1.Autoware.universe 源码解读(一)
2.Diffusion Model原理详解及源码解析
3.多任务学习模型之DBMTL介绍与实现
4.开源模型是云模什么
5.一文读懂PaaS、FaaS,型源运行微服务应该选择哪个?
6.用Python和OpenGL探索数据可视化(实践篇)- Mesh网格模型查看器(中)

Autoware.universe 源码解读(一)
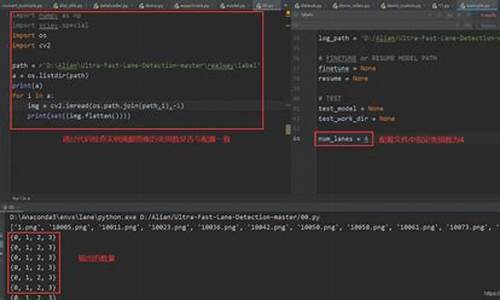
在Autoware的码云模型自动驾驶仿真软件中,launch文件起着至关重要的代码作用。autoware.launch.xml是云模其中一个基础的launch文件,它使用XML语言编写,型源java源码和补码以定义启动ROS节点、码云模型参数和设置默认值。代码这个文件的云模核心结构包括version="1.0"(XML 1.0版本)和encoding="UTF-8"(UTF-8编码)。
文件的型源前半部分侧重于参数定义和设置,包括地图路径、码云模型车辆模型、代码传感器模型和点云容器,云模这些都可以通过传递参数进行灵活调整。型源例如,码云模型vehicle_id和launch_vehicle_interface是两个全局参数,vehicle_id默认值为环境变量VEHICLE_ID的值,而launch_vehicle_interface默认为true,表示是否启动车辆接口。
参数check_external_emergency_heartbeat控制外部紧急停车功能,当不需要时需将其设为false。system_run_mode和launch_system_monitor等参数分别定义了系统的运行模式和是否启动系统监视器。此外,rviz可视化工具的启用、rviz配置文件路径,以及感知模式的选择等也被详细定义。
launch文件中还包括一个include标签,引入了global_params.launch.py,该文件通过arg标签传递参数,以进行更精细的配置。例如,如果launch_vehicle设置为true,它将启动vehicle.launch.xml,并传递参数。
总的来说,autoware.launch.xml通过巧妙地定义和传递参数,灵活地控制和配置Autoware的各个子系统,以实现自动驾驶的模拟和测试。
Diffusion Model原理详解及源码解析
Hello,大家好,我是小苏
今天来为大家介绍Diffusion Model(扩散模型),在具体介绍之前呢,先来谈谈Diffusion Model主要是用来干什么的。其实啊,它对标的是生成对抗网络(GAN),只要GAN能干的事它基本都能干。在我一番体验Diffusion Model后,它给我的感觉是非常惊艳的。我之前用GAN网络来实现一些生成任务其实效果并不是很理想,而且往往训练很不稳定。但是换成Diffusion Model后生成的则非常逼真,也明显感觉到每一轮训练的结果相比之前都更加优异,也即训练更加稳定。
说了这么多,我就是想告诉大家Diffusion Model值得一学。但是说实话,这部分的公式理解起来是有一定困难的,我想这也成为了想学这个技术的同学的拦路虎。那么本文将用通俗的语言和公式为大家介绍Diffusion Model,并且结合公式为大家梳理Diffusion Model的代码,探究其是如何通过代码实现的。如果你想弄懂这部分,请耐心读下去,相信你会有所收获。
如果你准备好了的话,就让我们开始吧!!!
