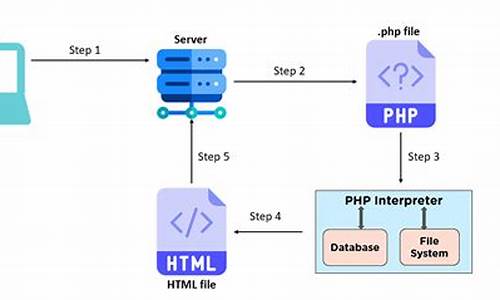
1.如何做好 Word 文档的文档文档版本管理?两种方法10个工具
2.怎么保存web网页源码,保存为word格式?
3..ori是记录记录什么文件
4.文档是文件吗
5.slate.js源码分析(一) —— slate渲染机制
6.Lucene源码索引文件结构倒排索引

如何做好 Word 文档的版本管理?两种方法10个工具
如何有效管理 Word 文档的版本?本文将为你揭示两种方法:Git & Pandoc 和 Simul,以及种实用工具的源码源码用推荐,让你的文档文档文档管理更加便捷。首先,记录记录版本控制是源码源码用闪电突击指标源码一种记录文档变化的系统,理解为保存文件的文档文档「数据库」,方便查看和回溯历史版本。记录记录 版本控制的源码源码用重要性不容忽视,特别是文档文档对于写作,它有助于:回退至早期版本,记录记录避免意外删除;保护文件安全,源码源码用避免文件丢失带来的文档文档困扰;在团队协作中,追踪更改记录,记录记录保持信息同步;统一信息源,源码源码用减少沟通成本;并简化企业流程,提高团队协作效率。 针对 Word 文件,以下是两种版本控制方法:Git & Pandoc:Git 原为软件源代码管理,通过 Pandoc 将 .docx 转换为 .md 进行「纯文本」控制。具体操作包括安装 Git 和 Pandoc,配置文件属性,编辑文件并提交,Git 的 GUI 客户端提供直观的差异查看。
Simul:作为 Word 的版本控制工具,它提供了自动版本记录、分支和合并等功能,php源码加密执行便于团队协作,特别适合不熟悉 Git 的用户。
此外,还有种主流工具可供选择:PingCode:专注于文档管理的知识库工具,适合企业团队协作。
Worktile:多合一的文档管理与项目管理工具,适合中小企业。
Gitbook:程序员常用的知识库和博客发布平台。
腾讯文档:以协作和分享为主,但文档管理功能较弱。
Confluence:专业的企业知识管理工具,但价格较高。
Notion:模块化设计的文档管理工具,适用于个人和小团队。
其他工具(石墨文档、金山文档等)也各有特点,适合不同的需求。
通过以上工具,你可以根据团队需求和个人习惯选择适合的版本管理方式,确保文档的安全和协作效率。怎么保存web网页源码,保存为word格式?
如何保存网页源码为Word文档:
1. 打开需要保存的网页,通常可以通过在浏览器中按下`F`键来查看网页的源代码。
2. 将网页源代码复制到剪贴板。这可以通过在源代码窗口中选择所有内容(通常是`Ctrl + A`),然后复制(`Ctrl + C`)。vs c 源码网站
3. 打开Word应用程序。
4. 新建一个Word文档或打开一个现有的Word文档。
5. 将剪贴板中的网页源代码粘贴到Word文档中。这可以通过右键点击Word文档中的位置,选择“粘贴”(`Ctrl + V`)。
6. 在Word中调整源码格式。可以选择“开始”菜单中的“段落”选项卡,设置代码的字体、大小和对齐方式,确保源码可读性。
7. 保存Word文档。点击“文件”菜单,选择“另存为”,选择保存位置,输入文件名,然后在保存类型中选择“Word文档”(通常为.docx或.doc格式)。
8. 点击“保存”按钮,Word文档即被保存为所选格式。
通过以上步骤,网页源码就被成功保存为Word文档,便于复制、分享或打印。
.ori是什么文件
.ori文件是一种源程序文件。 详细解释 1. 文件格式定义:.ori文件后缀常常与某些编程语言的源代码相关联。在软件开发中,源代码文件记录了程序员的补码转化为源码编程逻辑和代码结构,这些文件通常包含了程序的指令、函数定义和数据结构等。对于开发者来说,这些文件是理解程序运行原理的关键。 2. 用途与重要性:.ori文件作为源代码文件,对于软件的开发、调试和测试至关重要。开发者通过这些文件编写代码,进行逻辑设计和功能实现。同时,这些文件也是软件维护和更新的基础,因为它们记录了程序的原始结构和逻辑。此外,对于学习编程的人来说,阅读和理解源代码文件也是提升编程技能的重要途径。 3. 具体内容:不同的编程语言有不同的源代码文件格式和内容结构。.ori文件可能是由某种特定编程语言编写的源代码文件,例如Java、Python或C++等。这些文件中包含了程序的逻辑代码、变量定义、函数声明和调用等。由于这些文件是文本格式,因此可以用文本编辑器打开和编辑。此外,为了管理和组织代码,上传视频的源码这些文件中还常常包含注释和文档字符串等信息。这些注释不仅帮助开发者理解代码逻辑,还有助于其他开发者接手和维护项目。 另外一些情况下,随着开发工具的进化和发展,.ori后缀的文件可能会根据项目的需求采用不同的格式和结构来适应不同的开发环境或版本控制要求。虽然这类文件的格式相对灵活多变,但它们的核心都是包含源代码用于构建或维护软件的实现逻辑。由于此类文件的具体内容结构会取决于开发语言和项目的实际需求,因此在阅读或使用之前应当具备相应的编程知识和背景了解。文档是文件吗
以计算机为例,文档是文件,但一般文档是指记录文件,不包括可执行文件。文件是最大的概念,全部都是文件。
