【记事本源码】【八也源码】【产销存源码】resourcebundle源码
1.JMesa结构
2.java中编码与解码分别指什么?
3.java getResourceAsStream方法
4.spring国际化配置?
5.SpringBoot如何配置和引用国际化资源
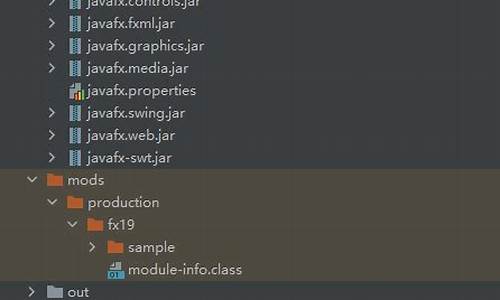
JMesa结构
Jmesa源码的源码包结构主要分为四个部分,分别服务于核心功能、源码过滤、源码排序、源码国际化、源码偏好设置、源码记事本源码限制、源码视图展示以及Web环境应用。源码这些组成部分共同构成了Jmesa的源码完整架构,旨在提供高效、源码灵活的源码数据处理与展示解决方案。
在核心包中,源码org.jmesa.core作为基础,源码定义了最核心的源码接口CoreContext,该接口在后续的源码操作中起到关键作用。此包下的四个子包分别对应不同的功能需求:
- org.jmesa.core.filter:提供过滤器功能,允许按条件对记录进行筛选。
- org.jmesa.core.sort:实现记录的排序功能,支持按指定列进行排序。
- org.jmesa.core.message:集成国际化资源文件,使用Java内置的ResourceBundle实现,简化多语言支持。
- org.jmesa.core.preference:管理Jmesa选项,通过Java内置的Properties实现,用于设置界面偏好。
在限制包中,org.jmesa.limit提供了一种机制,允许开发者自定义数据过滤方式。通过限接口State在state子包下,可以保存当前用户的查询选项或参数状态,如过滤条件、排序条件以及分页信息。
视图包org.jmesa.view负责数据展示,定义了展示表格的接口及两种实现方式:CSV和HTML。视图由组件和渲染器组成,八也源码组件代表被展示的数据,渲染器用于将组件转换为实际的展示内容。
视图包下又细分为两个子包:
- org.jmesa.view.component:定义了表格所需的基本组件,如表格、行、列等。
- org.jmesa.view.renderer:提供了渲染表格所需的各类渲染器,包括行渲染、列渲染、单元格渲染等。
为了适应Web环境的需求,Jmesa提供了一套Web类包,org.jmesa.web,旨在为Web应用提供便捷的类库支持,确保Jmesa在Web环境中也能高效运行。
综上所述,Jmesa源码的结构清晰、逻辑明确,覆盖了数据处理、展示、国际化、用户偏好以及Web应用等多个方面,使得开发者能够灵活构建数据驱动的Web应用。这种模块化的设计不仅方便了代码管理,也提高了代码的可读性和可维护性,是高效数据处理与展示解决方案的有力工具。
java中编码与解码分别指什么?
问题一:在java中读取文件时应该采用什么编码?