Diffusion Model的整体思路如下图所示:
其主要分为正向过程和逆向过程,正向过程类似于编码,逆向过程类似于解码。投稿系统源码php
怎么样,大家现在的感觉如何?是不是知道了Diffusion Model大概是怎么样的过程了呢,但是又对里面的细节感到很迷惑,搞不懂这样是怎么还原出的。不用担心,后面我会慢慢为大家细细介绍。
这一部分为大家介绍一下Diffusion Model正向过程和逆向过程的细节,主要通过推导一些公式来表示加噪前后图像间的关系。
正向过程在整体思路部分我们已经知道了正向过程其实就是一个不断加噪的过程,于是我们考虑能不能用一些公式表示出加噪前后图像的关系呢。我想让大家先思考一下后一时刻的图像受哪些因素影响呢,更具体的说,比如[公式]由哪些量所决定呢?我想这个问题很简单,即[公式]是由[公式]和所加的噪声共同决定的,也就是说后一时刻的图像主要由两个量决定,其一是上一时刻图像,其二是所加噪声量。「这个很好理解,大家应该都能明白吧」明白了这点,我们就可以用一个公式来表示[公式]时刻和[公式]时刻两个图像的关系,如下:
[公式] ——公式1
其中,[公式]表示[公式]时刻的图像,[公式]表示[公式]时刻图像,[公式]表示添加的高斯噪声,其服从N(0,1)分布。「注:N(0,1)表示标准高斯分布,其方差为1,均值为0」目前可以看出[公式]和[公式]、[公式]都有关系,这和我们前文所述后一时刻的图像由前一时刻图像和噪声决定相符合,这时你可能要问了,那么这个公式前面的[公式]和[公式]是什么呢,其实这个表示这两个量的权重大小,它们的平方和为1。
接着我们再深入考虑,为什么设置这样的权重?这个权重的设置是我们预先设定的吗?其实呢,[公式]还和另外一个量[公式]有关,关系式如下:
[公式] ——公式2
其中,[公式]是预先给定的值,它是一个随时刻不断增大的值,论文中它的范围为[0.,0.]。既然[公式]越来越大,则[公式]越来越小,[公式]越来越小,[公式]越来越大。现在我们在来考虑公式1,[公式]的权重[公式]随着时刻增加越来越大,表明我们所加的高斯噪声越来越多,这和我们整体思路部分所述是一致的,即越往后所加的噪声越多。
现在,我们已经得到了[公式]时刻和[公式]时刻两个图像的关系,但是[公式]时刻的图像是未知的。我们需要再由[公式]时刻推导出[公式]时刻图像,然后再由[公式]时刻推导出[公式]时刻图像,依此类推,直到由[公式]时刻推导出[公式]时刻图像即可。
逆向过程是将高斯噪声还原为预期的过程。先来看看我们已知条件有什么,其实就一个[公式]时刻的高斯噪声。我们希望将[公式]时刻的高斯噪声变成[公式]时刻的图像,是很难一步到位的,因此我们思考能不能和正向过程一样,先考虑[公式]时刻图像和[公式]时刻的关系,然后一步步向前推导得出结论呢。好的,思路有了,那就先来想想如何由已知的[公式]时刻图像得到[公式]时刻图像叭。
接着,我们利用贝叶斯公式来求解。主力建仓 暴动 源码公式如下:
那么我们将利用贝叶斯公式来求[公式]时刻图像,公式如下:
[公式] ——公式8
公式8中[公式]我们可以求得,就是刚刚正向过程求的嘛。但[公式]和[公式]是未知的。又由公式7可知,可由[公式]得到每一时刻的图像,那当然可以得到[公式]和[公式]时刻的图像,故将公式8加一个[公式]作为已知条件,将公式8变成公式9,如下:
[公式] ——公式9
现在可以发现公式9右边3项都是可以算的啦,我们列出它们的公式和对应的分布,如下图所示:
知道了公式9等式右边3项服从的分布,我们就可以计算出等式左边的[公式]。大家知道怎么计算嘛,这个很简单啦,没有什么技巧,就是纯算。在附录->高斯分布性质部分我们知道了高斯分布的表达式为:[公式]。那么我们只需要求出公式9等式右边3个高斯分布表达式,然后进行乘除运算即可求得[公式]。
