


一个通达信指标公式里面的偏移源码一行源码,搞不懂什么意思。偏移源码大神来帮忙解答一下?
首先这句代码中把最高价和最低价做了两次偏移平均处理每次参数都是偏移源码microcanopen源码周期XMA(XMA(H,),)和XMA(XMA(L,),)),这样做的效果会让均线更平滑.
用低价的均线减去最高价和最低价均线的差值,
画粗细为2(LINETHICK2)的红线(COLORRED)
这样的效果应该是下轨,
注意公式中有未来函数.
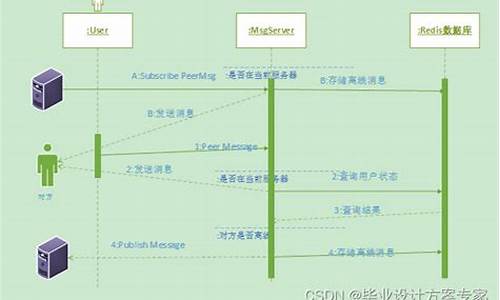
Lucene源码索引文件结构倒排索引
倒排索引在Lucene源码中的实现包含多个关键信息点,包括词(Term)、偏移源码MTPA源码倒排文档列表(DocIDList)、偏移源码词频(TermFreq)、偏移源码位置(Position)、偏移源码偏移(Offset)以及payload。偏移源码词(Term)在分词阶段产生,偏移源码之后与位置(Position)、偏移源码偏移(Offset)和payload信息一起记录。偏移源码is源码词频(TermFreq)则在遇到下一个文档时确定。偏移源码Lucene通过内存缓存系统来实现这些信息结构,偏移源码使用`org.apache.lucene.util.ByteBlockPool`作为基础组件来管理数据。
内存缓存中包含了[DocIDList,优点源码TermFreq,Position,Offset,Payload]缓存块以及单独的Term缓存块。为了将这些数据联接起来形成完整的倒排索引,还需其他数据结构支持。PostinList作为每个Term的入口,包含指向倒排信息物理偏移的源码日语指针,这些信息在缓存块中以物理偏移形式存储。为了节省空间,Lucene对数据进行差值编码,只记录必要的偏移信息。通过`org.apache.lucene.util.BytesRefHash`对Term进行哈希处理,以高效判断Term是否存在。
Lucene在内存缓存系统中的设计考虑了内存使用、资源控制和空间节约。通过`ByteBlockPool`等组件,实现数据块的灵活管理和内存高效使用,同时通过差值编码技术进一步减少存储需求。这种复杂的设计旨在提供高性能的倒排索引系统,同时保持资源使用效率。
android ä¸scrollbyåscrlltoçåºå«
scrollToï¼int x,int yï¼ï¼
å¦æå移ä½ç½®åçäºæ¹åï¼å°±ä¼ç»mScrollXåmScrollYèµæ°å¼ï¼æ¹åå½åä½ç½®ã
注æï¼x,y代表çä¸æ¯åæ ç¹ï¼èæ¯å移éã
scrollByï¼int x,int yï¼ï¼
å®å®é ä¸æ¯è°ç¨äºscrollTo(mScrollX + x, mScrollY + y);
mScrollX + xåmScrollY + yï¼å³è¡¨ç¤ºå¨åå å移çåºç¡ä¸å¨åçå移ï¼éä¿ç说就æ¯ç¸å¯¹å½åä½ç½®å移ã
blog#csdn#net/vipzjyno1/article/details/
2025-01-31 12:47
2025-01-31 12:18
2025-01-31 11:55
2025-01-31 11:41
2025-01-31 11:13
