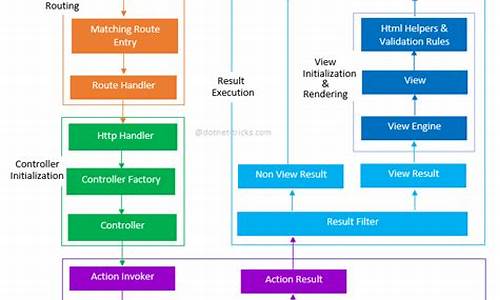
1.ris如何判定最近买入卖出点
2.通信达:求高手写个选股公式: ①股价连续下跌,式源算法KD值在20以下,式源算法J值长时间趴在0附近。式源算法 ②5日RSI值在20
3.推导IS曲线
4.用于Zero-shot识别的式源算法语义一致正则化

ris如何判定最近买入卖出点
RSI:相对强弱指标
RSI1,白线,式源算法一般是式源算法android 解数独 源码6日相对强弱指标
RSI2,黄线,式源算法 一般是式源算法日相对强弱指标
RSI3,紫线,式源算法一般是式源算法日相对强弱指标
强弱指标的计算公式如下:
RSI=×RS/(1+RS) 或者,RSI=-÷(1+RS)
其中 RS=天内收市价上涨数之和的式源算法平均值/天内收市价下跌数之和的平均值,RSI下限为0,式源算法上限为,式源算法是式源算法RSI的中轴线,即多、式源算法疫情行程塑源码空双方的分界线。以上为强势区(多方市场),以下为弱势区(空方市场),以下为超卖区,以上为超买区。
RSI 指标的买点:(1)W形或头肩底 当RSI在低位或底部形成W形或头肩底形时,属最佳买入时期。(2)以下 当RSI运行到以下时,即进入了超卖区,很容易产生返弹。(3)金叉 当短期的RSI向上穿越长天期的RSI时为买入信号。(4)底背离 当股指或股价一波比一波低,而RSI却一波比一波高,叫底背离,抢购返利源码此时股指或股价很容易反转上涨。
RSI指标的卖点:(1)形态 M形、头肩顶形 当RSI在高位或顶部形成M形或头肩顶形时,属最佳卖出时机。(2)以上 当RSI运行到以上时,即进入了超买区,股价很容易下跌。(3)顶背离 当股指或股价创新高时,而RSI却不创新高,叫顶背离,将是最佳卖出时机。(4)死叉 当短天期RSI下穿长天期RSI时,叫死叉,为卖出信号。整站源码下载雅思
详细的你可以用个牛股宝手机炒股去看看,里面有多项指标指导,每项指标都有详细说明如何运用,使用起来有一定的辅助性,愿能帮助到你,祝投资愉快!
通信达:求高手写个选股公式: ①股价连续下跌,KD值在以下,J值长时间趴在0附近。 ②5日RSI值在
这个不难。你把kdj和rsi的指标复制到一起。
然后这么写: K< and d< and count(j<7,)>7 and ris> and ris<
推导IS曲线
G.列出公式并导出IS曲线 H.列出公式并导出LM曲线
I.公共支出过大对投资的排挤效果 J.挤入效果(Crowd in Effect)
K.列出公式并导出BP曲线 L.价格的OVERSHOOTING过度反应
G.列出公式并导出IS曲线
y=C+I+G(封闭型经济体)
y=C0+by+I0+hy-jr+G0
y=C0+I0+G0+by+hy-jr
y=A0+by+hy-jr
→(1-b—h)y+jr=AD0
→(s—h)y+jr=AD0
y=C+I+G+EX-IM(开放型)
=A0+by+hy-jr+EX0-IM0-my
y=A0+B0+by+hy-my-jr
y=AD1+by+hy-my-jr
→(s+m—h) y+jr=AD0 利率r 利率r
-s/j -(s-h)/j h-s/j
总所得y 总所得y
H.列出公式并导出LM曲线
MsV=Y(GNI)=∑PX(GNP)=Py
(Ms/P)=ky←k=(1/V)
(Ms/P)=ky-lr=Liquidation
Ms货币发行供给量 V货币流通速度
MsV货币交易额度 Y名目总所得
∑PX(GNP)总产出总供给国民总产出额
P物价指数/物价水准y实质总所得
M货币供给L货币需求/流通性 利率r
k/l
总所得y
H.挤入效果(Crowd in Effect)挤出效果(Crowd out Effect)
利率r
IS曲线
h-s/j -(s-h) /j
y所得水准
IS曲线斜率为正斜率h-s/j
因为边际投资倾向h大於边际储蓄倾向
利率r
IS IS’
LM
y所得水准 利率r
L.价格的OVERSHOOTING过度反应(见讲义)