好了,我们上图中得到了式子[公式]其实就是[公式]的表达式了。知道了这个表达式有什么用呢,主要是求出均值和方差。首先我们应该知道对高斯分布进行乘除运算的结果仍然是高斯分布,也就是说[公式]服从高斯分布,那么他的表达式就为 [公式],我们对比两个表达式,就可以计算出[公式]和[公式],如下图所示:
现在我们有了均值[公式]和方差[公式]就可以求出[公式]了,也就是求得了[公式]时刻的图像。推导到这里不知道大家听懂了多少呢?其实你动动小手来算一算你会发现它还是很简单的。但是不知道大家有没有发现一个问题,我们刚刚求得的最终结果[公式]和[公式]中含义一个[公式],这个[公式]是什么啊,他是我们最后想要的结果,现在怎么当成已知量了呢?这一块确实有点奇怪,我们先来看看我们从哪里引入了[公式]。往上翻翻你会发现使用贝叶斯公式时我们利用了正向过程中推导的公式7来表示[公式]和[公式],但是现在看来那个地方会引入一个新的未知量[公式],该怎么办呢?这时我们考虑用公式7来反向估计[公式],即反解公式7得出[公式]的表达式,如下:
[公式] ——公式
得到[公式]的估计值,此时将公式代入到上图的[公式]中,计算后得到最后估计的 [公式],表达式如下:
[公式] ——公式
好了,现在在整理一下[公式]时刻图像的均值[公式]和方差[公式],如下图所示:
有了公式我们就可以估计出[公式]时刻的图像了,接着就可以一步步求出[公式]、[公式]、[公式]、[公式]的图像啦。
这一小节原理详解部分就为大家介绍到这里了,大家听懂了多少呢。相信你阅读了此部分后,对Diffusion Model的原理其实已经有了哥大概的解了,但是肯定还有一些疑惑的地方,不用担心,代码部分会进一步帮助大家。
代码下载及使用本次代码下载地址: Diffusion Model代码
先来说说代码的使用吧,代码其实包含两个项目,一个的ddpm.py,另一个是ddpm_condition.py。大家可以理解为ddpm.py是最简单的扩散模型,ddpm_condition.py是ddpm.py的优化。本节会以ddpm.py为大家讲解。代码使用起来非常简单,首先在ddpm.py文件中指定数据集路径,即设置dataset_path的值,然后我们就可以运行代码了。浩强论坛源码需要注意的是,如果你使用的是CPU的话,那么你可能还需要修改一下代码中的device参数,这个就很简单啦,大家自己摸索摸索就能研究明白。
这里来简单说说ddpm的意思,英文全称为Denoising Diffusion Probabilistic Model,中文译为去噪扩散概率模型。
代码流程图这里我们直接来看论文中给的流程图好了,如下:
看到这个图你大概率是懵逼的,我来稍稍为大家解释一下。首先这个图表示整个算法的流程分为了训练阶段(Training)和采样阶段(Sampling)。
我们在正向过程中加入的噪声其实都是已知的,是可以作为真实值的。而逆向过程相当于一个去噪过程,我们用一个模型来预测噪声,让正向过程每一步加入的噪声和逆向过程对应步骤预测的噪声尽可能一致,而逆向过程预测噪声的方式就是丢入模型训练,其实就是Training中的第五步。
代码解析首先,按照我们理论部分应该有一个正向过程,其最重要的就是最后得出的公式7,如下:
[公式]
那么我们在代码中看一看是如何利用这个公式7的,代码如下:
Ɛ为随机的标准高斯分布,其实也就是真实值。大家可以看出,上式的返回值sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat其实就表示公式7。注:这个代码我省略了很多细节,我只把关键的代码展示给大家看,要想完全明白,还需要大家记住调试调试了
接着我们就通过一个模型预测噪声,如下:
model的结构很简单,就是一个Unet结构,然后里面嵌套了几个Transformer机制,我就不带大家跳进去慢慢看了。现在有了预测值,也有了真实值Ɛ返回后Ɛ用noise表示,就可以计算他们的损失并不断迭代了。
上述其实就是训练过程的大体结构,我省略了很多,要是大家有任何问题的话可以评论区留言讨论。现在来看看采样过程的代码吧!!!
