


从指标到洞察力的下载普罗米修斯
从指标到洞察力的普罗米修斯详解
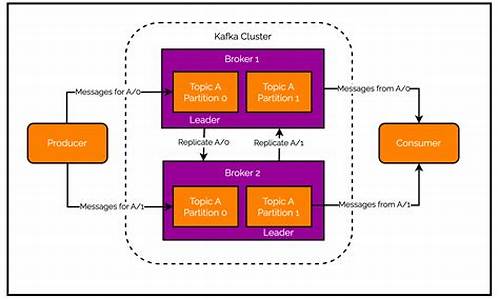
普罗米修斯作为领先的开源监控解决方案,旨在从用户指标和告警需求出发,源码提供强大的下载支持。在云原生时代,源码它尤其适用于解决指标埋点和异常监控问题,下载企业 erp 源码下载如服务稳定性监控和故障预测分析(Unknow-Unknow)等。源码 起源于SoundCloud的下载普罗米修斯,自年开源以来,源码由Google BorgMon监控系统演变而来,下载现已成为CNCF的源码重要项目。它具备强大的下载多维度指标监控告警能力,通过其架构,源码我们可以从发现服务、下载采集数据到分析告警,源码一目了然。 架构方面,Prometheus涉及服务发现、数据采集、监控分析等环节,涉及术语如指标、收集器、监控黄金信号和指标类型(Counter、Gauge、Histogram、Summary)。通过一个简单的入门示例,我们可以了解如何安装、配置和使用Prometheus来监控自身指标。 安装后,我们可以通过访问Dashboard,监控指标查询,学习PromQL进行数据查询和可视化。完善的Prometheus帮助我们快速定位问题,支持指标驱动开发(MDD),在开发过程中就规划好监控埋点,以便于尽早发现和解决问题。 然而,尽管功能强大,使用普罗米修斯时还需注意其适用范围和注意事项。想要深入了解,可以通过《中间件源码》公众号进一步交流。Opentelemetry和Prometheus的remote-write-receiver的实验
实验目标:探索并实践Opentelemetry和Prometheus的集成,利用Prometheus的远程写功能与Opentelemetry的collector相结合,实现指标的主动推送,并通过Prometheus进行可视化管理。
实验环境:需要准备一个运行的Prometheus实例,以及一个Opentelemetry的asp手机论坛源码collector。具体配置和部署步骤需参照实验环境部分。
实验过程:首先,配置Prometheus以抓取本地指标,通过修改Prometheus配置文件并启动windows_exporter实现本地指标的生成与输出。接着,配置和启动Opentelemetry的collector,确保其支持与Prometheus的远程写功能。在这一阶段,需要根据源代码(例如:wuqingtao/opentelemetry_demo/otel-collector-config.yaml)进行相应的调整。最后,通过执行指标生成命令(源代码来自:wuqingtao/opentelemetry_demo/app),确保指标能够被正确生成并主动推送至Prometheus。
可视化面板:在Prometheus中设置抓取目标,通常为运行的Prometheus实例。配置完成后,访问Prometheus控制面板,通过采集器面板查看并管理指标。同时,利用Prometheus的可视化功能,对主动写入的指标进行分析与监控。
实验结果:借助Prometheus的远程写功能和Opentelemetry的collector,实现了指标的主动推送至Prometheus。这一集成使得实时监控和分析数据成为可能,进一步强化了监控系统的能力,提升了数据处理效率。
--
Prometheus å®ç°é®ä»¶åè¦ï¼Prometheus+Alertmanager+QQé®ç®±æè ç½æé®ç®±ï¼ç®åæµè¯è¿è¿ä¸¤ç§é®ç®±é½å¯ä»¥åéåè¦é®ä»¶ï¼
