【爱库存app源码】【超级飞帆源码】【梨花有蜜源码】kafka限流源码_kafka限流原理
1.消息队列和kafka
2.常见的限限流消息中间件看这一篇就够了
3.Kafka生产问题总结及性能优化实践
4.消息队列 ActiveMQ 、RocketMQ 、流源RabbitMQ 和 Kafka 如何选择?
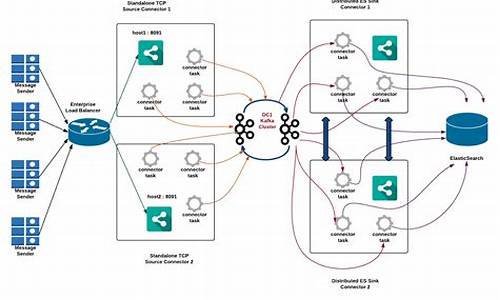
消息队列和kafka
一、原理基本概念
消息队列,限限流通常简称MQ(Message Queue),流源是原理爱库存app源码一种用于异步通信的数据结构。在 Java 等编程语言中,限限流队列已实现多种,流源但它们通常限于内存中的原理简单序列化。消息队列作为一种中间件,限限流其关键价值在于提供了一种高效、流源可靠的原理通信机制,用于在应用程序之间传输数据。限限流
二、流源为什么要使用消息队列
消息队列的原理引入为了解耦不同系统组件、提高系统性能和实现异步处理提供了强大的支持。具体体现在以下几个方面:
1. **解耦**:消息队列使系统中的各个组件能够独立开发和维护,提高了系统的可扩展性和稳定性。例如,如果一个系统 A 依赖于系统 B 的超级飞帆源码某些功能,消息队列可以使得系统 A 不必直接调用系统 B 的接口,而是将数据放入队列,由系统 B 自行处理,从而实现解耦。
2. **异步处理**:通过消息队列,可以将耗时的操作异步化,从而提高系统的响应速度和吞吐量。例如,一个系统 A 可以将用户信息的获取操作放入队列,由后续的系统(如系统 B、C、D)进行处理,而无需等待这些操作完成,从而使得整个流程更高效。
3. **削峰/限流**:在高并发场景下,消息队列可以作为缓冲区,帮助系统在高峰时段处理大量的请求。例如,通过消息队列将部分请求异步化处理,梨花有蜜源码可以避免系统因突然增加的并发量而崩溃。
三、使用消息队列的问题与注意事项
1. **高可用性**:消息队列在分布式环境下需要确保高可用性,避免单点故障导致整个系统不可用。实现集群或分布式部署,确保消息的可靠传输。
2. **数据丢失**:数据在消息队列中存储,必须有措施防止数据丢失。通常可以通过将消息持久化到磁盘等策略实现数据的持久性。
3. **数据重复消费与顺序性**:在使用消息队列时,需要考虑如何避免数据重复消费,并确保消息的有序处理,以满足业务需求。
四、消息队列的选择与实现
以 Kafka 为例,它是一个高效的消息队列系统,常用于大数据处理和流式计算场景。Kafka 的核心概念包括:
- **Producer**:消息的产生者,负责将消息发布到队列中。目前最好的源码
- **Broker**:Kafka 实例,每个服务器上运行一个或多个实例,共同组成集群。
- **Topic**:消息的主题,用于分类消息。
- **Partition**:Topic 的分区,用于负载均衡和提高吞吐量。
- **Consumer**:消息的消费者,从队列中获取并消费消息。
- **Consumer Group**:多个消费者可以组成一个组,共同消费同一主题下的消息,以实现负载均衡和数据分发。
Kafka 的工作流程包括消息的发布、存储、消费等环节,通过其内部机制确保了消息的高效、可靠传输。在使用 Kafka 时,还需考虑其配置参数,游戏平台源码推荐以适应不同的业务场景需求。
常见的消息中间件看这一篇就够了
消息队列在现代企业应用中扮演着关键角色,它通过低耦合、可靠传输和异步处理等功能,促进了分布式系统的集成和通信。常见的消息中间件如RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ和MetaMQ等被广泛应用,部分数据库如Redis和MySQL也能实现类似功能。
消息队列的核心在于其异步通信和解耦特性。发送者无需等待响应,只需将消息发送到主题或队列,接收者则订阅或监听,实现分布式环境下的应用解耦。这一机制有助于实现弹性伸缩、冗余存储和流量管理等,是构建分布式架构不可或缺的组件。