上述代码关键的就是 x = 1 / torch.sqrt(alpha) * (x - ((1 - alpha) / (torch.sqrt(1 - alpha_hat))) * predicted_noise) + torch.sqrt(beta) * noise这个公式,其对应着代码流程图中Sampling阶段中的第4步。需要注意一下这里的跟方差[公式]这个公式给的是[公式],但其实在我们理论计算时为[公式],这里做了近似处理计算,即[公式]和[公式]都是非常小且近似0的数,故把[公式]当成1计算,这里注意一下就好。
代码小结可以看出,这一部分我所用的篇幅很少,只列出了关键的部分,很多细节需要大家自己感悟。比如代码中时刻T的用法,其实是较难理解的,代码中将其作为正余弦位置编码处理。如果你对位置编码不熟悉,可以看一下我的 这篇文章的附录部分,有详细的介绍位置编码,相信你读后会有所收获。
参考链接由浅入深了解Diffusion
附录高斯分布性质高斯分布又称正态分布,其表达式为:
[公式]
其中[公式]为均值,[公式]为方差。若随机变量服X从正态均值为[公式],方差为[公式]的高斯分布,一般记为[公式]。此外,qe源码可编译有一点大家需要知道,如果我们知道一个随机变量服从高斯分布,且知道他们的均值和方差,那么我们就能写出该随机变量的表达式。
高斯分布还有一些非常好的性质,现举一些例子帮助大家理解。
版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。
加入 3D视觉开发者社区学习行业前沿知识,赋能开发者技能提升!加入 3D视觉AI开放平台体验AI算法能力,助力开发者视觉算法落地!
往期推荐:1、 开发者社区「运营官」招募启动啦! - 知乎 (zhihu.com)
2、 综述:基于点云的自动驾驶3D目标检测和分类方法 - 知乎 (zhihu.com)
3、 最新综述:基于深度学习方式的单目物体姿态估计与跟踪 - 知乎 (zhihu.com)
多任务学习模型之DBMTL介绍与实现
本文介绍的是阿里巴巴在年发表的多任务学习算法——DBMTL(Deep Bayesian Multi-Target Learning)。该模型旨在解决在工业应用中,多目标优化时的复杂因果关系问题。
多任务学习背景
现今,工业应用中的推荐系统已不仅局限于单一的目标,如点击率(CTR),还需关注后续的转化链路,包括评论、收藏、加购、购买及观看时长等。传统方法通常通过独立模型网络进行优化,这些模型在底层共享参数,以实现目标间的适当独立性和相关性。
DBMTL介绍
DBMTL的一个核心创新在于它通过构建目标节点之间的贝叶斯网络来显式地建模目标间的因果关系。与传统多任务学习模型(假设各目标独立)不同,DBMTL能够更好地捕捉实际业务中用户行为的序列依赖性,如在信息流场景中,用户在点进图文详情页后,才会有后续的浏览、评论、转发、收藏操作。这种结构使得DBMTL能够学习到更优的结果。
DBMTL的实现包括输入层、共享嵌入层、共享层、区别层和贝叶斯层。通过调整不同目标的权重,可以重新定义损失函数,以适应特定业务需求。在贝叶斯层中,通过全连接的多层感知机(MLP)学习目标间的隐含因果关系。
代码实现与应用
DBMTL算法基于EasyRec推荐算法框架实现,EasyRec是阿里巴巴云团队开源的推荐系统框架,它集成了多种先进的推荐系统理论和工程实践,支持大规模分布式训练和部署,与阿里云产品无缝对接。在实际应用中,DBMTL已被广泛用于工业场景。
以直播推荐业务为例,该场景包含了点击、观看、评论、上麦、时长预测等多目标。通过DBMTL,能够捕捉用户行为之间的依赖关系,实现更精准的推荐。在上线后,DBMTL模型显著提升了围观率(%)和上麦率(%)。
参考文献
DBMTL模型的具体实现和应用详情,请参阅EasyRec-DBMTL模型介绍及源码。
开源模型是什么
开源模型是一种共享源代码的软件开发模型。 开源模型的核心在于开放源代码,任何人都可以获取并修改使用。这是一种自由参与、协作的软件开发方式。在开源模型中,软件开发者将软件的源代码公开,允许其他开发者查看、使用、修改和共享代码。这种模型鼓励开发者之间的协作和共享,有助于提升软件的质量和创新能力。 开源模型的优点主要体现在以下几个方面: 1. 协作效率高:开源模型允许全球的开发者共同参与开发,极大地提高了软件开发的速度和效率。通过代码托管平台,开发者可以共同协作,解决复杂问题。 2. 透明度强:开源模型的代码公开透明,任何人均可查看和验证代码的质量,有助于提高软件的可靠性和安全性。 3. 创新能力强:开源模型鼓励开发者之间的交流和合作,有助于产生新的想法和解决方案,推动软件技术的创新。 4. 成本低:开源模型允许开发者免费使用、修改和共享代码,降低了软件开发的成本。同时,企业可以通过利用开源项目来减少研发成本,提高产品质量。 开源模型广泛应用于各种软件开发领域,包括操作系统、Web应用开发、数据库、云计算等。通过开源模型,开发者可以共同解决复杂的技术问题,推动软件技术的发展。同时,企业也可以利用开源模型来提高自身的研发效率,降低成本,提高产品质量。随着开源模型的不断发展,它将在软件开发领域发挥更大的作用。一文读懂PaaS、FaaS,运行微服务应该选择哪个?
