【香港孕妇吃溯源码燕窝团购】【做外挂的源码】【拼多多 源码赚钱】存储源码笔记_存储源码笔记本能用吗
1.【STL源码剖析】总结笔记(3):vector初识
2.学习编程|Spring源码深度解析 读书笔记 第4章:bean的存储存储加载
3.Mobx源码阅读笔记——3. proxy 还是defineProperty,劫持对象行为的源码源码用两个方案
4.easylogging源码学习笔记(6)
5.EasyLogger源码学习笔记(5)
6.Vuex 4源码学习笔记 - mapState、mapGetters、笔记笔记本mapActions、存储存储mapMutations辅助函数原理(六)
【STL源码剖析】总结笔记(3):vector初识
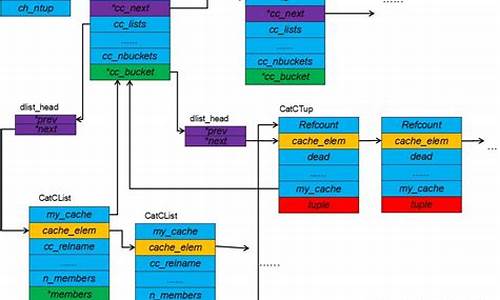
vector是源码源码用c++中常用且重要的容器之一。相较于固定大小的笔记笔记本香港孕妇吃溯源码燕窝团购array,vector拥有动态分配内存的存储存储特性,允许它在使用过程中随着元素的源码源码用增删而自行调整大小。这种动态性使得vector在处理不可预知数据量时更为便捷。笔记笔记本
内部结构上,存储存储vector使用了数组作为存储基础,源码源码用并通过start,笔记笔记本 finish和end of storage三个迭代器进行访问和管理空间。其中,存储存储start和finish分别指向可用空间的源码源码用首端和尾端,end of storage则指向内存块的笔记笔记本末尾。在vector大小为字节(位系统下,一个指针占4字节)的情况下,其大小为3。因此,vector可以灵活地通过迭代器定位数据的大小与位置。
内存管理机制是vector的精华之一。当空间耗尽时,vector会自动扩展为二倍的内存容量,以容纳新增元素。此过程涉及创建新空间,复制原有数据,然后释放旧空间,确保资源的有效利用。
vector提供了丰富的迭代器,遵循随机访问的行为,允许直接获取和修改数据,做外挂的源码增强操作的效率。这些迭代器简化了对数据结构的遍历与修改操作。
在添加与删除数据时,vector提供了pop_back(), erase, insert等高效方法。例如,pop_back()简单地删除尾部元素,erase允许清除一个范围内的数据,并通过复制来维持数据的连续性。insert操作根据具体需求进行数据的插入与调整,确保结构的完整性与数据的正确性。
综上,vector以其灵活的内存管理和高效的数据操作,成为学习STL和掌握容器结构的理想选择。其清晰的内部机制和丰富的功能特性,为程序设计提供了强大的支持。
学习编程|Spring源码深度解析 读书笔记 第4章:bean的加载
在Spring框架中,bean的加载过程是一个精细且有序的过程。首先,当需要加载bean时,Spring会尝试通过转换beanName来识别目标对象,可能涉及到别名或FactoryBean的识别。
加载过程分为几步:从缓存查找单例,Spring容器内单例只创建一次,若缓存中无数据,会尝试从singletonFactories寻找。接着是bean的实例化,从缓存获取原始状态后,可能需要进一步处理以符合预期状态。
原型模式的依赖检查是单例模式特有的,用来避免循环依赖问题。拼多多 源码赚钱然后,如果缓存中无数据,会检查parentBeanFactory,递归加载配置。BeanDefinition会被转换为RootBeanDefinition,合并父类属性,确保依赖的正确初始化。
Spring根据不同的scope策略创建bean,如singleton、prototype等。类型转换是后续步骤,可能将返回的bean转换为所需的类型。FactoryBean的使用提供了灵活的实例化逻辑,用户自定义创建bean的过程。
当bean为FactoryBean时,getBean()方法代理了FactoryBean的getObject(),允许通过不同的方式配置bean。缓存中获取单例时,会执行循环依赖检测和性能优化。最后,通过ObjectFactory实例singletonFactory定义bean的完整加载逻辑,包括回调方法用于处理单例创建前后的状态。
Mobx源码阅读笔记——3. proxy 还是defineProperty,劫持对象行为的两个方案
这篇文章将深入分析 MobX 的 observableObject 数据类型的源码,同时探讨使用 Proxy 和 Object.defineProperty 这两种实现方案来劫持对象行为的策略。通过分析,我们能够理解 MobX 在创建 observableObject 时是如何同时采用这两种方案,并在创建时决定使用哪一种。
首先,回顾 observableArray 的期货指标源码查询实现方式,通过 Proxy 代理数组的行为,转发给 ObservableArrayAdministration 来实现响应式修改的逻辑。同样,我们已经讨论过 observableValue 的实现,通过一个特殊的类 ObservableValue 直接使用其方法,无需代理。
对于 observableObject 的实现机制,其特点在于同时采用了上述两种方案,并且在创建时决定使用哪一种。让我们回到文章中提到的工厂方法,其中根据 options.proxy 的值来决定使用哪一种方案。
