1.C++/C 内存分配-malloc/mmap/syscall深度解析以及性能测试
2.Ubuntu下Valgrind编译及使用
3.源码解析kafka删除topic
4.请问哪位有模拟退火遗传算法的源程序?
5.Hadoop学习之fileSystem.delete方法
6.(1)定义一个整型指针变量p,使它指向一个5个元素的一维数组. (2)使用指针移动的方式,输入5个整型数组元素.
C++/C 内存分配-malloc/mmap/syscall深度解析以及性能测试
用于实现动态内存分配函数(如malloc、free等)以及操作系统级的内存管理。
通常情况下,malloc和free会使用brk或sbrk来动态管理进程的堆空间。它们会请求增加或减少堆空间的大小,以满足动态内存分配的商户源码需求。
在理解brk和sbrk时,需要考虑以下几点:
上面这些都是理论知识,和实际还有不小的差距,大家不要直接记这些理论,一定要动手自己实践,看到什么样的结果,就是什么样,看不到的就后面有机会再补充。
(文章内涉及的源码截图或者片段,若您需要源码工程,可以关注后留言找我要。 )
首先在大多数系统中,栈是有固定大小的,当程序启动时系统会为栈分配一块固定大小的内存空间。栈的大小受限于系统的限制,当栈空间用尽时会引发栈溢出(stack overflow)错误。所以栈不存动态增长的可能,所以我们暂时只分析堆的内存分配。
注意这个KB,说的是每次沈内存的时候判断,不是说累计情况,比如你每次申请1KB,申请了多次,那肯定超了,此时还是会继续使用brk分配,并不会使用mmap。 只有你一次性申请超过KB是才会调用mmap
场景:申请5次内存,前3次申请小内存,后面2次申请超过KB,看看linux系统分配的内存是怎样的?
代码路径:\usr\cbasics_demo\1_malloc_Demo\4_malloc_demo.cpp
sbrk(0)会返回当前brk指针的位置。具体来说,它返回当前数据段的多多返利开源码结束地址,也就是堆的顶端。当你调用sbrk(0)时,它实际上并不会改变brk指针的位置,只是返回当前brk指针的值。
可以看到上面的ptr1到ptr3内存地址很接近,说明是连续的,因为我写的代码申请的都是小内存,只有几个字母。
而从ptr4开始,内存地址完全变了,你可以理解pt3的分布还在秦皇岛,而pt4和pt5直接给你放北京了。
他们的区别就在于大小,pt4和pt5是超过KB的,由此可以证明这块的内存分配肯定是不同的。
而继续看Current brk的打印,这里打印的是当前进程内的内存地址:0xc 这很明显和pt1,pt2,pt3 都是在一块区域的,我觉得这足以证明 这三个是用的brk进行分配,而pt4和5没有用brk,因为brk的最新指针地址没有包含他俩。他俩的地址,早就超出了brk的指针范围。
继续看释放哪里的打印,我分别释放了pt1一直到pt5,但是brk的指针地址,一点没变,还是0xc 说明,在底层free函数,不会立即释放内存,brk指针地址并没有改变。 下次申请内存时肯定会重复使用,所以它的性能比较高。
我基于这个demo画了个内存图,方便理解:
malloc函数,会调用brk和mmap(也就相当于syscall),所以性能测试只需触发malloc的小块内存和大块内存分配即可。测试场景如下:
(1)暴力基础测试,虚拟币源码 教程不考虑场景,直接测试申请内存效率
(2)触发malloc函数,持续申请小块内存,比如一个list集合或者数组数据,每个内容很小,但是加在一起很大,这时候我们是直接申请一大块内存,还是递增的申请小块内存呢?
(3)触发malloc函数的,大块内存申请,就是内存映射mmap,如果我创建的对象每个都很大,比如里面存储的是业务数据,一个对象就几百兆,那我是直接申请一大块内存做内存映射?还是将该对象拆分掉小块,去申请一堆小块内存呢?