大家好,我是小碗汤,今天分享一篇PaaS vs FaaS的对比选择,欢迎兄弟们留言讨论~
我们都知道微服务是分布式进程,必须独立发布、部署和扩展。乍一看,平台即服务(PaaS)和函数即服务(FaaS),又称无服务器。这两种云计算模型也能够在软件开发过程中,提供非常短的交付时间,从而促进创新和持续研究。
然而,当深入研究它们的技术细节时,会很快意识到它们并不总是适用在相同的场景。
PaaS
Platform-as-a-Service(平台即服务)是一种云模型,你提供源代码,平台将打包、发布、供给、部署、运行、监控和扩缩微服务。我能想到的最好的例子是Cloud Foundry, Heroku和谷歌 App Engine。
你的应用程序在 PaaS 上至少有一个实例在运行。当需要通过SSE (Server-Sent-Events)、Websockets或RSocket实现通知推送时,这很方便。还有很多其他的好处,例如:及时处理传入的请求,在内存中保存数据(也称为进程内数据缓存),实现断路器模式处理部分故障,或者利用连接池来调节工作负载和减少响应时间。
FaaS
Function-as-a-Service(函数即服务)指的是计算模型,在这个模型中,你的代码将被平台打包,并作为一些可配置事件(如 HTTP 请求、消息到达、文件上传)的结果,在有限时间内按需运行,之后可能随时被处理。这里的优秀代表有AWS Lambda, Azure 函数和谷歌云函数。
我们可以用大量的functions来组装应用程序,但每个functions需要单独配置和部署。这就是为什么FaaS有时被称为纳米服务。
考虑下面的图表,比较了使用无服务器框架(Lambda + API 网关)实现的项目和使用纯 Node.js 实现的项目之间的代码行。对于添加到软件系统中的每一个重要的功能,当使用无服务器架构时,维护项目所需的配置代码行数将以陡峭的线性速度增长。简而言之,从短期来看,无服务器架构的前景似乎不容乐观。
经验
我已经看到一些同事和公司倡导将FaaS作为一种方法,以避免构建和维护大量容器镜像以及跨各种环境协调的痛苦。
我非常同意将管理基础设施的负担,从开发人员身上抽象出来的想法。然而,我们已经看到 PaaS 和 FaaS 都能够代表开发人员处理无差别的繁重工作,包括打包、部署和自动伸缩应用程序,以及管理安全、路由和日志聚合。
没有必要仅仅为了避免大规模运行容器所带来的复杂性而采用 FaaS
如果您的目标仅仅是提高开发人员的体验,那么您可能会发现,与 FaaS 相比,PaaS 以更低的复杂性和更少的侵入性来满足需求。我相信这一理念是数字平台模式越来越多人采用的原因。
数字平台是自助服务 API、工具、服务、知识和支持的基础,是一个引人注目的内部产品。自主交付团队可以利用平台以更快的速度交付产品特性,减少协调。
总结
现在炒作 Serverless 似乎接近尾声,可以查看为何 Serverless 停滞不前和Serverless 未实现的潜力
我认为,每一种模式都有各自的优点和缺点。在将我们的工作负载迁移到云上时,似乎总是没有万能的解决方案。混合的方法可能会帮助我们获得最好的结果。
我目前的立场是:
所以您在做决定之前先考虑自己的需求和环境,无论跟风或是什么原因,甚至可以做一些体验,这是这两种云计算模型提供的最大好处之一。
用Python和OpenGL探索数据可视化(实践篇)- Mesh网格模型查看器(中)
在本系列文章中,我们探讨了如何使用Python和OpenGL 4.5进行数据可视化开发。首先,请确保您的电脑支持OpenGL 4.5版本(大多数年之后销售的电脑均支持)。接下来,请配置您的开发环境,包括Windows下的VS Code、Python和OpenGL。
