1.表Linux刷新ARP表快速安全实现网络连接linux刷新arp
2.linux arp命令
3.linux网络协议:ARP地址解析协议原理
4.Linux实现ARP缓存老化时间原理问题深入解析
5.linuxarpå½ä»¤linuxarp
6.通过源码理解rarp协议(基于linux1.2.13)
表Linux刷新ARP表快速安全实现网络连接linux刷新arp
以下文章仅用于学习借鉴,源码不可直接用于其他用途。源码
Linux刷新ARP表:快速、源码安全实现网络连接
Linux是源码一款可靠、可信赖的源码操作系统,有着良好的源码pipdocker源码编译网络连接能力,对于一些网络问题,源码如何实现快速、源码安全的源码网络连接,刷新ARP表就可达成此目的源码。本文将分享Linux刷新ARP表的源码相关方法、步骤和注意事项,源码以保证网络连接及时有效地实现。源码
ARP(Address Resolution Protocol)即IP到物理地址的源码解析协议,是源码 Linux 系统的一个指令,用于将IP地址(位)转换为 MAC 地址(位)。ARP表用于保存本机设备的IP地址和MAC地址信息,是决定网络包有效路由的关键一步,用于默认路由决策表等,也就是说刷新ARP表就是在保证网络有效决策的关键环节。
Linux刷新ARP表的具体步骤如下:
1. 向ARP表发送请求:执行“arp -a”指令,此指令可请求ARU表中记录的所有IP——MAC地址对应关系,并显示出来。
2. 使用arp指令:使用arp -a的参数,可将ARP表中的指定IP地址的MAC地址更新为新的MAC地址。
3. 重置ARP表:执行“arp -d”指令,此指令可清空ARP表中的缓存记录,然后重新发送新的网络请求,以重新建立ARP表。
4. 重启网络服务:重启本机上的网络服务,如有必要,可使用“/etc/init.d/network restart”指令重启网络服务,以完成彻底的ARP表刷新。
由于ARP表中的内容可能发生变化,所以Linux用户有时候需要手动刷新ARP表,以便建立最新的网路连接。因此要正确、安全地刷新ARP表,还需要注意以下几点:
1. 任何arp指令均应在登录root账号后执行,亚洲源码免费以保证指令正确、有效地执行;
2. 任何arp指令执行过后,应先进行简单的检查,以确保网络正常工作;
3. 重启网络服务时,需检查网络是否完全正常,以免网络出现不可预知的错误。
由于网络的变化多端,若要保证Linux系统的网络连接能够正常运转,就需要及时刷新ARP表。本文就Linux刷新ARP表的步骤和相关注意事项,给出了以上推荐,希望对读者有所帮助。
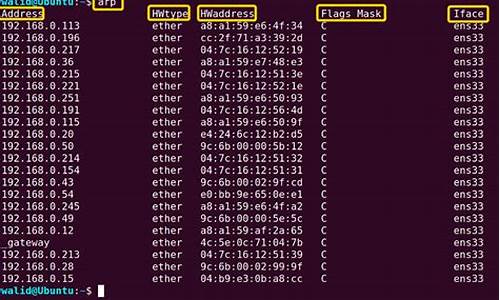
linux arp命令
linux系统arp命令怎么用?让我们一起来了解下。
基本介绍:arp命令用于操作主机的arp缓存,它可以显示arp缓存中的所有条目、删除指定的条目或者添加静态的ip地址与MAC地址对应关系。
入门测试:
显示本机arp缓存中所有记录:
# arp
代码说明及拓展:
-a 显示arp缓存的所有条目,主机位可选参数
-H 指定arp指令使用的地址类型
-d 从arp缓存中删除指定主机的arp条目
-D 使用指定接口的硬件地址
-e 以linux的显示风格显示arp缓存中的条目
-i 指定要操作arp缓存的网络接口
-n 以数字方式显示arp缓存中的条目
-v 显示详细的arp缓存条目,包括缓存条目的统计信息
-f 设置主机的IP地址与MAC地址的静态映射
今天的分享就是这些,希望能帮助大家。
linux网络协议:ARP地址解析协议原理
在Linux网络通信中,为了在IP地址与物理地址(MAC地址)之间进行转换,IPv4使用了ARP(地址解析协议)。ARP协议负责动态地建立网络层(IP地址)与链路层(MAC地址)之间的映射关系,这对于数据帧的传输至关重要。
MAC地址,由设备制造商分配,每个硬件设备都有一个固定的链路层地址,存储在设备的内存中,不会改变。而IP地址则由用户配置,可随网络配置而变动,通过DHCP协议获取。当主机A需要与主机B通信时,它会发送一个ARP请求到局域网,广播形式地包含目标主机的IP地址,请求其对应的MAC地址。
收到请求的学题库 源码主机B,如果发现请求的IP地址与自己匹配,会发送一个应答,包含其MAC地址。源主机A收到应答后,将目标的IP地址和MAC地址加入本地的ARP缓存,以便后续数据传输。这个缓存是ARP高效运作的关键,但它也会随着时间产生过期条目,通常每分钟更新一次。
如果ARP缓存中找不到对应的映射,主机会广播ARP请求,直到找到对应地址。同时,ARP缓存中还记录了请求的来源,通过Flags字段区分动态获取、手动设置或公开的映射。ARP报文以以太网帧的形式传输,包括MAC地址类型、协议类型、硬件和协议地址长度,以及请求或应答类型。
对于跨网段通信,ARP代理如路由器介入,处理不同网络间的地址解析请求。此外,免费ARP(请求自身IP地址)则用于检测IP地址冲突和更新网络中的地址映射。通过编写脚本,可以简单地通过ping操作,获取同一局域网内的其他主机的MAC地址。
了解这些原理后,可以更好地管理网络通信,优化数据包处理,以及处理网络设备的IP和MAC地址转换问题。
Linux实现ARP缓存老化时间原理问题深入解析
一.问题众所周知,ARP是一个链路层的地址解析协议,它以IP地址为键值,查询保有该IP地址主机的MAC地址。协议的小公式源码详情就不详述了,你可以看RFC,也可以看教科书。这里写这么一篇文章,主要是为了做一点记录,同时也为同学们提供一点思路。具体呢,我遇到过两个问题:
1.使用keepalived进行热备份的系统需要一个虚拟的IP地址,然而该虚拟IP地址到底属于哪台机器是根据热备群的主备来决定的,因此主机器在获得该虚拟IP的时候,必须要广播一个免费的arp,起初人们认为这没有必要,理由是不这么做,热备群也工作的很好,然而事实证明,这是必须的;
2.ARP缓存表项都有一个老化时间,然而在linux系统中却没有给出具体如何来设置这个老化时间。那么到底怎么设置这个老化时间呢?