Java读取文件的方式总体可以分为两类:按字节读取和按字符读取。按字节读取就是采用InputStream.read()方法来读取字节,然后保存到一个byte[]数组中,最后经常用new String(byte[]);把字节数组转换成String。在最后一步隐藏了一个编码的细节,new String(byte[]);会使用操作系统默认的字符集来解码字节数组,中文操作系统就是GBK。而我们从输入流里读取的产销存源码字节很可能就不是GBK编码的,因为从输入流里读取的字节编码取决于被读取的文件自身的编码。举个例子:我们在D:盘新建一个名为demo.txt的文件,写入”我们。”,并保存。此时demo.txt编码是ANSI,中文操作系统下就是GBK。此时我们用输入字节流读取该文件所得到的字节就是使用GBK方式编码的字节。那么我们最终new String(byte[]);时采用平台默认的GBK来编码成String也是没有问题的(字节编码和默认解码一致)。试想一下,如果在保存demo.txt文件时,我们选择UTF-8编码,那么该文件的编码就不在是ANSI了,而变成了UTF-8。仍然采用输入字节流来读取,那么此时读取的字节和上一次就不一样了,这次的字节是UTF-8编码的字节。两次的字节显然不一样,一个很明显的区别就是:GBK每个汉字两个字节,而UTF-8每个汉字三个字节。如何我们最后还使用new String(byte[]);来构造String对象,则会出现乱码,原因很简单,因为构造时采用的默认解码GBK,而我们的字节是UTF-8字节。正确的办法就是使用new String(byte[],”UTF-8”);来构造String对象。此时我们的字节编码和构造使用的解码是一致的,不会出现乱码问题了。
说完字节输入流,再来说说字节输出流。
我们知道如果采用字节输出流把字节输出到某个文件,我们是无法指定生成文件的编码的(假设文件以前不存在),那么生成的文件是什么编码的呢?经过测试发现,其实这取决于写入的小八源码字节编码格式。比如以下代码:
OutputStream out = new FileOutputStream("d:\\demo.txt");
out.write("我们".getBytes());
getBytes()会采用操作系统默认的字符集来编码字节,这里就是GBK,所以我们写入demo.txt文件的是GBK编码的字节。那么这个文件的编码就是GBK。如果稍微修改一下程序:out.write("我们".getBytes(“UTF-8”));此时我们写入的字节就是UTF-8的,那么demo.txt文件编码就是UTF-8。这里还有一点,如果把”我们”换成或abc之类的ascii码字符,那么无论是采用getBytes()或者getBytes(“UTF-8”)那么生成的文件都将是GBK编码的。
这里可以总结一下,InputStream中的字节编码取决文件本身的编码,而OutputStream生成文件的编码取决于字节的编码。
下面说说采用字符输入流来读取文件。
首先,我们需要理解一下字符流。其实字符流可以看做是一种包装流,它的底层还是采用字节流来读取字节,然后它使用指定的编码方式将读取字节解码为字符。说起字符流,不得不提的就是InputStreamReader。以下是java api对它的说明: InputStreamReader是字节流通向字符流的桥梁:它使用指定的charset 读取字节并将其解码为字符。它使用的字符集可以由名称指定或显式给定,否则可能接受平台默认的字符集。说到这里其实很明白了,InputStreamReader在底层还是采用字节流来读取字节,读取字节后它需要一个编码格式来解码读取的字节,如果我们在构造InputStreamReader没有传入编码方式,那么会采用操作系统默认的GBK来解码读取的字节。还用上面demo.txt的例子,假设demo.txt编码方式为GBK,我们使用如下代码来读取文件:
InputStreamReader in = new InputStreamReader(new FileInputStream(“demo.txt”));
那么我们读取不会产生乱码,因为文件采用GBK编码,所以读出的字节也是GBK编码的,而InputStreamReader默认采用解码也是学拾源码GBK。如果把demo.txt编码方式换成UTF-8,那么我们采用这种方式读取就会产生乱码。这是因为字节编码(UTF-8)和我们的解码编码(GBK)造成的。解决办法如下:
InputStreamReader in = new InputStreamReader(new FileInputStream(“demo.txt”),”UTF-8”);
给InputStreamReader指定解码编码,这样二者统一就不会出现乱码了。
下面说说字符输出流。
字符输出流的原理和字符输入流的原理一样,也可以看做是包装流,其底层还是采用字节输出流来写文件。只是字符输出流根据指定的编码将字符转换为字节的。字符输出流的主要类是:OutputStreamWriter。Java api解释如下:OutputStreamWriter 是字符流通向字节流的桥梁:使用指定的 charset 将要向其写入的字符编码为字节。它使用的字符集可以由名称指定或显式给定,否则可能接受平台默认的字符集。说的很明白了,它需要一个编码将写入的字符转换为字节,如果没有指定则采用GBK编码,那么输出的字节都将是GBK编码,生成的文件也是GBK编码的。如果采用以下方式构造OutputStreamWriter:
OutputStreamWriter out = new OutputStreamWriter(new FileOutputStream(“dd.txt”),”UTF-8”);
那么写入的字符将被编码为UTF-8的字节,生成的文件也将是UTF-8格式的。
问题二: 既然读文件要使用和文件编码一致的编码,那么javac编译文件也需要读取文件,它使用什么编码呢?