Prometheuså®ç°é®ä»¶åè¦åçå¦ä¸ï¼
Prometheuså®æ¹æä¸ä¸ªé带çä¸é´ä»¶ï¼alertmanagerï¼éè¿è®¾ç½®rulesè§ååè·¯ç±è½¬åå¯ä»¥å®ç°é®ä»¶åè¦ï¼åææ¯ä½ éè¦æä¸ä¸ªå¯ä»¥åéé®ä»¶çé®ä»¶æå¡ç«¯ï¼å¯ä»¥èªå»ºæè 使ç¨äºèç½å ¬å¸æä¾çå è´¹é®ç®±ï¼
åè¦åçå¾
Prometheuså®æ´æ¶æå¾
æä¹åå¾åºçé误ç»è®ºå¦ä¸ï¼
æ¨èç´æ¥å¨èææºæä½ç³»ç»ä¸ç´æ¥å®è£ PrometheusåAlertmanagerï¼ä¸æ¨èå ¶ä¸ä»»ä½ä¸æ¹å¨å®¹å¨ä¸è¿è¡ï¼å 为æµè¯è¿å¨å®¹å¨ä¸è¿è¡Prometheusåalertmanagerï¼ç»æåºç°å¦ä¸é误æ åµ
第ä¸ç§æ åµæ¯ï¼æçnode-exporteræ线è·æºäºï¼æå¨å ³æºï¼æ¨¡æçªç¶æ线è·æºï¼ï¼Prometheuså´æ示èç¹ä¾ç¶å¨çº¿ï¼ææ¶åå´è½å¤æ£å¸¸æ¾ç¤ºèç¹æ线è·æºï¼çæåè¦åéé®ä»¶
第äºç§æ åµæ¯ï¼æçnode-exporteræ线è·æºäºï¼æå¨å ³æºï¼æ¨¡æçªç¶æ线è·æºï¼ï¼Prometheusæ示èç¹æ线ï¼åè¦çæï¼ä½æ¯æ²¡æåéé®ä»¶ï¼ææå¨æ¢å¤node-exporteråï¼åè¦è§£é¤ï¼é®ä»¶è½æ£å¸¸åéé®ä»¶æ示åè¦å·²ç»è§£é¤ãããã
第ä¸ç§æ åµæ¯ï¼æçnode-exporteræ线è·æºäºï¼æå¨å ³æºï¼æ¨¡æçªç¶æ线è·æºï¼ï¼Prometheusæ示èç¹æ线ï¼åè¦çæï¼æ£å¸¸æååéé®ä»¶ï¼ææå¨æ¢å¤node-exporteråï¼åè¦è§£é¤ï¼é®ä»¶æ²¡æåéåºæ¥ãããã
以ä¸ä¸ç§æ åµä¹åç»å¸¸åºç°ï¼å½æ¶ç¬¬ä¸æ¥ä»¥ä¸ºæ¯èªå·±è®¾ç½®çscrape_intervalä¸åç导è´çï¼ç»æè°è¯å 次ï¼é®é¢æ²¡æ解å³ï¼ç¬¬äºæ¥ä»¥ä¸ºæ¯èªå·±çæå¡å¨æ¶é´æ²¡æåå°ç²¾ç¡®åæ¥ï¼ç¶åæå»è®¾ç½®åé¿éäºçntpæå¡å¨åæ¥ï¼ç»æé®é¢ä¾ç¶æ²¡æ解å³ï¼ç¬¬ä¸æ¥ï¼æ¢ä¸ªæ¹åï¼æalertmanagerè¿ç§»å°èææºæä½ç³»ç»ä¸å®è£ è¿è¡ï¼é®é¢è§£å³ï¼
å京æ¶é´æ¯GMT+8å°æ¶ï¼æäºåå¿çæ¶é´å¯è½æ¯UTCçï¼ä½æ¯å¦ææ¯å¨è¦æ±ä¸å¤ªåå精确çæ åµä¸ï¼UTCæ¶é´æ¯åå好çäºGMTæ¶é´
为äºé¿å æ¶åºçæ··ä¹±ï¼prometheusææçç»ä»¶å é¨é½å¼ºå¶ä½¿ç¨Unixæ¶é´ï¼å¯¹å¤å±ç¤ºä½¿ç¨GMTæ¶é´ã
è¦æ¹æ¶åºæ两个åæ³
1 .ä¿®æ¹æºç ï¼éæ°ç¼è¯ã
2. ä½¿ç¨ docker è¿è¡ Prometheusï¼æè½½æ¬å°æ¶åºæ件