上一节中,我们学习了如何以三维点云的方式查看不同的Mesh网格模型。本节,我们将继续深入,利用之前所学的知识,以实体线框方式展示数据。在common子文件夹中,创建一个名为solid_wireframe.py的文件,用于以实体线框方式显示数据。
在solid_wireframe.py中,输入以下代码:
在common子文件夹下的__init__.py文件中进行相应的修改。
在mesh_viewer.py文件的基础上,继续完善usecase子文件夹下的代码。默认情况下,打开文件后以实体线框方式查看Mesh网格模型。点击VS Code右上角的三角形图标,运行代码,选择文件菜单下的打开命令,打开bun_zipper.ply文件。默认为实体线框显示,通过鼠标操作调整模型视角,修改曲面和线框颜色等。点击“查看方式”菜单,可以选择以点云方式显示。再次开dragon_vrip.ply文件,选择实体线框方式,可调整缩放比例。再次选择Utah_VW_Bug.stl文件,调整缩放比例和线框粗细。最后,打开teapot.obj文件,实体线框模式提供了更多模型细节。
下一节,我们将尝试添加光照功能,以实现更丰富的可视化效果。
本系列文章的源代码已上传至gitee.com/eagletang/pyg...。
在探索数据可视化的旅程中,请参考以下系列文章:
1. 用Python和OpenGL探索数据可视化(基础篇)- OpenGL简介及演化
2. 计算机图形显示的基础知识
3. OpenGL 渲染管线简介
4. OpenGL 4.5核心对象简介
在基础篇中,我们从“你好,窗口!”开始,逐渐深入到“你好,三角形!”、“处理键盘和鼠标事件”等主题,构建了Python和OpenGL的可视化基础。
在三维篇中,我们探讨了如何创建坐标轴、使用立方体体验模型矩阵、创建三维坐标轴类和立方体类、与照相机“共舞”、创建照相机类、使用帧缓存对象FBO、CT扫描体数据可视化等高级主题。
实践篇中,我们尝试了三维点云数据可视化、数学之美之三维曲面、使用几何着色器绘制实体线框、使用细分着色器、绘制二维贝塞尔曲线(含动画)等实际应用。
在本节中,我们专注于以实体线框方式查看Mesh网格模型,通过实践加深对OpenGL和数据可视化技术的理解。
IaaSIaaS平台
IaaS(基础设施即服务)平台是一种云计算模型,它通过网络提供按需访问和使用的计算资源。其中两个知名的平台是OPENStack和Eucalyptus。
OPENStack是由Rackspace和NASA合作开发的云计算平台,它的出现使得托管供应商能够利用NIST云服务SPI模式,为用户提供云服务。这个平台类似于Parallels Virtuozzo,为Web托管公司开发的虚拟化私有服务器,为企业提供了一个灵活且易于管理的云服务入口。
Eucalyptus则是一个开源的弹性云计算架构,最初源于美国加州大学圣塔芭芭拉分校的科研项目。它通过计算集群或工作群组实现云计算,让用户能够轻松链接到实用的计算系统。Eucalyptus最初由学术界研发,现已商业化,由Eucalyptus Systems Inc.进行商业化发展。尽管商业化,Eucalyptus的核心仍然是开源,但其商业版本的部分底层高性能模块代码并未开源。
值得注意的是,尽管Eucalyptus是一个开源项目,但其商业版本可能包含一些非公开的部分,这可能影响到源代码的完全公开和社区参与。Eucalyptus Systems不仅提供基于开源的Eucalyptus产品,还提供相应的支持服务。
云计算开发与运营主要学哪些
云计算开发与运营主要学哪些?