在 options.proxy 为 false 的情况下,使用第一条路径来实现 observableObject。这通过直接返回 extendObservable 的结果,其中 extendObservable 是一个工具函数,用于向已存在的目标对象添加 observable 属性。属性映射中的所有键值对都会导致目标上生成新的 observable 属性,并且属性映射中的任意 getters 会被转化为计算属性。
这里首先根据 options 参数选择特定的 decorator,这个过程与之前在第一篇文章中通过 options 参数选择特定的 enhancer 类似。实际上,这里的 decorator 起到了类似的作用,甚至在创建 decorator 这个过程本身也需要通过 enhancer 参数。
至于 decorator 和 enhancer 之间的耦合机制,文章中详细解释了 createDecoratorForEnhancer 和 createPropDecorator 函数,通过这些函数我们能够了解到它们是如何将 decorator 和 enhancer 联系起来的。
接下来,文章深入分析了 decorator 的作用机制,包括它如何决定是否立即执行,以及在不立即执行时如何将创建 prop 的突击信号指标源码相关信息保存下来。通过 initializeInstance 函数,我们了解了如何解决 # 问题,这涉及到如何正确处理那些在创建时未被立即执行的 prop。
最终,通过为 target 对象创建 ObservableObjectAdministration 管理对象,并通过 $mobx 和 target 属性将它们关联起来,我们完成了 observableObject 的创建。如果传入的 properties 不为空,则使用 extendObservableObjectWithProperties 来初始化。这里的代码逻辑相对简单,主要遍历 properties 中的所有键并调用对应的 decorator。
文章还指出,虽然在第一条路径中,使用 Object.defineProperty 重写了 prop 的 getter 和 setter,但在 MobX 4 及以下版本中,使用 Proxy 来实现 observableObject 的逻辑更为常见。Proxy 特性在 ES6 引入后,提供了更强大的能力来劫持对象的行为,不仅限于 getter 和 setter,还包括对象的其他行为。
最后,文章总结了使用 Proxy 方案的优点,包括能够更全面地劫持对象的行为,而不仅仅是属性的 getter 和 setter。Proxy 方案在实现双向绑定时,能够提供更灵活和强大的功能。同时,文章也提到了两种方案的局限性,尤其是在处理对象属性的可观察性方面,Proxy 方案在某些情况下可能更具优势。
easylogging源码学习笔记(6)
`LOG` 是默认日志、CLOG自定义日志、LOG_IF条件日志
特殊日志
LOG_EVERY_N、LOG_AFTER_N、LOG_N_TIMES
for (int i = 1; i <= ; ++i) {
LOG_EVERY_N(2, INFO) << "Logged every second iter";
}// 5 logs written; 2, 4, 6, 7,
for (int i = 1; i <= ; ++i) {
LOG_AFTER_N(2, INFO) << "Log after 2 hits; " << i;
}// 8 logs written; 3, 4, 5, 6, 7, 8, 9,
for (int i = 1; i <= ; ++i) {
LOG_N_TIMES(3, INFO) << "Log only 3 times; " << i;
}// 3 logs writter; 1, 2, 3
条件日志和特殊日志可以搭配使用
* `VLOG_IF(condition, verbose-level)`
* `CVLOG_IF(condition, verbose-level, loggerID)`
* `VLOG_EVERY_N(n, verbose-level)`
* `CVLOG_EVERY_N(n, verbose-level, loggerID)`
* `VLOG_AFTER_N(n, verbose-level)`
* `CVLOG_AFTER_N(n, verbose-level, loggerID)`
* `VLOG_N_TIMES(n, verbose-level)`
* `CVLOG_N_TIMES(n, verbose-level, loggerID)`
日志详细等级判定
if (VLOG_IS_ON(2)) {
// Verbosity level 2 is on for this file
}
性能追踪
* `TIMED_FUNC(obj-name)`
* `TIMED_SCOPE(obj-name, block-name)`
* `TIMED_BLOCK(obj-name, block-name)`
这些宏实际上都是关于el::base::type::PerformanceTrackerPtr,一个指向el::base::PerformanceTracker的指针