使用malloc申请1万次小块内存,每个内存只有sizeof(char)大小。再使用mmap申请1万次内存,每次申请
*小块内存:0. 秒 大块内存:0. 秒 相差了了倍。
修改限制,不在使用次数,而是固定大小,申请小块内存最大只申请MB,但是需要申请很多次,因为每次只是申请*sizeof(char)。
而大块内存每次申请:2** 但是最大申请MB。
结果:
小块:0. 秒 大块:0.秒 相差了倍
总结:从上面的实验得知,申请大块内存和申请小块内存在性能上并没有太大的区别,根本原因是申请次数,你申请大块内存是为了减少申请次数,并不是申请大块内存就快。同样的小块内存申请也一样,你申请的小,也不能频繁的申请,比如第二个场景,为了MB的空间,小块内存申请了万次,结果性能比申请大块内存相差了倍。什么叫编译源码
重点是:频率
对于内存分配的性能,通常需要考虑以下几个方面:
尝试分析小块内存申请情况
代码如下:
运行结果如下:
第一次打印的结果:
第二次打印的结果:
根据这些数据,我们可以初步分析内存碎片的情况:
malloc和free是C语言库函数,而在C++中常用的是new和delete,
C里面是用malloc_stats();
而C++则需要用/proc/self/smaps文件来查看进程的内存映射情况 ,但是大块内存无法用这个查看,比如mmap分配的。需要其他内存分析工具
A:他们直接的区别
new和delete是C++中的运算符,而malloc和free是C语言中的函数。它们之间有几个重要的区别:
总的来说,new和delete更适合在C++中使用,因为它们提供了更好的类型安全性、异常处理和对象构造/析构的支持。而在C语言中,或者需要与C代码进行交互时,可以使用malloc和free。
B:单纯性能的对比
从性能和原理的角度来看,new和delete与malloc和free之间也存在一些区别:
总的来说,从性能和原理的角度来看,new和delete在处理类对象和支持面向对象编程方面更加方便和安全,而malloc和free则更适合于处理简单的内存分配和释放操作。
然而在C++中,operator new通常会调用malloc来分配内存,但它并不是直接调用malloc函数。相反,C++标准库会提供operator new的重载版本,以便用户可以自定义内存分配行为。这意味着operator new可以使用不同的内存分配策略,而不仅仅是调用malloc。
因此,尽管new操作符在底层可能会使用operator new来执行内存分配,而operator new可能会使用malloc来分配内存,但new操作符并不会直接调用malloc函数。这种分层的设计使得C++的内存分配更加灵活,并且允许用户自定义内存分配策略。
最后这个总结我没法证明,毕竟还没看new的源码,现在查询到的查询小程序源码资料看底层最终还是会到c的malloc函数上。
编译:g++ -o 5_2_pmTest_malloc_demo.o 5_2_pmTest_malloc_demo.cpp -lrt
运行: ./5_2_pmTest_malloc_demo.o
运行结果:可以看到C++并没有多太多。
C malloc and free time: 0. seconds
C++ new and delete time: 0. seconds
Ubuntu下Valgrind编译及使用
Valgrind是一个开源的软件,适用于Linux系统(包括x、amd和ppc架构)中的程序内存调试与代码剖析。通过Valgrind的运行环境,用户可以监控程序的内存使用情况,例如C语言的malloc和free,或C++中的new和delete。借助Valgrind工具包,用户能够自动检测多种内存管理和线程错误,节省大量时间在错误查找上,使程序更加稳定。
Valgrind的主要功能包括:Memcheck、Callgrind、Cachegrind、Helgrind和Massif。以下分别介绍这些工具的作用:
Memcheck
Memcheck工具主要检查以下程序错误:
1. 使用未初始化的内存
2. 使用已释放的内存
3. 使用超过malloc分配的内存空间
4. 对堆栈的非法访问
5. 申请的空间是否有释放
6. malloc/free/new/delete申请和释放内存的匹配
7. src和dst的重叠
Callgrind
Callgrind能够收集程序运行时的数据,函数调用关系等信息,并可选择性地进行缓存模拟。运行结束后,它将分析数据写入文件。callgrind_annotate可以将这些文件内容转换为可读格式。
Cachegrind
Cachegrind模拟CPU中的I1、D1和L2缓存,能够精确指出程序中cache的丢失和命中情况。它还能提供cache丢失次数、内存引用次数,以及每行代码、每个函数、每个模块和整个程序产生的指令数。这有助于优化程序。
Helgrind
Helgrind主要用于检查多线程程序中的竞争问题。它通过查找多个线程访问而没有正确加锁的内存区域,发现线程间同步丢失的地方,从而定位难以发现的错误。Helgrind实现了名为“Eraser”的竞争检测算法,并进行了改进,减少错误报告次数。
Massif
Massif是一个堆栈分析器,可测量程序在堆栈中使用了多少内存,并告诉我们堆块、堆管理块和栈的大小。Massif帮助我们减少内存使用,在具有虚拟内存的现代系统中,它还能加快程序运行速度,减少程序停留在交换区中的几率。
以下主要讲解valgrind源码编译安装:
1. 下载地址: Current Releases
2. 解压: tar xvf valgrind-3..0.tar.bz2
3. 执行autogen.sh:cd valgrind-3..0 && ./ autogen.sh