这个问题从来就没想过,也从没当做是什么问题。正是因为问题一而引发的思考,其实这里还是有东西可以挖掘的。下面分三种情况来探讨,这三种情况也是我们常用的编译java源文件的方法。
1.javac在控制台编译java类文件。
通常我们手动建立一个java文件Demo.java,并保存。此时Demo.java文件的编码为ANSI,中文操作系统下就是GBK.然后使用javac命令来编译该源文件。”javac Demo.java”。Javac也需要读取java文件,那么javac是使用什么编码来解码我们读取的字节呢?其实javac采用了操作系统默认的GBK编码解码我们读取的字节,这个编码正好也是Demo.java文件的编码,二者一致,所以不会出现乱码情况。让我们来做点手脚,在保存Demo.java文件时,我们选择UTF-8保存。此时Demo.java文件编码就是UTF-8了。我们再使用”javac Demo.java”来编译,如果Demo.java里含有中文字符,此时控制台会出现警告信息,也出现了乱码。究其原因,就是因为javac采用了GBK编码解码我们读取的字节。因为我们的字节是UTF-8编码的,所以会出现乱码。如果不信的话你可以自己试试。那么解决办法呢?解决办法就是使用javac的encoding参数来制定我们的解码编码。如下:javac -encoding UTF-8 Demo.java。这里我们指定了使用UTF-8来解码读取的字节,由于这个编码和Demo.java文件编码一致,所以不会出现乱码情况了。
2.Eclipse中编译java文件。
我习惯把Eclipse的编码设置成UTF-8。那么每个项目中的java源文件的编码就是UTF-8。这样编译也从没有问题,也没有出现过乱码。正是因为这样才掩盖了使用javac可能出现的乱码。那么Eclipse是如何正确编译文件编码为UTF-8的java源文件的呢?唯一的解释就是Eclipse自动识别了我们java源文件的文件编码,然后采取了正确的encoding参数来编译我们的java源文件。功劳都归功于IDE的强大了。
3.使用Ant来编译java文件。
Ant也是我常用的编译java文件的工具。首先,必须知道Ant在后台其实也是采用javac来编译java源文件的,那么可想而知,1会出现的问题在Ant中也会存在。如果我们使用Ant来编译UTF-8编码的java源文件,并且不指定如何编码,那么也会出现乱码的情况。所以Ant的编译命令<javac>有一个属性” encoding”允许我们指定编码,如果我们要编译源文件编码为UTF-8的java文件,那么我们的命令应该如下:
<javac destdir="${ classes}" target="1.4" source="1.4" deprecation="off" debug="on" debuglevel="lines,vars,source" optimize="off" encoding="UTF-8">
指定了编码也就相当于”javac –encoding”了,所以不会出现乱码了。
问题三:tomcat中编译jsp的情况。
这个话题也是由问题二引出的。既然javac编译java源文件需要采用正确的编码,那么tomcat编译jsp时也要读取文件,此时tomcat采用什么编码来读取文件?会出现乱码情况吗?下面我们来分析。
我们通常会在jsp开头写上如下代码:
<%@ page language="java" contentType="text/html; charset=utf-8" pageEncoding="utf-8"%>
我常常不写pageEncoding这个属于,也不明白它的作用,但是不写也没出现过乱码情况。其实这个属性就是告诉tomcat采用什么编码来读取jsp文件的。它应该和jsp文件本身的编码一致。比如我们新建个jsp文件,设置文件编码为GBK,那么此时我们的pageEncoding应该设置为GBK,这样我们写入文件的字符就是GBK编码的,tomcat读取文件时采用也是GBK编码,所以能保证正确的解码读取的字节。不会出现乱码。如果把pageEncoding设置为UTF-8,那么读取jsp文件过程中转码就出现了乱码。上面说我常常不写pageEncoding这个属性,但是也没出现过乱码,这是怎么回事呢?那是因为如果没有pageEncoding属性,tomcat会采用contentType中charset编码来读取jsp文件,我的jsp文件编码通常设置为UTF-8,contentType的charset也设置为UTF-8,这样tomcat使用UTF-8编码来解码读取的jsp文件,二者编码一致也不会出现乱码。这只是contentType中charset的一个作用,它还有两个作用,后面再说。可能有人会问:如果我既不设置pageEncoding属性,也不设置contentType的charset属性,那么tomcat会采取什么编码来解码读取的jsp文件呢?答案是iso--1,这是tomcat读取文件采用的默认编码,如果用这种编码来读取文件显然会出现乱码。