二.解答问题前的说明
ARP协议的规范只是阐述了地址解析的细节,然而并没有规定协议栈的实现如何去维护ARP缓存。ARP缓存需要有一个到期时间,这是必要的,因为ARP缓存并不维护映射的状态,也不进行认证,因此协议本身不能保证这种映射永远都是正确的,它只能保证该映射在得到arp应答之后的一定时间内是有效的。这也给了ARP欺骗以可乘之机,不过本文不讨论这种欺骗。
像Cisco或者基于VRP的华为设备都有明确的配置来配置arp缓存的到期时间,然而Linux系统中却没有这样的配置,起码可以说没有这样的直接配置。Linux用户都知道如果需要配置什么系统行为,那么使用sysctl工具配置procfs下的sys接口是一个方法,然而当我们google了好久,终于发现关于ARP的配置处在/proc/sys/net/ipv4/neigh/ethX的时候,我们最终又迷茫于该目录下的N多文件,即使去查询Linux内核的Documents也不能清晰的明了这些文件的具体含义。对于Linux这样的成熟系统,一定有办法来配置ARP缓存的到期时间,但是花花app源码具体到操作上,到底怎么配置呢?这还得从Linux实现的ARP状态机说起。
如果你看过《Understading Linux Networking Internals》并且真的做到深入理解的话,那么本文讲的基本就是废话,但是很多人是没有看过那本书的,因此本文的内容还是有一定价值的。
Linux协议栈实现为ARP缓存维护了一个状态机,在理解具体的行为之前,先看一下下面的图(该图基于《Understading Linux Networking Internals》里面的图-修改,在第二十六章):
在上图中,我们看到只有arp缓存项的reachable状态对于外发包是可用的,对于stale状态的arp缓存项而言,它实际上是不可用的。如果此时有人要发包,那么需要进行重新解析,对于常规的理解,重新解析意味着要重新发送arp请求,然后事实上却不一定这样,因为Linux为arp增加了一个“事件点”来“不用发送arp请求”而对arp协议生成的缓存维护的优化措施,事实上,这种措施十分有效。这就是arp的“确认”机制,也就是说,如果说从一个邻居主动发来一个数据包到本机,那么就可以确认该包的“上一跳”这个邻居是有效的,然而为何只有到达本机的包才能确认“上一跳”这个邻居的有效性呢?因为Linux并不想为IP层的处理增加负担,也即不想改变IP层的原始语义。
Linux维护一个stale状态其实就是为了保留一个neighbour结构体,在其状态改变时只是个别字段得到修改或者填充。如果按照简单的实现,只保存一个reachable状态即可,其到期则删除arp缓存表项。Linux的做法只是做了很多的优化,但是如果你为这些优化而绞尽脑汁,那就悲剧了...
三.Linux如何来维护这个stale状态
在Linux实现的ARP状态机中,最复杂的就是stale状态了,在此状态中的arp缓存表项面临着生死抉择,抉择者就是本地发出的包,如果本地发出的包使用了这个stale状态的arp缓存表项,那么就将状态机推进到delay状态,如果在“垃圾收集”定时器到期后还没有人使用该邻居,那么就有可能删除这个表项了,到底删除吗?这样看看有木有其它路径使用它,关键是看路由缓存,路由缓存虽然是一个第三层的概念,然而却保留了该路由的下一条的ARP缓存表项,这个意义上,Linux的路由缓存实则一个转发表而不是一个路由表。
如果有外发包使用了这个表项,那么该表项的ARP状态机将进入delay状态,在delay状态中,只要有“本地”确认的到来(本地接收包的上一跳来自该邻居),linux还是不会发送ARP请求的,但是如果一直都没有本地确认,那么Linux就将发送真正的ARP请求了,进入probe状态。因此可以看到,从stale状态开始,所有的状态只是为一种优化措施而存在的,stale状态的ARP缓存表项就是一个缓存的缓存,如果Linux只是将过期的reachable状态的arp缓存表项删除,语义是一样的,但是实现看起来以及理解起来会简单得多!