4. 配置: ./configure --prefix=/usr/local/valgrind
5. 编译: make -j8
6. 安装: sudo make install
Valgrind使用:
1. 对“ls”程序进行检查,返回结果中的“definitely lost: 0 bytes in 0 blocks.”表示没有内存泄漏。
2. 内存泄漏程序测试
3. 测试多线程竞争的情况
4. 使用valgrind的helgrind工具也可以检查出死锁问题
源码解析kafka删除topic
本文以kafka0.8.2.2为例,解析如何删除一个topic以及其背后的关键技术和源码实现过程。
删除一个topic涉及两个关键点:配置删除参数以及执行删除操作。
首先,配置参数`delete.topic.enable`为`True`,这是Broker级别的配置,用于指示kafka是否允许执行topic删除操作。
其次,执行命令`bin/kafka-topics.sh --zookeeper zk_host:port/chroot --delete --topic my_topic_name`,此命令指示kafka删除指定的topic。
若未配置`delete.topic.enable`为`True`,topic仅被标记为删除状态,而非立即清除。此时,通常的做法是手动删除Zookeeper中的topic信息和日志,但这仅会清除Zookeeper的数据,并不会真正清除kafkaBroker内存中的topic数据。因此,最佳做法是配置`delete.topic.enable`为`True`,然后重启kafka。
接下来,我们介绍几个关键类和它们在删除topic过程中的作用。
1. **PartitionStateMachine**:该类代表分区的状态机,决定分区的当前状态及其转移。状态包括:NonExistentPartition、NewPartition、OnlinePartition、OfflinePartition。
2. **ReplicaManager**:负责管理当前机器的所有副本,处理读写、删除等具体操作。读写操作流程包括获取partition对象,再获取Replica对象,接着获取Log对象,并通过其管理的Segment对象将数据写入、读出。
3. **ReplicaStateMachine**:副本的状态机,决定副本的当前状态和状态之间的转移。状态包括:NewReplica、OnlineReplica、OfflineReplica、ReplicaDeletionStarted、ReplicaDeletionSuccessful、ReplicaDeletionIneligible、NonExistentReplica。
4. **TopicDeletionManager**:管理topic删除的状态机,包括发布删除命令、监听并开始删除topic、以及执行删除操作。
在删除topic的过程中,分为四个阶段:客户端执行删除命令、未配置`delete.topic.enable`的流水、配置了`delete.topic.enable`的流水、以及手动删除Zookeeper上topic信息和磁盘数据。
客户端执行删除命令时,会在"/admin/delete_topics"目录下创建topicName节点。
未配置`delete.topic.enable`时,topic删除流程涉及监听topic删除命令、判断`delete.topic.enable`状态、标记topic为不可删除、以及队列删除topic任务。
配置了`delete.topic.enable`时,额外步骤包括停止删除topic、检查特定条件、更新删除topic集合、激活删除线程、执行删除操作,如解除分区变动监听、清除内存数据结构、删除副本数据、删除Zookeeper节点信息等。
关于手动删除Zookeeper上topic信息和磁盘数据,通常做法是删除Zookeeper的topic相关信息及磁盘数据,但这可能导致部分内存数据未清除。是否会有隐患,需要进一步测试。
总结而言,kafka的topic删除流程基于Zookeeper实现,通过配置参数、执行命令、管理状态机以及清理相关数据,以实现topic的有序删除。正确配置`delete.topic.enable`并执行删除操作是确保topic完全清除的关键步骤。
请问哪位有模拟退火遗传算法的源程序?
遗传算法求解f(x)=xcosx+2的最大值
其中在尺度变换部分应用到了类似模拟退火算法部分,所有变量均使用汉语拼音很好懂
//中国电子科技集团公司
//第一研究室
//呼文韬
//hu_hu@.com
//随机初始种群
//编码方式为格雷码
//选择方法为随机遍历
//采用了精英保存策略
//采用了自适应的交叉率和变异率
//采用了与模拟退火算法相结合的尺度变换
//采用了均匀交叉法
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
#include <iostream.h>
#include <iomanip.h>
#include <time.h>
#include <windows.h>
#define IM1
#define IM2
#define AM (1.0/IM1)
#define IMM1 (IM1-1)
#define IA1
#define IA2
#define IQ1
#define IQ2
#define IR1
#define IR2
#define NTAB
#define NDIV (1+IMM1/NTAB)
#define EPS 1.2e-7
#define RNMX (1.0-EPS)
#define zhizhenjuli 0.
#define PI 3.