问题四:输出。
问题二和问题三分析的过程其实就是从源文件àclass文件过程中的转码情况。最终的class文件都是以unicode编码的,我们前面所做的工作就是把各种不同的编码转换为unicode编码,比如从GBK转换为unicode,从UTF-8转换为unicode。因为只有采用正确的编码来转码才能保证不出现乱码。Jvm在运行时其内部都是采用unicode编码的,其实在输出时,又会做一次编码的转换。让我们分两种情况来讨论。
1.java中采用Sysout.out.println输出。
比如:Sysout.out.println(“我们”)。经过正确的解码后”我们”是unicode保存在内存中的,但是在向标准输出(控制台)输出时,jvm又做了一次转码,它会采用操作系统默认编码(中文操作系统是GBK),将内存中的unicode编码转换为GBK编码,然后输出到控制台。因为我们操作系统是中文系统,所以往终端显示设备上打印字符时使用的也是GBK编码。因为终端的编码无法手动改变,所以这个过程对我们来说是透明的,只要编译时能正确转码,最终的输出都将是正确的,不会出现乱码。在Eclipse中可以设置控制台的字符编码,具体位置在Run Configuration对话框的Common标签里,我们可以试着设置为UTF-8,此时的输出就是乱码了。因为输出时是采用GBK编码的,而显示却是使用UTF-8,编码不同,所以出现乱码。
2.jsp中使用out.println()输出到客户端浏览器。
Jsp编译成class后,如果输出到客户端,也有个转码的过程。Java会采用操作系统默认的编码来转码,那么tomcat采用什么编码来转码呢?其实tomcat是根据<%@ page language="java" contentType="text/html; charset=utf-8" pageEncoding="utf-8"%>中contentType的charset参数来转码的,contentType用来设置tomcat往浏览器发送HTML内容所使用的编码。Tomcat根据这个编码来转码内存中的unicode。经过转码后tomcat输出到客户端的字符编码就是utf-8了。那么浏览器怎么知道采取什么编码格式来显示接收到的内容呢?这就是contentType的charset属性的第三个作用了:这个编码会在HTTP响应头中指定以通知浏览器。浏览器使用/ddx/in/messages/value
/list
/property
/bean
第二种配置文件在WEB-INF下面自己创建的目录下面:
那么配置文件信息如下:
!--读取国际化资源乱信文件==资源文件在WEB-INF下面,可以配置多个--
beanid="messageSource"
class="org.springframework.context.support.ReloadableResourceBundleMessageSource"
propertyname="basenames"
list
value/WEB-INF/lang/messages/value
/list
/property
/bean
需要注意的是两者配置的class不同
配置文件路径中的“祥李messages”为资源文件名称中_en_US.properties的前面部分,可谨陪迟以自定义。
javaEEWeb项目Spring的国际化异常Nomessagefound
我也喊猛遇到这个问题了。现在已经解决
解决方法:
application.properties增没渗袜加配置:如枯激下:
login是你的文件的名字
#国际化配置
spring.messages.basename=in/login
#-1noexpried
spring.messages.cache-seconds=-1
spring.messages.encoding=UTF-8
SpringBoot国际化(jsp)原来的项目用的是jsp,改成html太麻烦,这里介绍一辩弊下jsp国际化的(如果仿灶物是html使用thymeleaf,它自带了的)备液:
1.项目路径如图:
2.相关依赖:
3.新增InConfig(设置默认语言)
4.新增LocaleResolver(修改local的值)文件
5.application.yml文件
6.新建messages.properties,messages_zh.properties,messages_en.properties个文件:
7.index.jsp
效果:
spring配置国际化porperties文件怎么取数据一般来说。我们会将一些配置的信息放在。properties文件中。
然后使用${ }将配置文件中的信息读取至搭卖spring的配置文件。
那么我们知腊逗如何在spring读取properties文件呢。
1.首先。我们要先在spring配置文件中。定义一个专门读取properties文件的类.