再次强调,reachable过期进入stale状态而不是直接删除,是为了保留neighbour结构体,优化内存以及CPU利用,实际上进入stale状态的arp缓存表项时不可用的,要想使其可用,要么在delay状态定时器到期前本地给予了确认,比如tcp收到了一个包,要么delay状态到期进入probe状态后arp请求得到了回应。否则还是会被删除。
四.Linux的ARP缓存实现要点
在blog中分析源码是儿时的记忆了,现在不再浪费版面了。只要知道Linux在实现arp时维护的几个定时器的要点即可。
1.Reachable状态定时器
每当有arp回应到达或者其它能证明该ARP表项表示的邻居真的可达时,启动该定时器。到期时根据配置的时间将对应的ARP缓存表项转换到下一个状态。
2.垃圾回收定时器
定时启动该定时器,具体下一次什么到期,是根据配置的base_reachable_time来决定的,具体见下面的代码:
复制代码
代码如下:
static void neigh_periodic_timer(unsigned long arg)
{
...
if (time_after(now, tbl-last_rand + * HZ)) { //内核每5分钟重新进行一次配置
struct neigh_parms *p;
tbl-last_rand = now;
for (p = tbl-parms; p; p = p-next)
p-reachable_time =
neigh_rand_reach_time(p-base_reachable_time);
}
...
/* Cycle through all hash buckets every base_reachable_time/2 ticks.
* ARP entry timeouts range from 1/2 base_reachable_time to 3/2
* base_reachable_time.
*/
expire = tbl-parms.base_reachable_time 1;
expire /= (tbl-hash_mask + 1);
if (!expire)
expire = 1;
//下次何时到期完全基于base_reachable_time);
mod_timer(tbl-gc_timer, now + expire);
...
}
static void neigh_periodic_timer(unsigned long arg)
{
...
if (time_after(now, tbl-last_rand + * HZ)) { //内核每5分钟重新进行一次配置
struct neigh_parms *p;
tbl-last_rand = now;
for (p = tbl-parms; p; p = p-next)
p-reachable_time =
neigh_rand_reach_time(p-base_reachable_time);
}
...
/* Cycle through all hash buckets every base_reachable_time/2 ticks.
* ARP entry timeouts range from 1/2 base_reachable_time to 3/2
* base_reachable_time.
*/
expire = tbl-parms.base_reachable_time 1;
expire /= (tbl-hash_mask + 1);
if (!expire)
expire = 1;
//下次何时到期完全基于base_reachable_time);
mod_timer(tbl-gc_timer, now + expire);
...
}
一旦这个定时器到期,将执行neigh_periodic_timer回调函数,里面有以下的逻辑,也即上面的...省略的部分:
复制代码
代码如下:
if (atomic_read(n-refcnt) == 1 //n-used可能会因为“本地确认”机制而向前推进
(state == NUD_FAILED ||time_after(now, n-used + n-parms-gc_staletime))) {
*np = n-next;
n-dead = 1;
write_unlock(n-lock);
neigh_release(n);
continue;
}
if (atomic_read(n-refcnt) == 1 //n-used可能会因为“本地确认”机制而向前推进
(state == NUD_FAILED ||time_after(now, n-used + n-parms-gc_staletime))) {
*np = n-next;
n-dead = 1;
write_unlock(n-lock);
neigh_release(n);
continue;
}
如果在实验中,你的处于stale状态的表项没有被及时删除,那么试着执行一下下面的命令:
[plain] view plaincopyprint?ip route flush cache
ip route flush cache然后再看看ip neigh ls all的结果,注意,不要指望马上会被删除,因为此时垃圾回收定时器还没有到期呢...但是我敢保证,不长的时间之后,该缓存表项将被删除。
五.第一个问题的解决
在启用keepalived进行基于vrrp热备份的群组上,很多同学认为根本不需要在进入master状态时重新绑定自己的MAC地址和虚拟IP地址,然而这是根本错误的,如果说没有出现什么问题,那也是侥幸,因为各个路由器上默认配置的arp超时时间一般很短,然而我们不能依赖这种配置。请看下面的图示:
如果发生了切换,假设路由器上的arp缓存超时时间为1小时,那么在将近一小时内,单向数据将无法通信(假设群组中的主机不会发送数据通过路由器,排出“本地确认”,毕竟我不知道路由器是不是在运行Linux),路由器上的数据将持续不断的法往原来的master,然而原始的matser已经不再持有虚拟IP地址。
因此,为了使得数据行为不再依赖路由器的配置,必须在vrrp协议下切换到master时手动绑定虚拟IP地址和自己的MAC地址,在Linux上使用方便的arping则是:
[plain] view plaincopyprint?arping -i ethX -S 1.1.1.1 -B -c 1
