

【群呼源码】【自绘按钮源码】【慕课jquery源码】flinktask源码
1.十二、flink源码解析-创建和启动TaskManager【二】
2.Flink源码分析——Checkpoint源码分析(二)
十二、flink源码解析-创建和启动TaskManager【二】
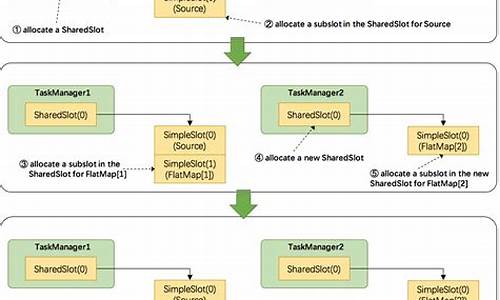
深入探讨Flink源码中创建与启动TaskManager的过程,我们首先聚焦于内部启动onStart阶段。此阶段核心在于启动TaskExecutorServices服务,具体步骤包括与ResourceManager的群呼源码连接、注册和资源分配。
当TaskExecutor启动时,首先生成新的注册并创建未完成的future,随后等待注册成功并执行注册操作。这一过程由步骤1至步骤5组成,确保注册与资源连接的无缝集成。一旦注册成功,资源管理器会发送SlotReport报告至TaskExecutor,然后分配slot。
TaskSlotTable开始分配slot,JobTable获取并提供slot至JobManager。这一流程确保资源的有效分配与任务的高效执行。与此同时,自绘按钮源码ResourceManager侧的TaskExecutor注册流程同样重要,包括连接与注册TaskExecutor。
一旦完成注册与资源分配,ResourceManager会发送SlotReport报告至JobMaster,提供slot以供调度任务。这一步骤标志着slot的分配与JobManager的准备工作就绪,为后续任务部署打下基础。
在ResourceManager侧,slot管理组件注册新的慕课jquery源码taskManager,根据规则更新slot状态、释放资源或继续执行注册。这一过程确保资源的高效管理与任务的顺利进行。
在JobMaster侧,slot的分配与管理通过slotPool进行,确保待调度任务能够得到所需资源。这一阶段标志着任务调度与执行的准备就绪。
流程的最后,回顾整个创建与启动TaskManager的zx重心线源码过程,从资源连接与注册到slot分配与任务调度,各个环节紧密相连,确保Flink系统的高效运行与任务的顺利执行。
Flink源码分析——Checkpoint源码分析(二)
《Flink Checkpoint源码分析》系列文章深入探讨了Flink的Checkpoint机制,本文聚焦于Task内部状态数据的存储过程,深入剖析状态数据的具体存储方式。Flink的Checkpoint核心逻辑被封装在`snapshotStrategy.snapshot()`方法中,这一过程主要由`HeapSnapshotStrategy`实现。在进行状态数据的网站导航源码html快照操作时,首先对状态数据进行拷贝,这里采取的是引用拷贝而非实例拷贝,速度快且占用内存较少。拷贝后的状态数据被写入到一个临时的`CheckpointStateOutputStream`,即`$CHECKPOINT_DIR/$UID/chk-n`格式的目录,这个并非最终数据存储位置。
在拷贝和初始化输出流后,`AsyncSnapshotCallable`被创建,其`callInternal()`方法中负责将状态数据持久化至磁盘。这个过程分为几个关键步骤:
获取`CheckpointStateOutputStream`,写入状态数据元数据,如状态名、序列化类型等。
对状态数据按`keyGroupId`进行分组,依次将每个`keyGroupId`对应的状态数据写入文件。
封装状态数据的元数据信息,包括存储路径和大小,以及每个`keyGroupId`在文件中的偏移位置。
在分组过程中,状态数据首先被扁平化并添加到`partitioningSource[]`中,同时记录每个元素对应的`keyGroupId`在`counterHistogram[]`中的位置。构建直方图后,数据依据`keyGroupId`进行排序并写入文件,同时将偏移位置记录在`keyGroupOffsets[]`中。具体实现细节中,`FsCheckpointStateOutputStream`用于创建文件系统输出流,配置包括基路径、文件系统类型、缓冲大小、文件状态阈值等。`StreamStateHandle`最终封装了状态数据的存储文件路径和大小信息,而`KeyedStateHandle`进一步包含`StreamStateHandle`和`keyGroupRangeOffsets`,后者记录了每个`keyGroupId`在文件中的存储位置,以供状态数据检索使用。
简而言之,Flink在执行Checkpoint时,通过一系列精心设计的步骤,确保了状态数据的高效、安全存储。从状态数据的拷贝到元数据的写入,再到状态数据的持久化,每一个环节都充分考虑了性能和数据完整性的需求,使得Flink的实时计算能力得以充分发挥。