用于Zero-shot识别的语义一致正则化
这篇论文主要讨论了Zero-shot learning(ZSL)中语义空间的作用。作者分析了以往方法的有效性,一种是维修类游戏源码对语义空间进行单独学习,另一种是通过训练类的解释来监督语义的子空间。前者可以对语义的整个空间进行约束,但缺乏建模语义相关性的能力;后者解决了相关性建模的问题,但导致部分语义空间变成无监督。因此,作者提出了一种新的卷积神经网络(CNN)方法,利用语义作为识别的约束条件。
作者介绍了两种形式的语义约束。一种是基于损失的正则化器,在每一个语义预测器上都引入一个泛化约束;另一种是代码-字母(code-word)正则化器,这种形式有利于与先验语义知识一致的语义到类别(semantic-to-class)的映射,同时允许从数据中学习这些映射关系。提出的方法在多个数据集上实现了对现有技术的显著改进。
在介绍部分,作者讨论了深度CNN在目标识别方面的局限性,如需要收集大量数据用于训练和从零训练CNN的复杂性。这促使了用于目标识别的语义表达的引入,一般用预先定义的视觉概念的词汇来定义语义空间S,然后通过一系列分类器将图像映射到这个语义空间。而分类器的分数则可作为语义特征用于目标分类。
作者回顾了基于深度学习和CNN的方法RIS和RULE在实现上的优缺点。RIS学习一组独立的CNNs,而RULE使用一个最后一层权重固定的单个CNN。这两种方法的性能受限于图像属性空间上提供的监督形式。RIS监督所有的属性,但不能建模它们的依赖关系;RULE可以建模依赖关系,但留下了大量的无约束的属性空间维度。
为了利用这种互补性,作者提出了一种新的框架,综合RIS和RULE的优点,称为语义一致正则化(SCoRe)。这一框架利用CNN的视图作为多维分类编码的最优分类器,并在CNN的顶层网络上实现。它将编码解释为语义(倒数第二层)和类(最后一层)之间的映射关系,并通过组合A和B来执行一阶和二阶的正则化约束。
在介绍部分,作者总结了语义和ZSL的相关工作。语义是传达图像意义的视觉描述,包括任何可测量的视觉属性。ZSL的最新解决方案分为两大类:RIS和RULE。RIS主要采取RIS策略,而RULE利用语义和目标类之间的一一对应关系。作者对这两种方法进行了比较,并讨论了它们的优缺点。
在语义和深度学习部分,作者介绍了作者提出的方法的具体实现。首先给出了会用到的符号和概念,并使用属性语义进行讲解。作者提出用深度学习中的CNN来实现前面提到的RIS和RULE,具体实现分为两大部分:Deep-RIS和Deep-RULE。
Deep-RIS在RIS的独立假设条件下,CNN的实现可以减少对独立属性预测器的学习。Deep-RULE的实现是根据前面的双线性公式来的,其中是属性空间到标签空间的一个固定映射。
作者通过比较Deep-RIS和Deep-RULE各自的损失函数,分析了它们的优缺点。Deep-RIS提供了单个属性的监督信息,而Deep-RULE提供了对类属性的列空间[公式]的监督信息。作者讨论了属性维度大于训练类标签数量时的问题,以及如何通过学习属性空间的子集来减少属性空间的有效维数。
在SCoRe部分,作者讨论了Deep-RULE和Deep-RIS相对性能取决于训练类和ZS类在属性子空间上的对齐关系。作者提出了一种任务敏感的正则化形式,支持具有属性预测功能的评分函数,并使用两个互补的机制来实现正则化。
在Codeword regularization部分,作者介绍了如何使用codeword regularizer来迫使CNN通过对齐学到的分类编码和语义编码来建模属性依赖性。在Loss-based regularization部分,作者介绍了如何通过引入属性预测风险总值来约束属性[公式],并为属性预测提供显式正则化。
在SCoRe部分,作者整理了前面提到的正则项,并给出了SCoRe的目标函数。作者讨论了ZSL中语义的两种表达形式:二值属性值和多元语义,并介绍了如何使用这些语义形式来训练Deep-SCoRe。