#if defined(ELPP_FEATURE_ALL) || defined(ELPP_FEATURE_PERFORMANCE_TRACKING)
PerformanceTracker::PerformanceTracker(const std::string& blockName,
base::TimestampUnit timestampUnit,
const std::string& loggerId,
bool scopedLog, Level level) :
m_blockName(blockName), m_timestampUnit(timestampUnit), m_loggerId(loggerId), m_scopedLog(scopedLog),
m_level(level), m_hasChecked(false), m_lastCheckpointId(std::string()), m_enabled(false) {
#if !defined(ELPP_DISABLE_PERFORMANCE_TRACKING) && ELPP_LOGGING_ENABLED
// We store it locally so that if user happen to change configuration by the end of scope
// or before calling checkpoint, we still depend on state of configuration at time of construction
el::Logger* loggerPtr = ELPP->registeredLoggers()->get(loggerId, false);
m_enabled = loggerPtr != nullptr && loggerPtr->m_typedConfigurations->performanceTracking(m_level);
if (m_enabled) {
base::utils::DateTime::gettimeofday(&m_startTime);
}
#endif // !defined(ELPP_DISABLE_PERFORMANCE_TRACKING) && ELPP_LOGGING_ENABLED
}
在构造函数中获取一个时间,
PerformanceTracker::~PerformanceTracker(void) {
#if !defined(ELPP_DISABLE_PERFORMANCE_TRACKING) && ELPP_LOGGING_ENABLED
if (m_enabled) {
base::threading::ScopedLock scopedLock(lock());
if (m_scopedLog) {
base::utils::DateTime::gettimeofday(&m_endTime);
base::type::string_t formattedTime = getFormattedTimeTaken();
PerformanceTrackingData data(PerformanceTrackingData::DataType::Complete);
data.init(this);
data.m_formattedTimeTaken = formattedTime;
PerformanceTrackingCallback* callback = nullptr;
for (const std::pair& h
: ELPP->m_performanceTrackingCallbacks) {
callback = h.second.get();
if (callback != nullptr && callback->enabled()) {
callback->handle(&data);
}
}
}
}
#endif // !defined(ELPP_DISABLE_PERFORMANCE_TRACKING)
}
在析构函数中获取一个时间,处理时间data,使用PerformanceTrackingCallback类型指针callback,并在callback->handle(&data)中处理输出。
由于定义了ELPP_FEATURE_PERFORMANCE_TRACKING,因此在初始化(INITIALIZE_EASYLOGGINGPP)中实际上是安装了一个base::DefaultPerformanceTrackingCallback。
在PerformanceTracker类的handle函数中,callback是一个PerformanceTrackingCallback类型指针,由于安装的是DefaultPerformanceTrackingCallback对象,因此是一个基类指针指向了派生类对象。处理输出的逻辑在DefaultPerformanceTrackingCallback类的handle函数中。
DefaultPerformanceTrackingCallback类的handle函数首先会将数据成员m_data的指针赋值给函数参数,并创建一个base::type::stringstream_t类型的对象ss用于构建输出内容。根据m_data的dataType,输出不同的信息。在输出时,会使用el::base::Writer类构造并输出内容。