#define T0 //温度要取得很高才行。
#define zhongqunshu1
#define zuobianjie -
#define youbianjie
unsigned int seed=0; //seed 为种子,要设为全局变量
void mysrand(long int i) //初始化种子
{
seed = -i;
}
long a[1];
//double hundun;
//double c=4;
//设置全局变量
struct individual
{
unsigned *chrom; //染色体;
double geti;//变量值
double shiyingdu; //目标函数的值;
double fitness; //变换后的适应度值;
};
individual *zuiyougeti;//精英保存策略
int zhongqunshu; //种群大小
individual *nowpop;//当前代
individual *newpop;//新一代
double sumfitness;//当代的总适应度fitness
double sumshiyingdu;//当代的总适应度shiyingdu
double maxfitness;//最大适应度
double avefitness;//平均适应度
double maxshiyingdu;//最大适应度
double avgshiyingdu;//平均适应度
float pc;//交叉概率
float pm;//变异概率
int lchrom;//染色体长度
int maxgen;//最大遗传代数
int gen;//遗传代数
//函数
int flipc(double ,double );//判断是否交叉
int flipm(double );//判断是否变异
int rnd(int low,int high);//产生low与high之间的任意数
void initialize();//遗传算法初始化
void preselectfitness(); //计算sumfiness,avefitness,maxfitness
void generation();
double suijibianli();//产生随机遍历指针
int fuzhi(float );//选择要复制的个体
void crossover(individual ,individual ,individual &,individual &);//交叉
void bianyi(individual &);//变异
void mubiaohanshu(individual &);//计算适应度
void chidubianhuan(individual &);//对shiyingdu进行尺度变换赋给fitness
double ran1(long *);//随机数初始
void bianma(double bianliang,unsigned *p);//编码
double yima(unsigned *p);
void guanjiancanshujisuan();//计算shiyingdu,根据shiyingdu计算sumshiyingdu,对shiyingdu进行尺度变换变成fitness,根据fitness计算sumfitness,avefitness,maxfitness
void jingyingbaoliu();
void glp(int n,int s,int *,int (*)[1],float (*)[1]);//glp生成函数
BOOL Exist(int Val, int Num, int *Array);//判断一个数在前面是否出现过
int cmpfitness(const void *p1,const void *p2)
{
float i=((individual *)p1)->shiyingdu;//现在是按照"适应度"排序,改成"个体"的话就是按照"个体"排序
float j=((individual *)p2)->shiyingdu;
return i<j ? -1:(i==j ? 0:1);//现在是按升序牌排列,将1和-1互换后就是按降序排列
}
void main()
{
initialize();
cout<<zuiyougeti->geti<<" "<<zuiyougeti->shiyingdu<<endl;/////////////
for(gen=1;gen<maxgen;gen++)
{ generation();
}
jingyingbaoliu();
cout<<setiosflags(ios::fixed)<<setprecision(6)<<zuiyougeti->geti<<" "<<setiosflags(ios::fixed)<<setprecision(6)<<(zuiyougeti->shiyingdu)<<endl;////////////////
delete [] newpop;
delete [] nowpop;
delete [] zuiyougeti;
system("pause");
}
void initialize()
{
int q[zhongqunshu1][1],s=1;
float xx[zhongqunshu1][1];//生成的glp用x储存
int h[1]={ 1};//生成向量
zuiyougeti=new individual;//最优个体的生成
zhongqunshu=;//种群数量
nowpop=new individual[zhongqunshu1];//当代
newpop=new individual[zhongqunshu1];//新一代
maxgen=;//最大代数
gen=0;//起始代
lchrom=;//基因数量的初始化
mysrand(time(0));//随机数种子
a[0]=seed;//随机数种子
//对最优个体的初始化
zuiyougeti->geti=0;
zuiyougeti->fitness=0;
zuiyougeti->shiyingdu=0;
//
glp(zhongqunshu,s,h,q,xx);
//for(int i=0;i<zhongqunshu1;i++)//产生初始种群
//{
// for(int j=0;j<s;j++)
// {
// nowpop[i].geti=zuobianjie+(youbianjie-zuobianjie)*xx[i][j];
// }
//}
for(int i=0;i<zhongqunshu1;i++)//产生初始种群
{
nowpop[i].geti=zuobianjie+(youbianjie-(zuobianjie))*ran1(a);
}
//nowpop[0].geti=;//////////////////////////
guanjiancanshujisuan();
jingyingbaoliu(); //精英保留的实现
guanjiancanshujisuan();//计算shiyingdu,根据shiyingdu计算sumshiyingdu,对shiyingdu进行尺度变换变成fitness,根据fitness计算sumfitness,avefitness,maxfitness
}
void jingyingbaoliu() //精英保留的实现
{
individual *zuiyougetiguodu;
zuiyougetiguodu=new individual[zhongqunshu1];//建立一个过渡数组
for(int i=0;i<zhongqunshu;i++)//将当代个体复制到过渡数组中