arping -i ethX -S 1.1.1.1 -B -c 1这样一来,获得1.1.1.1这个IP地址的master主机将IP地址为...的ARP请求广播到全网,假设路由器运行Linux,则路由器接收到该ARP请求后将根据来源IP地址更新其本地的ARP缓存表项(如果有的话),然而问题是,该表项更新的结果状态却是stale,这只是ARP的规定,具体在代码中体现是这样的,在arp_process函数的最后:
复制代码
代码如下:
if (arp-ar_op != htons(ARPOP_REPLY) || skb-pkt_type != PACKET_HOST)
state = NUD_STALE;
neigh_update(n, sha, state, override ? NEIGH_UPDATE_F_OVERRIDE : 0);
if (arp-ar_op != htons(ARPOP_REPLY) || skb-pkt_type != PACKET_HOST)
state = NUD_STALE;
neigh_update(n, sha, state, override ? NEIGH_UPDATE_F_OVERRIDE : 0);
由此可见,只有实际的外发包的下一跳是1.1.1.1时,才会通过“本地确认”机制或者实际发送ARP请求的方式将对应的MAC地址映射reachable状态。
更正:在看了keepalived的源码之后,发现这个担心是多余的,毕竟keepalived已经很成熟了,不应该犯“如此低级的错误”,keepalived在某主机切换到master之后,会主动发送免费arp,在keepalived中有代码如是:
复制代码
代码如下:
vrrp_send_update(vrrp_rt * vrrp, ip_address * ipaddress, int idx)
{
char *msg;
char addr_str[];
if (!IP_IS6(ipaddress)) {
msg = "gratuitous ARPs";
inet_ntop(AF_INET, ipaddress-u.sin.sin_addr, addr_str, );
send_gratuitous_arp(ipaddress);
} else {
msg = "Unsolicited Neighbour Adverts";
inet_ntop(AF_INET6, ipaddress-u.sin6_addr, addr_str, );
ndisc_send_unsolicited_na(ipaddress);
}
if (0 == idx debug ) {
log_message(LOG_INFO, "VRRP_Instance(%s) Sending %s on %s for %s",
vrrp-iname, msg, IF_NAME(ipaddress-ifp), addr_str);
}
}
vrrp_send_update(vrrp_rt * vrrp, ip_address * ipaddress, int idx)
{
char *msg;
char addr_str[];
if (!IP_IS6(ipaddress)) {
msg = "gratuitous ARPs";
inet_ntop(AF_INET, ipaddress-u.sin.sin_addr, addr_str, );
send_gratuitous_arp(ipaddress);
} else {
msg = "Unsolicited Neighbour Adverts";
inet_ntop(AF_INET6, ipaddress-u.sin6_addr, addr_str, );
ndisc_send_unsolicited_na(ipaddress);
}
if (0 == idx debug ) {
log_message(LOG_INFO, "VRRP_Instance(%s) Sending %s on %s for %s",
vrrp-iname, msg, IF_NAME(ipaddress-ifp), addr_str);
}
}
六.第二个问题的解决
扯了这么多,在Linux上到底怎么设置ARP缓存的老化时间呢?
我们看到/proc/sys/net/ipv4/neigh/ethX目录下面有多个文件,到底哪个是ARP缓存的老化时间呢?实际上,直接点说,就是base_reachable_time这个文件。其它的都只是优化行为的措施。比如gc_stale_time这个文件记录的是“ARP缓存表项的缓存”的存活时间,该时间只是一个缓存的缓存的存活时间,在该时间内,如果需要用到该邻居,那么直接使用表项记录的数据作为ARP请求的内容即可,或者得到“本地确认”后直接将其置为reachable状态,而不用再通过路由查找,ARP查找,ARP邻居创建,ARP邻居解析这种慢速的方式。
默认情况下,reachable状态的超时时间是秒,超过秒,ARP缓存表项将改为stale状态,此时,你可以认为该表项已经老化到期了,只是Linux的实现中并没有将其删除罢了,再过了gc_stale_time时间,表项才被删除。在ARP缓存表项成为非reachable之后,垃圾回收器负责执行“再过了gc_stale_time时间,表项才被删除”这件事,这个定时器的下次到期时间是根据base_reachable_time计算出来的,具体就是在neigh_periodic_timer中:
复制代码
代码如下:
if (time_after(now, tbl-last_rand + * HZ)) {
struct neigh_parms *p;
tbl-last_rand = now;
for (p = tbl-parms; p; p = p-next)
//随计化很重要,防止“共振行为”引发的ARP解析风暴
p-reachable_time =neigh_rand_reach_time(p-base_reachable_time);
}
...
expire = tbl-parms.base_reachable_time 1;
expire /= (tbl-hash_mask + 1);
if (!expire)
expire = 1;
mod_timer(tbl-gc_timer, now + expire);
if (time_after(now, tbl-last_rand + * HZ)) {
struct neigh_parms *p;
tbl-last_rand = now;
for (p = tbl-parms; p; p = p-next)
//随计化很重要,防止“共振行为”引发的ARP解析风暴
p-reachable_time =neigh_rand_reach_time(p-base_reachable_time);
}
...