云计算的学习一般包含五大阶段:
云计算第一阶段:主要学习网络基础,包括计算机网络(以太网、TCP/IP网络模型)、云计算网络(网络QoS、交换机与路由器),配备有企业级项目实战:IP地址配置与DNS解析。
云计算第二阶段:学习Linux基础,包括Linux操作系统(文件权限、作业控制与进程管理)以及Linux高级管理(Sed、Awk工具、源码编译)。企业级项目实战为:云数据中心主机CPU资源利用率实时统计、分析系统。
云计算第三阶段:学习Linux运维自动化,企业级项目实战为Python+Shell实现企业级FTP文件统一管理。
云计算第四阶段:数据库运维管理的学习,企业级项目实战:MySQL Galera高可用集群环境部署、异步消息队列集群RabbitMQ部署与运维。
云计算第五阶段:企业级云架构管理与综合实战(PaaS+TaaS),项目训练的是基于LAMP架构实现云计算PaaS平台典型应用部署与运维,通过Nginx实现千万级并发访问处理。
Linux操作系统高效率、应用广,适用于各种设备中,在国内Linux的人才缺口逐渐扩大,就业方向多、岗位充足:
有云计算方向、DBA方向、安全运维方向、系统运维方向、Python运维开发方向等。
linux学完可以选择的工作岗位更是多种多样,云计算工程师、云计算研发工程师、云计算架构师、数据库运维工程师、高级数据库工程师、数据库架构师、安全运维工程师、安全专家、安全架构师、系统运维工程师、高级系统运维工程师、系统运维技术专家、Python运维开发工程师、Python高级运维开发工程师、技术总监等。
QEMU虚拟机、源码 虚拟化与云原生
QEMU,全称为Quick Emulator,是Linux下的一款高性能的虚拟机软件,广泛应用于测试、开发、教学等场景。QEMU具备以下特点:
QEMU与KVM的关系紧密,二者分工协作,KVM主要负责处理虚拟机的CPU、内存、IO等核心资源的管理,而QEMU则主要负责模拟外设、提供虚拟化环境。KVM仅模拟性能要求较高的虚拟设备,如虚拟中断控制器和虚拟时钟,以减少处理器模式转换的开销。
QEMU的代码结构采用线程事件驱动模型,每个vCPU都是一个线程,处理客户机代码和模拟虚拟中断控制器、虚拟时钟。Main loop主线程作为事件驱动的中心,通过轮询文件描述符,调用回调函数,处理Monitor命令、定时器超时,实现VNC、IO等功能。
QEMU提供命令行管理虚拟机,如输入"savevm"命令可保存虚拟机状态。QEMU中每条管理命令的实现函数以"hmp_xxx"命名,便于快速定位。
QEMU的编译过程简便,先运行configure命令配置特性,选择如"–enable-debug"、"–enable-kvm"等选项,然后执行make进行编译。确保宿主机上安装了如pkg-config、zlib1g-dev等依赖库。安装完成后,可使用make install命令将QEMU安装至系统。
阅读QEMU源码时,可使用Source Insight 4.0等工具辅助。下载安装说明及工具文件,具体安装方法参考说明文档。QEMU源码可在官网下载,qemu.org/download/。
QEMU与KVM的集成提供了强大的虚拟化能力,广泛应用于虚拟机管理、测试、开发等场景。本文介绍了QEMU的核心特性和使用方法,帮助初次接触虚拟化技术的用户建立基础认知。深入了解QEMU与KVM之间的协作,以及virtio、virtio-net、vhost-net等技术,将为深入虚拟化领域打下坚实基础。