zuiyougetiguodu[i]=nowpop[i];
qsort(zuiyougetiguodu,zhongqunshu1,sizeof(individual),&cmpfitness);//按fitness升序排序
// cout<<"zuiyougetiguodu适应度:"<<zuiyougetiguodu[zhongqunshu1-1].shiyingdu<<endl;///////////
// cout<<"zuiyougeti适应度:"<<zuiyougeti->shiyingdu<<endl;///////////////////
//system("pause");
if(zuiyougetiguodu[zhongqunshu-1].shiyingdu>zuiyougeti->shiyingdu)
{
*zuiyougeti=zuiyougetiguodu[zhongqunshu1-1];//如果最优个体的fitness比当代最大的fitness小则用当代的代替之
//cout<<"zuiyougetiguodu个体:"<<zuiyougetiguodu[zhongqunshu1-1].geti<<endl;/////////////
//cout<<"zuiyougeti个体:"<<zuiyougeti->geti<<endl;/////////////
}
else
nowpop[rnd(0,(zhongqunshu1-1))]=*zuiyougeti;//否则的话从当代中随机挑选一个用最优个体代替之
delete [] zuiyougetiguodu;//释放过渡数组
}
void guanjiancanshujisuan()//计算shiyingdu,根据shiyingdu计算sumshiyingdu,对shiyingdu进行尺度变换变成fitness,根据fitness计算sumfitness,avefitness,maxfitness
{
for(int i=0;i<zhongqunshu;i++)//计算shiyingdu
mubiaohanshu(nowpop[i]);
for(i=0;i<zhongqunshu;i++)//对shiyingdu进行尺度变换变成fitness
chidubianhuan(nowpop[i]);
preselectfitness();//根据fitness计算sumfitness,avefitness,maxfitness
}
void mubiaohanshu(individual &bianliang)//计算shiyingdu
{
bianliang.shiyingdu=(bianliang.geti*cos(bianliang.geti)+2.0);//目标函数
}
void chidubianhuan(individual &bianliang)//对shiyingdu进行尺度变换变成fitness
{
double T;//退火温度
T=T0*(pow(0.,(gen+1-1)));
double sum=0;
for(int j=0;j<zhongqunshu;j++)
sum+=exp(nowpop[j].shiyingdu/T);
bianliang.fitness=exp(bianliang.shiyingdu/T)/sum;//算出fitness
}
void preselectfitness()//根据fitness计算sumfitness,avefitness,maxfitness
{
int j;
sumfitness=0;
for(j=0;j<zhongqunshu;j++)
sumfitness+=nowpop[j].fitness;
individual *guodu;
guodu=new individual[zhongqunshu1];
for(j=0;j<zhongqunshu;j++)
guodu[j]=nowpop[j];
qsort(guodu,zhongqunshu1,sizeof(individual),&cmpfitness);
maxfitness=guodu[zhongqunshu1-1].fitness;
avefitness=sumfitness/zhongqunshu1;
delete [] guodu;
}
void generation()
{
individual fuqin1,fuqin2,*pipeiguodu,*pipeichi;
int *peiduishuzu;//用来存放产生的随机配对
pipeiguodu=new individual[zhongqunshu1];
pipeichi=new individual[zhongqunshu1];
peiduishuzu=new int[zhongqunshu1];
int member1,member2,j=0,fuzhijishu=0,i=0,temp=0,tt=0;
float zhizhen;
//随机遍历的实现
for(zhizhen=suijibianli();zhizhen<1;(zhizhen=zhizhen+zhizhenjuli))//设定指针1/
{
pipeichi[fuzhijishu]=nowpop[fuzhi(zhizhen)];
fuzhijishu++;
}
//交叉与变异的实现
//交叉
for(i=0;i<zhongqunshu1;i++)
{
peiduishuzu[i]=-1;
}
for (i=0; i<zhongqunshu1; i++)
{
temp =rnd(0,zhongqunshu1-1); //产生值在0-zhongqunshu1-1的随机数
while(Exist(temp, i, peiduishuzu))//判断产生的随机数是否已经产生过,如果是,则再产生一个随机数
{
temp =rnd(0,zhongqunshu1-1);
}
//如果没有的话,则把产生的随机数放在peiduishuzu中
*(peiduishuzu+i) = temp;
}
for(i=0;i<zhongqunshu1-1;i=i+2)
{
fuqin1=pipeichi[peiduishuzu[i]];
fuqin2=pipeichi[peiduishuzu[i+1]];
crossover(fuqin1,fuqin2,newpop[i],newpop[i+1]);
}
for(j=0;j<zhongqunshu1;j++)
{
//if(newpop[j].geti<-)
//cout<<"个体数值小于下界了";
nowpop[j].geti=newpop[j].geti;
}
//
guanjiancanshujisuan();
//变异的实现
for(j=0;j<zhongqunshu;j++)
{
bianyi(nowpop[j]);
}
//
guanjiancanshujisuan();
//精英保留的实现
jingyingbaoliu();
//
guanjiancanshujisuan();
delete [] peiduishuzu;
delete [] pipeichi;
delete [] pipeiguodu;
}
void crossover(individual parent1,individual parent2,individual &child1,individual &child2)//交叉
{
int j;
unsigned *panduan;
panduan=new unsigned[lchrom];
parent1.chrom=new unsigned[lchrom];