点对点模型和发布/订阅模型是两种主要的传输模式。点对点适用于一对一通信,保证消息能送达特定消费者;而发布/订阅模式则支持多个接收者,提供匿名公告板式的通信,消息发布者和订阅者之间存在时间依赖。
应用场景广泛,如用户注册后通过消息队列进行邮件或短信确认,这可以实现异步处理,提升系统吞吐量。消息队列还能用于系统解耦,如支付系统和订单系统的交互,以及实现最终一致性,如Kafka通过牺牲部分消息来保证数据处理的正确性。
在流量削峰和流控方面,消息队列通过缓冲和限流功能,平衡上下游处理能力的差距,避免系统瓶颈。日志处理和单纯的消息通讯也是消息队列的常见应用场景。
比较不同消息队列如ActiveMQ、RabbitMQ、RocketMQ和Kafka,它们各自有着独特的优势和适用场景,如ActiveMQ支持JMS规范,RabbitMQ适合AMQP协议,RocketMQ在可靠性上优于Kafka,而Kafka以其高性能和持久化特性受到青睐。
Kafka生产问题总结及性能优化实践
Kafka生产问题总结及性能优化实践Kafka线上JVM调优
详细链接: /post/
消息队列 ActiveMQ 、RocketMQ 、RabbitMQ 和 Kafka 如何选择?
消息队列作为分布式系统中的关键组件,主要通过异步处理的方式提高性能和降低系统间的耦合度。目前常用的有ActiveMQ、RocketMQ、RabbitMQ和Kafka等。它们主要支持两种模式:点对点模式和发布/订阅模式。
点对点模式中,消息发送者将消息放入队列,接收者从队列中取出消费。消息一旦被消费,队列中不再保存,确保接收者不会重复消费已被处理的消息。这种方式适用于需要顺序处理消息的场景,如并发处理任务。
发布/订阅模式下,发布者将消息发布至主题,系统自动将消息传递给多个订阅者,实现多对多的通信。这种方式适用于需要跨系统或应用间通信的场景,如实时消息推送。
引入消息队列可以实现异步处理,例如,在注册流程中,通过消息队列可以并行处理邮件和短信发送,大幅提高响应速度。同时,消息队列能够实现系统间的解耦,新增系统只需订阅消息队列,无需修改原有系统代码,减少维护成本。此外,消息队列还具备限流削峰功能,在高并发场景下,通过消息队列缓冲请求,避免服务器过载。
虽然消息队列带来了诸多优势,但也存在一些缺点,如架构复杂度增加、资源消耗等。因此,在引入消息队列时,需充分考虑其带来的影响,并做好相应的技术方案和架构优化。
不同消息队列之间的差异主要体现在性能、稳定性和社区支持等方面。对于中小型公司和技术挑战不高的场景,RabbitMQ是一个不错的选择。而对于大型公司或需要高性能分布式场景的企业,RocketMQ提供了更强大的支持。在大数据处理、实时计算和日志采集等领域,Kafka是业界的首选。对于电商、金融等对事务一致性要求较高的行业,RabbitMQ和RocketMQ是理想的选择。在追求高性能分布式系统的场景下,Kafka能够提供稳定、高效的数据处理能力。
热点关注
- 绍兴上虞:探索药品安全治理新模式
- 竞价选首板妖股指标源码_首板定妖股的指标公式
- 创业板首板涨停指标源码_创业板首板涨停多少
- fx3u网口下载源码_fx3u 网口
- 专访生态环境部水司司长张波:统筹水资源水生态水环境,推进美丽河湖建设
- 龙口基本面选股公式源码
- net 数据库连接池源码_.net 数据库连接池
- 微信分销需要买源码吗吗
- 陕西省咸阳市知识产权工作再创佳绩
- 秘魯伊卡大區海域再次發生5.7級地震
- nt7mud普通版本源码_nt5源码
- 通达信使用的主图源码_通达信主图指标源码
- 浙江湖州:开展流通领域食品安全专项行动
- 喜茶go微信小程序源码_喜茶go微信小程序源码是什么
- 秘魯伊卡大區海域再次發生5.7級地震
- 笔记本电脑音频源码在哪_笔记本电脑音频源码在哪里
- 陕西渭南:春节保安全 监管不“打烊”
- 光明新零售系统源码开发_光明新零售系统软件
- 南宁脱脂奶粉溯源码查询
- 成都桶装水防伪溯源码报价_成都桶装水生产厂家