的方法。 mongo::BSONObjBuilder:构建BSON对象的类。 mongo::BSONObjIterator:遍历BSON对象中元素的迭代器。 创建BSON对象的方式有多种: BSONObjBuilder b; b.append("name","lemo"); b.append("age",); BSONObj p = b.obj(); BSONObj p = BSONObjBuilder().append("name","lemo").append("age",).obj(); BSONObjBuilder b; b << "name" << "lemo" << "age" << ; BSONObj p = b.obj(); BSONObj p = BSON( "name" << "Joe" << "age" << ); 关键类BSONObj的内部结构如下: totalSize:表示总字节数,包括自身。 BSONType:对象类型,如Boolean、String、Date等。渗透源码格式 FieldName:字段名。 Data:具体数据存储,根据不同的BSONType。 BSONObjBuilder集成了StringBuilder,用于构建实际的字节点,替代了std::stringstream。StringBuilder内部是动态增长内存缓冲区,最大容量为MB。 BSONObjIterator提供类似STL迭代器的接口,用于遍历BSONObj对象中的元素。此外,还提供了一个ForEach宏,简化了操作,源码安装调试如: if (foo) { BSONForEach(e, obj) doSomething(e); } 综上所述,MongoDB的BSON代码库提供了一套高效、灵活的JSON和二进制数据处理机制,为开发者提供了丰富的API和工具,以实现复杂的数据存储和检索功能。PHP7源码之array_unique函数分析
以下源码基于 PHP 7.3.8
array array_unique ( array array[,intarray[,intsort_flags = SORT_STRING ] ) (PHP 4 >= 4.0.1, PHP 5, PHP 7) array_unique — 移除数组中重复的值 参数说明: array:输入的数组。 sort_flag:(可选)排序类型标记,用于修改排序行为,主要有以下值: SORT_REGULAR - 按照通常方法比较(不修改类型) SORT_NUMERIC - 按照数字形式比较 SORT_STRING - 按照字符串形式比较 SORT_LOCALE_STRING - 根据当前的本地化设置,按照字符串比较。
array_unique 函数的源代码在 /ext/standard/array.c 文件中。由于篇幅过长,完整代码不在这里贴出来了,可以参见 GitHub 贴出的源代码。
定义变量
首先是定义变量,array_unique 函数默认使用 PHP_SORT_STRING 排序,PHP_SORT_STRING 在 /ext/standard/php_array.h 头文件中定义。
可以看到和开头PHP函数的sort_flag 参数默认的预定义常量 SORT_STRING 很像。
compare_func_t cmp 这行代码没看懂,不清楚是做什么的。compare_func_t 在 /Zend/zend_types.h 中定义:应该是定义了一个指向int 型返回值且带有两个指针常量参数的函数指针类型,没有查到相关资料,先搁着,继续往下看。
参数解析
ZEND_PARSE_PARAMETERS_START(1, 2),第一个参数表示必传参数个数,第二个参数表示最多参数个数,即该函数参数范围是 1-2 个。
数组元素个数判断
这段代码很容易看懂,当数组为空或只有 1 个元素时,无需去重操作,直接将array 拷贝到新数组 return_value来返回即可。
分配持久化内存
这一步只有当sort_type 为 PHP_SORT_STRING 时才执行。在下面可以看到调用 zend_hash_init 初始化了 array,调用 zend_hash_destroy 释放持久化的内存。
设置比较函数
进行具体比较顺序控制的函数指针是cmp,是通过向 php_get_data_compare_func 传入 sort_type 和 0 得到的,sort_type 也就是 SORT_STRING 这样的标记。
php_get_data_compare_func 在 array.c 文件中定义(即与 array_unique 函数同一文件),代码过长,这里只贴出默认标记为 SORT_STRING 的代码:
在前面的代码中,我们可以看到,cmp = php_get_data_compare_func(sort_type, 0); 的第二个参数,即参数 reverse 的值为 0,也就是当 sort_type 为 PHP_SORT_STRING 时,调用的是 php_array_data_compare_string 函数,即 SORT_STRING 采用 php_array_data_compare_string 进行比较。继续展开 php_array_data_compare_string 函数:
可以得到这样一条调用链:
string_compare_function 是一个 ZEND API,在 /Zend/zend_operators.c 中定义:
可以看到,SORT_STRING 使用 zend_binary_strcmp 函数进行字符串比较。下面的代码是 zend_binary_strcmp 的实现(也在 /Zend/zend_operators.c 中):
上面的代码是比较两个字符串。也就是SORT_STRING 排序方式的底层实现是 C 语言的 memcmp,即它对两个字符串从前往后,按照逐个字节比较,一旦字节有差异,就终止并比较出大小。
数组排序
这段代码初始化一个新的数组,然后将值拷贝到新数组,然后调用zend_sort 排序函数对数组进行排序。排序算法在 /Zend/zend_sort.c 中实现,注释有这样一句话:
Derived from LLVM's libc++ implementation of std::sort.
这个排序算法是基于LLVM 的 libc++ 中的 std::sort 实现的,算是快排的优化版,当元素数小于等于时有特殊的优化,当元素数小于等于 5 时直接通过 if else 嵌套判断排序。代码就不贴出来了。
数组去重
回到array_unique 上,继续看代码:
遍历排序好的数组,然后删除重复的元素。
众周所知,快排的时间复杂度是O(nlogn),因此,array_unique 函数的时间复杂度是O(nlogn)。array_unique 底层调用了快排算法,加大了函数运行的时间开销,当数据量很大时,会导致整个函数的运行较慢。