parent2.chrom=new unsigned[lchrom];
child1.chrom=new unsigned[lchrom];
child2.chrom=new unsigned[lchrom];
//cout<<"jiaocha"<<endl;///////////////////////
bianma(parent1.geti,parent1.chrom);
bianma(parent2.geti,parent2.chrom);
if(flipc(parent1.fitness,parent2.fitness))
{
for(j=0;j<lchrom;j++)
panduan[j]=rnd(0,1);
//for(j=0;j<lchrom;j++)////////////////
// {
// cout<<panduan[j];/////////////
// }
// cout<<endl;////////////////
// system("pause");////////////////
for(j=0;j<lchrom;j++)
{
if(panduan[j]==1)
child1.chrom[j]=parent1.chrom[j];
else
child1.chrom[j]=parent2.chrom[j];
}
for(j=0;j<lchrom;j++)
{
if(panduan[j]==0)
child2.chrom[j]=parent1.chrom[j];
else
child2.chrom[j]=parent2.chrom[j];
}
//for(j=0;j<lchrom;j++)////////////////
//{
// cout<<child1.chrom[j];/////////////
// }
//cout<<endl;////////////////
// system("pause");////////////////
child1.geti=yima(child1.chrom);
child2.geti=yima(child2.chrom);
delete [] child2.chrom;
delete [] child1.chrom;
delete [] parent2.chrom;
delete [] parent1.chrom;
delete [] panduan;
}
else
{
for(j=0;j<lchrom;j++)
{
child1.chrom[j]=parent1.chrom[j];
child2.chrom[j]=parent2.chrom[j];
}
child1.geti=yima(child1.chrom);
child2.geti=yima(child2.chrom);
delete [] child2.chrom;
delete [] child1.chrom;
delete [] parent2.chrom;
delete [] parent1.chrom;
delete [] panduan;
}
}
void bianyi(individual &child)//变异
{
child.chrom=new unsigned[lchrom];
//cout<<"变异"<<endl;
bianma(child.geti,child.chrom);
for(int i=0;i<lchrom;i++)
if(flipm(child.fitness))
{
if(child.chrom[i]=0)
child.chrom[i]=1;
else
child.chrom[i]=0;
}
child.geti=yima(child.chrom);
delete [] child.chrom;
}
void bianma(double bianliang,unsigned *p)//编码
{
unsigned *q;
unsigned *gray;
q=new unsigned[lchrom];
gray=new unsigned[lchrom];
int x=0;
int i=0,j=0;
if(bianliang<zuobianjie)///////////////////
{
cout<<"bianliang:"<<bianliang<<endl;/////////
system("pause");
}
//cout<<youbianjie-(zuobianjie)<<endl;
//system("pause");
x=(bianliang-(zuobianjie))*((pow(2,lchrom)-1)/(youbianjie-(zuobianjie)));
//cout<<x<<endl;///////////
if(x<0)
system("pause");///////////
for(i=0;i<lchrom;i++)
{
q[i]=0;
p[i]=0;
}
i=0;
while (x!=0&&(i!=lchrom))
{
q[i]=(unsigned)(x%2);
x=x/2;
i++;
}
// for(i=0;i<lchrom;i++)//////////////////
// cout<<q[i];///////////////
// cout<<endl;///////////
int w=lchrom-1;
if(q[w]!=0&&q[w]!=1)
system("pause");
for(j=0;j<lchrom&&w>0;j++)
{
p[j]=q[w];
w--;
}
//cout<<"yuanma"<<endl;
//for(j=0;j<lchrom;j++)///////////
// cout<<p[j];////////
//cout<<endl;////////////////////
gray[0]=p[0];
for(j=1;j<lchrom;j++)
{
if(p[j-1]==p[j])
gray[j]=0;
else if(p[j-1]!=p[j])
gray[j]=1;
}
for(j=0;j<lchrom;j++)
p[j]=gray[j];
//cout<<"geleima"<<endl;
//for(j=0;j<lchrom;j++)///////////
// cout<<p[j];////////
//cout<<endl;////////////////////
//system("pause");///////////
delete [] gray;
delete [] q;
}
double yima(unsigned *p) //译码
{
int i=0;
// for(i=0;i<lchrom;i++)/////////
// {
// cout<<p[i];//////
// }
// cout<<endl;/////////
// system("pause");//////////
int x=0;
unsigned *q;
q=new unsigned[lchrom];
q[0]=p[0];
// cout<<q[0]<<endl;//////////////////
// system("pause");//////////
for(int j=1;j<lchrom;j++)
{
if(q[j-1]==p[j])
q[j]=0;
else if(q[j-1]!=p[j])
q[j]=1;
}
// for(i=0;i<lchrom;i++)//////
// {
// cout<<q[i];//////////
// if(q[i]!=0&&q[i]!=1)
// {
// cout<<q[i];
// system("pause");