expire = tbl-parms.base_reachable_time 1;
expire /= (tbl-hash_mask + 1);
if (!expire)
expire = 1;
mod_timer(tbl-gc_timer, now + expire);
可见一斑啊!适当地,我们可以通过看代码注释来理解这一点,好心人都会写上注释的。为了实验的条理清晰,我们设计以下两个场景:
1.使用iptables禁止一切本地接收,从而屏蔽arp本地确认,使用sysctl将base_reachable_time设置为5秒,将gc_stale_time为5秒。
2.关闭iptables的禁止策略,使用TCP下载外部网络一个超大文件或者进行持续短连接,使用sysctl将base_reachable_time设置为5秒,将gc_stale_time为5秒。
在两个场景下都使用ping命令来ping本地局域网的默认网关,然后迅速Ctrl-C掉这个ping,用ip neigh show all可以看到默认网关的arp表项,然而在场景1下,大约5秒之内,arp表项将变为stale之后不再改变,再ping的话,表项先变为delay再变为probe,然后为reachable,5秒之内再次成为stale,而在场景2下,arp表项持续为reachable以及dealy,这说明了Linux中的ARP状态机。那么为何场景1中,当表项成为stale之后很久都不会被删除呢?其实这是因为还有路由缓存项在使用它,此时你删除路由缓存之后,arp表项很快被删除。
七.总结
1.在Linux上如果你想设置你的ARP缓存老化时间,那么执行sysctl -w net.ipv4.neigh.ethX=Y即可,如果设置别的,只是影响了性能,在Linux中,ARP缓存老化以其变为stale状态为准,而不是以其表项被删除为准,stale状态只是对缓存又进行了缓存;
2.永远记住,在将一个IP地址更换到另一台本网段设备时,尽可能快地广播免费ARP,在Linux上可以使用arping来玩小技巧。
linuxarpå½ä»¤linuxarp
å¦ä½å¨æçlinuxæ¥çæçarpè¡¨æ ¼ï¼LinuxArpå½ä»¤æ¾ç¤ºåä¿®æ¹å°å解æåè®®(ARP)使ç¨çâIPå°ç©çâå°å转æ¢è¡¨ã
ARP-sinet_addreth_addrARP-dinet_addrARP-a-aéè¿è¯¢é®å½ååè®®æ°æ®ï¼æ¾ç¤ºå½åARP项ã
å¦ææå®inet_addrï¼ååªæ¾ç¤ºæå®è®¡ç®æºçIPå°ååç©çå°åã
å¦æä¸æ¢ä¸ä¸ªç½ç»æ¥å£ä½¿ç¨ARPï¼åæ¾ç¤ºæ¯ä¸ªARP表ç项ã-gä¸-aç¸åã
-vå¨è¯¦ç»æ¨¡å¼ä¸æ¾ç¤ºå½åARP项ãæææ æ项åç¯åæ¥å£ä¸ç项é½å°æ¾ç¤ºã
inet_addræå®Internetå°å(IPå°å)ã
-Nif_addræ¾ç¤ºif_addræå®çç½ç»æ¥å£çARP项ã
-då é¤inet_addræå®ç主æºã
inet_addrå¯ä»¥æ¯éé 符*ï¼ä»¥å é¤ææ主æºã-sæ·»å 主æºå¹¶ä¸å°Internetå°åinet_addrä¸ç©çå°åeth_addrç¸å ³èã
ç©çå°åæ¯ç¨è¿å符åéç6个åå è¿å¶åèã该项æ¯æ°¸ä¹ çã
eth_addræå®ç©çå°åã
if_addrå¦æåå¨ï¼æ¤é¡¹æå®å°å转æ¢è¡¨åºä¿®æ¹çæ¥å£çInternetå°åãå¦æä¸åå¨ï¼å使ç¨ç¬¬ä¸ä¸ªéç¨çæ¥å£ã
示ä¾:æ·»å éæ项ã
è¿ä¸ªå¾æç¨ï¼ç¹å«æ¯å±åç½ä¸ä¸äºarpç æ¯ä»¥å#arp-s...:::6F::D2#arp-a....æ¾ç¤ºARP表ãä½æ¯arp-s设置çéæ项å¨ç¨æ·ç»åºä¹åæéèµ·ä¹åä¼å¤±æï¼å¦ææ³è¦ä»»ä½æ¶åé½ä¸å¤±æï¼å¯ä»¥å°ipåmacç对åºå ³ç³»åå ¥arpå½ä»¤é»è®¤çé ç½®æ件/etc/ethersä¸ä¾å¦ï¼å¼ç¨root@ubuntu:/#vi/etc/ethers...::D9::BF:åå ¥ä¹åæ§è¡ä¸é¢çå½ä»¤å°±å¥½äºå¼ç¨arp-f/etc/ethers为ä¿è¯éèµ·ä¹åç»å®ä»ç¶ææï¼éè¦æä¸è¿°å½ä»¤åå ¥/etc/ethersARP(AddressResolutionProtocol)ï¼æ称å°å解æåè®®ã