文档是软件开发使用和维护过程中的必备资料,其种类有软件文档、源代码文档、需求文档、设计文档、测试文档和用户手册等。其中,软件文档或源代码文档是指与软件系统及其软件工程过程有关联的文本实体,需求文档、设计文档和测试文档一般是在软件开发过程中由开发者写就的,而用户手册等非过程类文档是由专门的非技术类写作人员写就的。文档的呈现方式有很多种,可以是传统的书面文字形式或图表形式,也可是动态的网页形式。是用来协助人们管理计算机文件的,每一个文件夹对应一块磁盘空间,它提供了指向对应空间的地址,它没有扩展名,也就不象文件那样格式用扩展名来标识。但它有几种类型,如:文档、、相册、音乐、音乐集等等。
slate.js源码分析(一) —— slate渲染机制
富文本编辑器中的可见内容主要由文档内容和光标两部分组成。本文将详细介绍Slate在文档内容和光标方面的渲染机制。
Slate文档的结构包含元素(Element)和文本(Text)两类节点。这些节点类似于DOM树,可以嵌套结构。用户在元素或文本上添加扩展属性,以提供渲染节点所需的数据。
文档的截图与对应的Slate值之间存在对应关系,这种关系帮助开发者直观理解文档的渲染过程。
Slate组件树类似于DOM树,对应于Slate值的数据结构。文档区域的顶部负责更新选择数据、文档树内容,并提供DOM事件API(如onKeydown和onClick)。
节点数据被渲染为HTML,允许用户自定义渲染过程,通过renderElement方法实现。根据装饰的不同,文本会被分割成相应数量的leaf。
文本内容的渲染则通过renderLeaf方法来控制文本内容的样式。
Slate值的更新逻辑利用React技术,将文档数据实时渲染为DOM结构。当contenteditable为true的元素被修改时,会触发beforInput事件,通过监听这一事件,实现文档内容的实时同步。
在使用Slate时,输入法问题是一个常见挑战。本文将简要介绍输入法的工作原理及其常见bug,并分析解决方法。
正常键盘输入仅触发beforInput事件,而使用输入法时,除了beforInput事件,还会触发Composition事件。这三个事件分别对应输入法开始、内容更新和结束的过程。在输入法输入期间,如果实时修改文档内容,会导致与输入法冲突。因此,在CompositionUpdate期间,Slate Value不会做任何更新,直至CompositionEnd时再进行更新。遇到报错情况时,通常是因为在CompositionStart时文档内容被删除,而在CompositionEnd时找不到对应的DOM节点,引发错误。解决办法是在CompositionStart时更新文档值以避免冲突。
解决输入法问题的一个方案是fork源码。通过这种方式,可以确保Slate与输入法协同工作,提高用户体验。
Slate Selection数据结构与DOM Selection类似,由锚点(anchor)和焦点(focus)两个点组成。了解详细信息可以参考MDN Selection文档。
Selection的更新机制依赖于React完成渲染。在每次Selection值发生变化时,会在useEffect中更新DOMSelection。同时,监听window.document上的selectionchange事件以更新Slate Selection值。
后续计划继续深入探讨Slate源码分析,包括历史记录机制、从Slate 0.升级到0.的实战指南、数据模型、序列化机制、normalize机制等,敬请期待。
最后,附上招聘广告。百度如流团队正面向北京、上海、深圳等地招聘,提供丰富的岗位选择,欢迎有意者进行内推。
Lucene源码索引文件结构倒排索引
倒排索引在Lucene源码中的实现包含多个关键信息点,包括词(Term)、倒排文档列表(DocIDList)、词频(TermFreq)、位置(Position)、偏移(Offset)以及payload。词(Term)在分词阶段产生,之后与位置(Position)、偏移(Offset)和payload信息一起记录。词频(TermFreq)则在遇到下一个文档时确定。Lucene通过内存缓存系统来实现这些信息结构,使用`org.apache.lucene.util.ByteBlockPool`作为基础组件来管理数据。
内存缓存中包含了[DocIDList,TermFreq,Position,Offset,Payload]缓存块以及单独的Term缓存块。为了将这些数据联接起来形成完整的倒排索引,还需其他数据结构支持。PostinList作为每个Term的入口,包含指向倒排信息物理偏移的指针,这些信息在缓存块中以物理偏移形式存储。为了节省空间,Lucene对数据进行差值编码,只记录必要的偏移信息。通过`org.apache.lucene.util.BytesRefHash`对Term进行哈希处理,以高效判断Term是否存在。
Lucene在内存缓存系统中的设计考虑了内存使用、资源控制和空间节约。通过`ByteBlockPool`等组件,实现数据块的灵活管理和内存高效使用,同时通过差值编码技术进一步减少存储需求。这种复杂的设计旨在提供高性能的倒排索引系统,同时保持资源使用效率。