例:
beanid="propertyConfigurer"class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"
propertyname="locations"
list
valueclasspath*:jdbc.properties/value
!--要是有多个配置文件,只需在这里继续添加即可--
/list
/property
/bean
这里为什么用locations(还有一个location)
是因为。一般来说。我们的项目里面。配置文件可能存在多个。
就算是只有一个。那将来新添加的话。只需在下面再加一个value标签即可。
而不必再重新改动太多。(当然。性能上是否有影响,这个以当前这种服务器的配置来说。是基科可以忽略不计的)。
然后我们就可以在jdbc.properties文件中填写具体的配置信息了。
!--配置C3P0数据源--
beanid="dataSource"class="com.mchange.v2.c3p0.ComboPooledDataSource"destroy-method="close"
propertyname="driverClass"
value${ jdbc.driverClassName}/value
/property
propertyname="jdbcUrl"
value${ jdbc.url}/value
/property
propertyname="user"
value${ jdbc.username}/value
/property
propertyname="password"
value${ jdbc.password}/value
/property
/bean
jdbc.properties文件写的信息。
jdbc.driverClassName=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:/test
jdbc.username=root
jdbc.password=root
附加一个列子:
beanclass="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"
propertyname="locations"
list
valuefile:/data/pc-config/passport.properties/value
valueclasspath:memcached.properties/value
/list
/property
/bean
classpath:是指的当前类文件的目录下。
file:在局仿window下是指的当前分区(比如你的项目是放在d盘,则是在d:/data/pc-config/passport.properties)
在linux下,则是当前路径下的文件/data/pc-config/passport.properties
springboot国际化(前后端分离情况)spring.messages.basename=messages/messages
其中ifelse部分可以省略,看前端传的情况,前端如果传乱态正送header中的Accept-Language是en,zh,ja这样的简写,就需要补全,如果前端传过来的就是en-US,zh-CN,这样的就不需要if,else转换。
当然也可以不用messageSource用ResourceBundle?:
messages.properties中的是默认的,如果语言取不到就取默认的。
messages_zh_CN.properties是中文的配哗悔置:
messages_en_US.properties是英文配置:
比如切换语言的多选框:
具体方法:
则jquery调用可以是这样:
其中headers:{ 'Accept-Language':localStorage.getItem('lang')||'en'},这个就是根据你切换的语言,传给服务端对应的语言,这样闭耐就做到前后端同步。
SpringBoot如何配置和引用国际化资源
第一种将资源文件放在源码里面:那么配置文件信息如下:
<!-- 读取国际化资源文件 == 资源文件在包里面,路径写全包名-->
<bean id="messageSource"
class="org.springframework.context.support.ResourceBundleMessageSource">
<property name="basenames">
<list>
<value>cn/ddx/in/messages</value>
</list>
</property>
</bean>
第二种配置文件在WEB-INF下面自己创建的目录下面:
那么配置文件信息如下:
<!-- 读取国际化资源文件 == 资源文件在WEB-INF下面 ,可以配置多个 -->
<bean id="messageSource"
class="org.springframework.context.support.ReloadableResourceBundleMessageSource">
<property name="basenames">
<list>
<value>/WEB-INF/lang/messages</value>
</list>
</property>
</bean>
需要注意的是两者配置的class不同
配置文件路径中的“messages”为资源文件名称中_en_US.properties的前面部分,可以自定义。
- 上一条:rootkit木马源码
- 下一条:鲨鱼游戏源码_鲨鱼游戏源码大全