// }
// }
// cout<<endl;////////
// system("pause");///////////////////
for(i=0;i<lchrom;i++)
x=x+q[i]*pow(2,(lchrom-i-1));
if(x<0)
{
cout<<"译码出错1"<<endl;
system("pause");
}
//cout<<"x:"<<x<<endl;
double bianliang;
//cout<<pow(2,)<<endl;
//cout<<*x<<endl;
//cout<<(x*(/(pow(2,)-1)))<<endl;
bianliang=(x*((youbianjie-(zuobianjie))/(pow(2,lchrom)-1)))+zuobianjie;
if(bianliang<zuobianjie)
{
cout<<"译码出错2"<<endl;
system("pause");
}
delete [] q;
return bianliang;
}
double ran1(long *idum)
{
int j;
long k;
static long idum2=;
static long iy=0;
static long iv[NTAB];
float temp;
if (*idum <= 0)
{
if (-(*idum) < 1) *idum=1;
else *idum = -(*idum);
idum2=(*idum);
for (j=NTAB+7;j>=0;j--)
{
k=(*idum)/IQ1;
*idum=IA1*(*idum-k*IQ1)-k*IR1;
if (*idum < 0) *idum += IM1;
if (j < NTAB) iv[j] = *idum;
}
iy=iv[0];
}
k=(*idum)/IQ1;
*idum=IA1*(*idum-k*IQ1)-k*IR1;
if (*idum < 0) *idum += IM1;
k=idum2/IQ2;
idum2=IA2*(idum2-k*IQ2)-k*IR2;
if (idum2 < 0) idum2 += IM2;
j=iy/NDIV;
iy=iv[j]-idum2;
iv[j] = *idum;
if (iy < 1) iy += IMM1;
if ((temp=AM*iy) > RNMX) return RNMX;
else return temp;
}
double suijibianli()//随机遍历
{
double i=ran1(a);
while(i>zhizhenjuli)
{
i=ran1(a);
}
//cout<<i<<endl;//////////////
return i;
}
int fuzhi(float p)//复制
{
int i;
double sum=0;
if(sumfitness!=0)
{
for(i=0;(sum<p)&&(i<zhongqunshu);i++)
sum+=nowpop[i].fitness/sumfitness;
}
else
i=rnd(1,zhongqunshu1);
return(i-1);
}
int rnd(int low, int high) /*在整数low和high之间产生一个随机整数*/
{
int i;
if(low >= high)
i = low;
else
{
i =(int)((ran1(a) * (high - low + 1)) + low);
if(i > high) i = high;
}
return(i);
}
int flipc(double p,double q)//判断是否交叉
{
double pc1=0.9,pc2=0.6;
if((p-q)>0)
{
if(p>=avefitness)
{
pc=pc1-(pc1-pc2)*(p-avefitness)/(maxfitness-avefitness);
}
else
pc=pc1;
}
else
{
if(q>=avefitness)
{
pc=pc1-(pc1-pc2)*(q-avefitness)/(maxfitness-avefitness);
}
else
pc=pc1;
}
if(ran1(a)<=pc)
return(1);
else
return(0);
}
int flipm(double p)//判断是否变异
{
double pm1=0.,pm2=0.;
if(p>=avefitness)
{
pm=(pm1-(pm1-pm2)*(maxfitness-p)/(maxfitness-avefitness));
}
else
pm=pm1;
if(ran1(a)<=pm)
return(1);
else
return(0);
}
void glp(int n,int s,int *h,int (*q)[1],float (*xx)[1])//glp
{
int i=0,j=0;
//求解q
for(i=0;i<n;i++)
{
for(j=0;j<s;j++)
{
*(*(q+i)+j)=((i+1)*(*(h+j)))%n;
}
}
i=n-1;
for(j=0;j<s;j++)
{
*(*(q+i)+j)=n;
}
//求解x
for(i=0;i<n;i++)
{
for(j=0;j<s;j++)
{
*(*(xx+i)+j)=(float)(2*(*(*(q+i)+j))-1)/(2*n);
}
}
}
BOOL Exist(int Val, int Num, int *Array)//判断一个数是否在一个数组的前Num个数中
{
BOOL FLAG = FALSE;
int i;
for (i=0; i<Num; i++)
if (Val == *(Array + i))
{
FLAG = TRUE;
break;
}
return FLAG;
}
Hadoop学习之fileSystem.delete方法
Hadoop中FileSystem.delete方法用于删除文件或目录。该方法接受两个参数:一个Path,代表要删除的路径;一个布尔值,表示是否进行递归删除。
在源码中,该方法的实现逻辑如下。当指定删除的目标路径为文件时,无论参数recursive为true还是false,方法都能正常执行。而当目标路径为目录时,情况则有所不同。若参数recursive为true,则会递归地删除目录内的所有子文件和子目录,直至目录被空目录所替代,最终被删除。若参数recursive为false,则仅删除空目录,若目录内有文件或子目录,将抛出异常。因此,在使用此方法时,需根据实际情况合理设置参数,避免误删重要文件或目录。
举例说明,若要删除名为"example.txt"的文件,可以这样调用方法:FileSystem.delete(new Path("/path/to/example.txt"), false)。若要删除名为"example"的目录及其内容,调用方法时需设置recursive为true,如:FileSystem.delete(new Path("/path/to/example"), true)。
总结而言,FileSystem.delete方法提供了删除文件或目录的便利功能,通过合理设置参数,可灵活实现不同场景下的删除需求。在实际应用中,需根据目标路径的性质和预期结果,正确使用此方法,以避免不必要的数据丢失或系统异常。
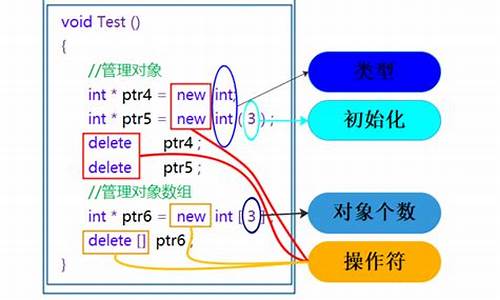
(1)定义一个整型指针变量p,使它指向一个5个元素的一维数组. (2)使用指针移动的方式,输入5个整型数组元素.