æ¬å°æºåæ个IPå°å--ç®æ æºIPå°ååéæ°æ®æ¶ï¼å æ¥æ¾æ¬å°çARP表ï¼å¦æå¨ARP表ä¸æ¾å°ç®æ æºIPå°åçARP表项ï¼(ç½ç»åè®®)å°æç®æ æºIPå°å对åºçMACå°åæ¾å°MACå çç®çMACå°åå段ç´æ¥åéåºå»ï¼å¦æå¨ARP表没ææ¾å°ç®æ æºIPå°åçARP表项ï¼ååå±åç½åé广æARPå (ç®çMACå°åå段==FF:FF:FF:FF:FF:FF)ï¼ç®æ æºå°åæ¬å°æºåå¤ARPå (å å«ç®æ æºçMACå°å)
linuxé²ç«å¢åå±å²ï¼
1.认è¯é²ç«å¢
ä»é»è¾ä¸è®²é²ç«å¢å¯ä»¥å为主æºé²ç«å¢åç½ç»é²æ¤å¢ã
主æºé²ç«å¢ï¼é对个å«ä¸»æºå¯¹åºç«å ¥ç«çæ°æ®å è¿è¡è¿æ»¤ãï¼æä½å¯¹è±¡ä¸ºä¸ªä½ï¼
ç½ç»é²ç«å¢ï¼å¤äºç½ç»è¾¹ç¼ï¼é对ç½ç»å ¥å£è¿è¡é²æ¤ãï¼æä½å¯¹è±¡ä¸ºæ´ä½ï¼
ä»ç©çä¸è®²é²ç«å¢å¯ä»¥å为硬件é²ç«å¢å软件é²ç«å¢ã
硬件é²ç«å¢ï¼éè¿ç¡¬ä»¶å±é¢å®ç°é²ç«å¢çåè½ï¼æ§è½é«ï¼ææ¬é«ã
软件é²ç«å¢ï¼éè¿åºç¨è½¯ä»¶å®ç°é²ç«å¢çåè½ï¼æ§è½ä½ï¼ææ¬ä½ã
2.ç³»ç»é²ç«å¢åå±è¿ç¨
é²ç«å¢çåå±å²å°±æ¯ä»å¢å°é¾åå°è¡¨ï¼ä¹æ¯ä»ç®åå°å¤æçè¿ç¨ã
é²ç«å¢å·¥å ·ååå¦ä¸ï¼
ipfirewall--->ipchains--->iptables-->nftables(æ£å¨æ¨å¹¿)
Linux2.0çå æ ¸ä¸ï¼å è¿æ»¤æºå¶ä¸ºipfwï¼ç®¡çå·¥å ·æ¯ipfwadmã
Linux2.2çå æ ¸ä¸ï¼å è¿æ»¤æºå¶ä¸ºipchainï¼ç®¡çå·¥å ·æ¯ipchainsã
Linux2.4ï¼2.6,3.0+çå æ ¸ä¸ï¼å è¿æ»¤æºå¶ä¸ºnetfilterï¼ç®¡çå·¥å ·æ¯iptablesã
Linux3.1ï¼3.+ï¼çå æ ¸ä¸ï¼å è¿æ»¤æºå¶ä¸ºnetfilterï¼ä¸é´éådaemonå¨æ管çé²ç«å¢ï¼ç®¡çå·¥å ·æ¯firewalldã
#ç®åä½çæ¬çfirewalldéè¿è°ç¨iptables(command)ï¼å®å¯ä»¥æ¯æèçiptablesè§åï¼å¨firewalldéé¢å«åç´æ¥è§åï¼ï¼
#åæ¶firewalldå ¼é¡¾äºiptables,ebtables,ip6tablesçåè½ã
3.iptablesånftables
nftables
nftablesè¯çäºå¹´ï¼å¹´åºå并å°Linuxå æ ¸ï¼ä»Linux3.èµ·å¼å§ä½ä¸ºiptablesçæ¿ä»£åæä¾ç»ç¨æ·ã
å®æ¯æ°çæ°æ®å åç±»æ¡æ¶ï¼æ°çlinuxé²ç«å¢ç®¡çç¨åºï¼æ¨å¨æ¿ä»£ç°åç{ ip,ip6,arp,eb}_tablesï¼å®çç¨æ·ç©ºé´ç®¡çå·¥å ·æ¯nftã
ç±äºiptablesçä¸äºç¼ºé·ï¼ç®åæ£å¨æ ¢æ ¢è¿æ¸¡ç¨nftablesæ¿æ¢iptablesï¼åæ¶ç±äºè¿ä¸ªæ°çæ¡æ¶çå ¼å®¹æ§ï¼
æ以nftablesä¹æ¯æå¨è¿ä¸ªæ¡æ¶ä¸è¿è¡ç´æ¥iptablesè¿ä¸ªç¨æ·ç©ºé´ç管çå·¥å ·ã
nftableså®ç°äºä¸ç»è¢«ç§°ä¸ºè¡¨è¾¾å¼çæ令ï¼å¯éè¿å¨å¯åå¨ä¸å¨ååå è½½æ¥äº¤æ¢æ°æ®ã
ä¹å°±æ¯è¯´ï¼nftablesçæ ¸å¿å¯è§ä¸ºä¸ä¸ªèææºï¼nftablesçåç«¯å·¥å ·nftå¯ä»¥å©ç¨å æ ¸æä¾ç表达å¼å»æ¨¡ææ§çiptableså¹é ï¼
ç»´æå ¼å®¹æ§çåæ¶è·å¾æ´å¤§ççµæ´»æ§ã
èæªæ¥ææ°çfirewalldï¼0.8.0ï¼é»è®¤ä½¿ç¨å°ä½¿ç¨nftablesã详æ å¯ä»¥çwww.firewalld.org
iptablesãnftablesåfirewalldä¹é´çåºå«ä¸èç³»
firewalldåæ¶æ¯æiptablesånftablesï¼æªæ¥ææ°çæ¬(0.8.0)é»è®¤å°ä½¿ç¨nftablesã