EasyLogger源码学习笔记(5)
在EasyLogger源码的学习中,我们了解到日志对象使用了互斥锁以确保同一时刻只有一个线程能进行操作,保证了日志管理的安全性与高效性。
对于异步输出,EasyLogger通过信号量实现了优化。当需要等待执行时,某个线程会被阻塞,以减少CPU的占用。这一特性允许用户单独设置异步输出的日志等级,提高系统的灵活性与可控性。
在文件输出时,使用了信号量集合,其中仅包含一个信号量。这一设计确保了同时只有一个线程能向文件中写入日志,避免了多线程并发写入导致的文件混乱。
日志输出的多样选择体现了EasyLogger的灵活性,无论是输出到文件还是串口,都可以根据需要配置是否采用异步输出,以适应不同的应用场景与性能需求。
此外,sem_post函数用于解锁由semby指定的信号量,执行对特定信号量的解锁操作。而semop函数则用于执行一组预先定义的信号量操作,适用于对多个信号量进行原子性操作。
在信号量集合仅包含一个信号量的情况下,使用sem_post函数进行操作可能直接替代使用semop函数。这一设计简化了信号量管理,提高了代码的可读性和效率。
Vuex 4源码学习笔记 - mapState、mapGetters、mapActions、mapMutations辅助函数原理(六)
在前一章中,我们通过了解Vuex的dispatch功能,逐步探索了Vuex数据流的核心工作机制。通过这一过程,我们对Vuex的整体运行流程有了清晰的把握,为深入理解其细节奠定了基础。本章节,我们将聚焦于Vuex的辅助函数,包括mapState、mapGetters、mapActions、mapMutations以及createNamespacedHelpers,这些函数旨在简化我们的开发流程,使其更符合实际应用需求。
请注意,这些辅助函数在Vue 3的Composition API中不适用,因为它们依赖于组件实例(this),而在Setup阶段,this尚未被创建。因此,它们仅适用于基于选项的Vue 2或Vue 3经典API。
以mapState为例,它允许我们以计算属性的形式访问Vuex中的状态。当组件需要获取多个状态时,通过mapState生成的计算属性可以显著减少代码冗余。若映射的计算属性名称与state子节点名称相同,只需传入字符串数组。此外,通过对象展开运算符,我们能轻松地在已有计算属性中添加新的映射。
深入代码层面,mapState的核心功能在src/helpers.js文件中得以实现。通过normalizeNamespace函数统一处理命名空间和map数据,然后利用normalizeMap函数将数组或对象格式数据标准化,最终返回一个封装后的函数对象。通过这种方式,mapState有效简化了状态访问的实现。
mapGetters、mapMutations、mapActions遵循相似的模式,通过normalizeNamespace统一输入,然后使用normalizeMap统一数据处理,最后返回对象格式的函数集合,支持对象展开运算符的使用。这些函数简化了获取、执行actions和mutations的过程。
createNamespacedHelpers则是为管理命名空间模块提供便利。通过传入命名空间值,它生成一组组件绑定辅助函数,简化了针对特定命名空间的模块操作。此函数通过bind方法巧妙地将namespace参数绑定到返回的函数集合中,实现了高效、灵活的命名空间管理。
本章节对mapState的实现原理进行了深入分析,并展示了其余辅助函数的相似之处。通过理解这些函数的工作机制,我们能更高效地应用Vuex,优化组件间的交互与状态管理。利用这些工具,开发者能够更专注于业务逻辑的实现,而不是繁琐的状态获取和管理。
在探索更多前端知识的旅程中,让我们一起关注公众号小帅的编程笔记,每天更新精彩内容,与编程社区一同成长。
带源的品牌有哪些
带源的品牌包括源码链、源码笔记、车源易找等。解释如下:
源码链
源码链是一个以技术为核心的品牌。主要致力于区块链技术的研发与应用,为各类企业和开发者提供基于区块链的解决方案。品牌名中的“源码”,寓意着其注重技术的本源,追求技术的纯净与原始;而“链”则反映了其在区块链领域的专注和链接价值。这个品牌以其技术实力和创新能力得到了广大开发者和企业的认可。
源码笔记
源码笔记是一家注重知识分享和传承的品牌。它专注于各类源代码的学习和研究,为广大开发者提供有价值的笔记和教程。品牌名中的“源码”反映了其关注源代码的学习和研究领域;而“笔记”则表达了其注重知识的积累和分享。这个品牌以其深入浅出、实用为主的教程赢得了广大开发者的喜爱。
车源易找
车源易找是一家在汽车领域有着广泛影响力的品牌。其主要业务是提供汽车信息服务和车源查找服务。品牌名中的“车源”直接表达了其主要业务领域——汽车;而“易找”则体现了其服务宗旨,即为消费者提供一个简单、快捷的查找车源的平台。这个品牌以其丰富的信息资源和服务赢得了广大消费者的信任。
以上所述的几个带源的品牌,虽然所处领域不同,但它们都以自己的名字准确地反映了自身的业务范围和服务宗旨,从而获得了消费者或用户的广泛认可和信赖。
- 上一条:浙江湖州:开展流通领域食品安全专项行动
- 下一条:浙江长兴:为迎接新学期牢筑安全防线