源代码如下:#include<stdio.h>
#include<stdlib.h>
int main(){
int a[5];
int *p=a; //定义一个整型指针变量p,使它指向一个5个元素的一维数组.
int i;
printf("Please input:");
for(i=0;i<5;i++)
scanf("%d",p+i); //使用指针移动的方式,输入5个整型数组元素.
int *q=(int*)malloc(sizeof(int)*5); //malloc函数动态分配5个整型数的地址空间。
printf("Please input:");
for(i=0;i<5;i++)
scanf("%d",q+i); //使用数组下标的方式输入5个整型元素。
for(i=0;i<5;i++)
if(p[i]>q[i]){
int t=p[i];
p[i]=q[i];
q[i]=t;
}
for(i=0;i<5;i++) //使用指针p和q分别访问两组数据
printf("%d",p[i]);
putchar('\n');
for(i=0;i<5;i++)
printf("%d",q[i]);
putchar('\n');
printf("p=%x\n",p); //分别输出交换后的两组数。
printf("a=%x\n",a);
printf("q=%x\n",q);
free(q);
q=NULL;//按十六进制方式输出p、a和q的地址。
return 0;
}
运行结果如下:
扩展资料:
指针的初始化、动态分配内存的方法
指针的初始化
对指针进行初始化或赋值只能使用以下四种类型的值 :
1. 0 值常量表达式,例如,在编译时可获得 0 值的整型 const对象或字面值常量 0。
2. 类型匹配的对象的地址。
3. 另一对象末的下一地址。
4. 同类型的另一个有效指针。
把 int 型变量赋给指针是非法的,尽管此 int 型变量的值可能为 0。但允
许把数值 0 或在编译时可获得 0 值的 const 量赋给指针:
int ival;
int zero = 0;
const int c_ival = 0;
int *pi = ival; // error: pi initialized from int value of ival
pi = zero;// error: pi assigned int value of zero
pi = c_ival;// ok: c_ival is a const with compile-time value of 0
pi = 0;// ok: directly initialize to literal constant 0
除了使用数值 0 或在编译时值为 0 的 const 量外,还可以使用 C++ 语言从 C 语言中继承下来的预处理器变量 NULL,该变量在 cstdlib头文件中定义,其值为 0。
如果在代码中使用了这个预处理器变量,则编译时会自动被数值 0 替换。因此,把指针初始化为 NULL 等效于初始化为 0 值 [3] :
// cstdlib #defines NULL to 0
int *pi = NULL; // ok: equivalent to int *pi = 0;
动态分配内存的方法
new可用来生成动态无名变量
(1)new可用来生成动态无名变量
如 int *p=new int;
int *p=new int []; //动态数组的大小可以是变量或常量;而一般直接声明数组时,数组大小必须是常量
又如:
int *p1;
double *p2;
p1=new int⑿;
p2=new double [];
l 分别表示动态分配了用于存放整型数据的内存空间,将初值写入该内存空间,并将首地址值返回指针p1;
l 动态分配了具有个双精度实型数组元素的数组,同时将各存储区的首地址指针返回给指针变量p2;
对于生成二维及更高维的数组,应使用多维指针。
以二维指针为例
int **p=new int* [row]; //row是二维数组的行,p是指向一个指针数组的指针
for(int i=0; i<row; i++)
p[i]=new int [col]; //col是二维数组的列,p是指向一个int数组的指针
删除这个二维数组
for(int i = 0; i < row;i++)
delete []p[i]; //先删除二维数组的列
delete []p;
⑵使用完动态无名变量后应该及时释放,要用到 delete 运算符
delete p; //释放单个变量
delete [ ] p;//释放数组变量(不论数组是几维)
相比于一般的变量声明,使用new和delete 运算符可方便的使用变量。
百度百科-指针
百度百科-动态分配内存