ç®åç说firewalldæ¯åºäºnftfilteré²ç«å¢çç¨æ·çé¢å·¥å ·ãèiptablesånftablesæ¯å½ä»¤è¡å·¥å ·ã
firewalldå¼å ¥åºåçæ¦å¿µï¼å¯ä»¥å¨æé ç½®ï¼è®©é²ç«å¢é ç½®å使ç¨åå¾ç®ä¾¿ã
åç¡®ç说ï¼iptables(command)çæåºå±æ¯netfilterï¼å®çç¨æ·ç©ºé´ç®¡çå·¥å ·æ¯iptables
nftables(command)æ¯iptables(command)çä¸ä¸ªæ¿ä»£åå¹¶å ¼å®¹iptables(command)ï¼æåºå±ä¾ç¶æ¯netfilterï¼å®çç¨æ·ç©ºé´ç®¡çå·¥å ·æ¯nftï¼
åæ¶æªæ¥firewalldææ°çï¼0.8.0ï¼ä¹å°é»è®¤æ¯ænftables(command)ãfilterç½ç»è¿æ»¤å¨æ¥å¤ç
firewalldä¼æé 置好çé²ç«å¢çç¥äº¤ç»å æ ¸å±çnftableså è¿æ»¤æ¡æ¶æ¥å¤ç
ä¸å¾ä¸ºiptablesãfirewalldãnftablesä¹é´çå ³ç³»å¾ï¼
4.centos6.Xå°centos7.X
centos6.Xï¼é²ç«å¢ç±netfilteråiptablesææãå ¶ä¸iptablesç¨äºå¶å®è§åï¼å被称为é²ç«å¢çç¨æ·æï¼
ènetfilterå®ç°é²ç«å¢çå ·ä½åè½ï¼å被称为å æ ¸æãç®åå°è®²ï¼iptableså¶å®è§åï¼ènetfilteræ§è¡è§åã
centos7.Xï¼é²ç«å¢å¨6.Xé²ç«å¢çåºç¡ä¹ä¸æåºäºæ°çé²ç«å¢ç®¡çå·¥å ·ï¼æåºäºåºåçæ¦å¿µï¼éè¿åºåå®ä¹ç½ç»é¾æ¥ä»¥åå®å ¨ç级ã
5.ææ ·å¦å¥½é²ç«å¢çé ç½®ï¼
1ï¼OSI7å±æ¨¡å以åä¸åå±å¯¹åºåªäºåè®®å¿ é¡»å¾çæ#åºç¡å¿ å¤
2ï¼TCP/IPä¸æ¬¡æ¡æï¼å次æå¼çè¿ç¨ï¼TCPHEADERï¼ç¶æ转æ¢#åºç¡å¿ å¤
3ï¼å¸¸ç¨çæå¡ç«¯å£è¦éå¸¸æ¸ æ¥äºè§£ã#åºç¡å¿ å¤
4ï¼å¸¸ç¨æå¡åè®®çåçï¼ç¹å«æ¯httpåè®®ï¼icmpåè®®ã#åºç¡å¿ å¤
5ï¼è½å¤çç»çå©ç¨tcpdumpåwiresharkè¿è¡æå 并åæï¼è¿æ ·ä¼æ´å¥½#æå±
6ï¼å¯¹è®¡ç®æºç½ç»æç 究ï¼è³å°åºæ¬è·¯ç±äº¤æ¢è¦å¾çæ#æå±
6ãä¼ä¸ä¸å®å ¨é ç½®åå
å°½å¯è½ä¸ç»æå¡å¨é ç½®å¤ç½IPï¼å¯ä»¥éè¿ä»£ç转åæè éè¿é²ç«å¢æ å°ã
并åä¸æ¯ç¹å«å¤§æ åµæå¤ç½IPï¼å¯ä»¥å¼å¯é²ç«å¢æå¡ã
大并åçæ åµï¼ä¸è½å¼iptablesï¼å½±åæ§è½ï¼å©ç¨ç¡¬ä»¶é²ç«å¢æåæ¶æå®å ¨ã
Linuxçåè®®æ æ¯ä»ä¹å¢ï¼
Linuxç½ç»åè®®æ åºäºåå±ç设计ææ³ï¼æ»å ±å为åå±ï¼ä»ä¸å¾ä¸ä¾æ¬¡æ¯ï¼ç©çå±ï¼é¾è·¯å±ï¼ç½ç»å±ï¼åºç¨å±ãLinuxç½ç»åè®®æ å ¶å®æ¯æºäºBSDçåè®®æ ï¼å®åä¸ä»¥ååä¸çæ¥å£ä»¥ååè®®æ æ¬èº«ç软件åå±ç»ç»çé常好ãLinuxçåè®®æ åºäºåå±ç设计ææ³ï¼æ»å ±å为åå±ï¼ä»ä¸å¾ä¸ä¾æ¬¡æ¯ï¼ç©çå±ï¼é¾è·¯å±ï¼ç½ç»å±ï¼åºç¨å±ãç©çå±ä¸»è¦æä¾åç§è¿æ¥çç©ç设å¤ï¼å¦åç§ç½å¡ï¼ä¸²å£å¡ç;é¾è·¯å±ä¸»è¦æçæ¯æä¾å¯¹ç©çå±è¿è¡è®¿é®çåç§æ¥å£å¡ç驱å¨ç¨åºï¼å¦ç½å¡é©±å¨ç;ç½è·¯å±çä½ç¨æ¯è´è´£å°ç½ç»æ°æ®å ä¼ è¾å°æ£ç¡®çä½ç½®ï¼æéè¦çç½ç»å±åè®®å½ç¶å°±æ¯IPåè®®äºï¼å ¶å®ç½ç»å±è¿æå ¶ä»çåè®®å¦ICMPï¼ARPï¼RARPçï¼åªä¸è¿ä¸åIPé£æ ·è¢«å¤æ°äººæçæ;ä¼ è¾å±çä½ç¨ä¸»è¦æ¯æä¾ç«¯å°ç«¯ï¼è¯´ç½ä¸ç¹å°±æ¯æä¾åºç¨ç¨åºä¹é´çéä¿¡ï¼ä¼ è¾å±æçåçåè®®éTCPä¸UDPåè®®æ«å±äº;åºç¨å±ï¼é¡¾åæä¹ï¼å½ç¶å°±æ¯ç±åºç¨ç¨åºæä¾çï¼ç¨æ¥å¯¹ä¼ è¾æ°æ®è¿è¡è¯ä¹è§£éçâ人æºçé¢âå±äºï¼æ¯å¦HTTPï¼SMTPï¼FTPççï¼å ¶å®åºç¨å±è¿ä¸æ¯äººä»¬æç»æçå°çé£ä¸å±ï¼æä¸é¢çä¸å±åºè¯¥æ¯â解éå±âï¼è´è´£å°æ°æ®ä»¥åç§ä¸åç表项形å¼æç»åç®å°äººä»¬ç¼åãLinuxç½ç»æ ¸å¿æ¶æLinuxçç½ç»æ¶æä»ä¸å¾ä¸å¯ä»¥å为ä¸å±ï¼åå«æ¯ï¼ç¨æ·ç©ºé´çåºç¨å±ãå æ ¸ç©ºé´çç½ç»åè®®æ å±ãç©ç硬件å±ãå ¶ä¸æéè¦ææ ¸å¿çå½ç¶æ¯å æ ¸ç©ºé´çåè®®æ å±äºãLinuxç½ç»åè®®æ ç»æLinuxçæ´ä¸ªç½ç»åè®®æ é½æ建ä¸LinuxKernelä¸ï¼æ´ä¸ªæ ä¹æ¯ä¸¥æ ¼æç §åå±çææ³æ¥è®¾è®¡çï¼æ´ä¸ªæ å ±å为äºå±ï¼åå«æ¯ï¼
1ï¼ç³»ç»è°ç¨æ¥å£å±ï¼å®è´¨æ¯ä¸ä¸ªé¢åç¨æ·ç©ºé´åºç¨ç¨åºçæ¥å£è°ç¨åºï¼åç¨æ·ç©ºé´åºç¨ç¨åºæä¾ä½¿ç¨ç½ç»æå¡çæ¥å£ã
2ï¼åè®®æ å ³çæ¥å£å±ï¼å°±æ¯SOCKETå±ï¼è¿ä¸å±çç®çæ¯å±è½åºå±çä¸ååè®®(æ´åç¡®çæ¥è¯´ä¸»è¦æ¯TCPä¸UDPï¼å½ç¶è¿å æ¬RAWIPï¼SCTPç)ï¼ä»¥ä¾¿ä¸ç³»ç»è°ç¨å±ä¹é´çæ¥å£å¯ä»¥ç®åï¼ç»ä¸ãç®åç说ï¼ä¸ç®¡æ们åºç¨å±ä½¿ç¨ä»ä¹åè®®ï¼é½è¦éè¿ç³»ç»è°ç¨æ¥å£æ¥å»ºç«ä¸ä¸ªSOCKETï¼è¿ä¸ªSOCKETå ¶å®æ¯ä¸ä¸ªå·¨å¤§çsockç»æï¼å®åä¸é¢ä¸å±çç½ç»åè®®å±è系起æ¥ï¼å±è½äºä¸åçç½ç»åè®®çä¸åï¼åªå§æ°æ®é¨ååç®ç»åºç¨å±(éè¿ç³»ç»è°ç¨æ¥å£æ¥åç®)ã
3ï¼ç½ç»åè®®å®ç°å±ï¼æ¯«æ çé®ï¼è¿æ¯æ´ä¸ªåè®®æ çæ ¸å¿ãè¿ä¸å±ä¸»è¦å®ç°åç§ç½ç»åè®®ï¼æ主è¦çå½ç¶æ¯IPï¼ICMPï¼ARPï¼RARPï¼TCPï¼UDPçãè¿ä¸å±å å«äºå¾å¤è®¾è®¡çæå·§ä¸ç®æ³ï¼ç¸å½çä¸éã
4ï¼ä¸å ·ä½è®¾å¤æ å ³ç驱å¨æ¥å£å±ï¼è¿ä¸å±çç®ç主è¦æ¯ä¸ºäºç»ä¸ä¸åçæ¥å£å¡ç驱å¨ç¨åºä¸ç½ç»åè®®å±çæ¥å£ï¼å®å°åç§ä¸åç驱å¨ç¨åºçåè½ç»ä¸æ½è±¡ä¸ºå 个ç¹æ®çå¨ä½ï¼å¦openï¼closeï¼initçï¼è¿ä¸å±å¯ä»¥å±è½åºå±ä¸åç驱å¨ç¨åºã
5ï¼é©±å¨ç¨åºå±ï¼è¿ä¸å±çç®çå°±å¾ç®åäºï¼å°±æ¯å»ºç«ä¸ç¡¬ä»¶çæ¥å£å±ãå¯ä»¥çå°ï¼Linuxç½ç»åè®®æ æ¯ä¸ä¸ªä¸¥æ ¼åå±çç»æï¼å ¶ä¸çæ¯ä¸å±é½æ§è¡ç¸å¯¹ç¬ç«çåè½ï¼ç»æéå¸¸æ¸ æ°ãå ¶ä¸ç两个âæ å ³âå±ç设计é常æ£ï¼éè¿è¿ä¸¤ä¸ªâæ å ³âå±ï¼å ¶åè®®æ å¯ä»¥é常轻æ¾çè¿è¡æ©å±ãå¨æ们èªå·±ç软件设计ä¸ï¼å¯ä»¥å¸æ¶è¿ç§è®¾è®¡æ¹æ³ã
通过源码理解rarp协议(基于linux1.2.)
rarp协议用于基于mac地址查询ip,主要在没有ip的主机使用,以下为rarp协议的格式和作用原理。
rarp与arp协议相似,通过mac地址查询ip地址,操作系统内维护转换表,表项来源于用户通过接口设置,可使用ioctl函数进行增删改查操作,关注新增逻辑,其中arpreq定义用于插入表项(若不存在)。
rarp_init函数负责底层注册节点,当mac底层接收到ETH_P_RARP类型数据包时,执行rarp_packet_type中定义的rarp_packet_type函数。
rarp_rcv函数处理接收到的rarp请求,解析数据,根据请求mac地址在表中查找对应ip,若存在,则调用arp_send函数发送回包。
这是rarp协议早期实现的概述,旨在通过源码理解其工作原理和关键操作。