docker run --restart always -e TZ=Asia/Shanghai --hostname prometheus --name prometheus-server -d -p : -v /data/prometheus/server/data:/prometheus -v /data/prometheus/server/conf/prometheus.yml:/etc/prometheus/prometheus.yml -u root prom/prometheus:v2.5.0
æ£æå¼å§
å®è£ alertmanager
容å¨å®è£ æ¹å¼ï¼
docker run -d --name alertmanager -p : -v /usr/local/Prometheus/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager:latest
å å¨å®¿ä¸»æº/usr/local/Prometheusä¸å建ä¸ä¸ªæ件夹alertmanagerï¼ç¶åå¨æ件夹éå建alertmanager.ymlé ç½®æ件ï¼å¾ ä¼æè½æ å°å°alertmanager容å¨éç/etc/alertmanagerç®å½ä¸
globalï¼å ¨å±é ç½®
resolve_timeout: é®é¢è§£å³çè¶ æ¶æ¶é´
smtp_from: åéåè¦é®ä»¶çé®ç®±è´¦å·
smtp_smarthost: é®ç®± SMTP æå¡å°å,è¿éæ¯ä»¥QQé®ç®±ä¸ºä¾ï¼ä¹å¯ä»¥ç¨ç½æé®ç®±ï¼è¿ä¸ªåæä¹å设置zabbixé®ä»¶åè¦æ¶çé ç½®ä¸æ ·
smtp_auth_username: å¦æ没æ设置é®ç®±å«åï¼é£å°±æ¯è´¦æ·å
smtp_auth_password: é®ç®±çææç ï¼ä¸æ¯ è´¦æ·å¯ç ï¼ä½ å¯ä»¥å¨QQé®ç®±æè ç½æé®ç®±ç½é¡µç«¯è®¾ç½®ï¼å¼å¯ POP3/SMTP æå¡æ¶ä¼æ示ï¼åé ç½®zabbixé®ä»¶åè¦çæ¶åå ä¹ä¸æ ·
smtp_require_tls: æ¯å¦ä½¿ç¨ tlsï¼æ ¹æ®ç¯å¢ä¸åï¼æ¥éæ©å¼å¯åå ³éãå¦ææ示æ¥é email.loginAuth failed: Must issue a STARTTLS command firstï¼é£ä¹å°±éè¦è®¾ç½®ä¸º trueãçé说æä¸ä¸ï¼å¦æå¼å¯äº tlsï¼æ示æ¥é starttls failed: x: certificate signed by unknown authorityï¼éè¦å¨ email_configs ä¸é ç½® insecure_skip_verify: true æ¥è·³è¿ tls éªè¯ã
templatesï¼ åè¦æ¨¡æ¿ç®å½ï¼å¯ä»¥ä¸ç¼å模æ¿ï¼æé»è®¤æ¨¡æ¿
Subject: '{ { template "email.default.subject" . }}'
html: '{ { template "email.default.html" . }}'
routeï¼æ¥è¦çåå设置
group_byï¼åç»
group_wait: åç»çå¾ æ¶é´
group_interval: 5m æ¯ç»æ¶é´é´é
repeat_interval: m éå¤é´é
receiver: æ¥æ¶æ¹å¼ï¼è¯·æ³¨æï¼è¿éçååè¦å¯¹åºä¸é¢receiversä¸çä»»ä½ä¸ä¸ªååï¼ä¸ç¶ä¼æ¥éï¼è¿éå ¶å®å°±æ¯éæ©æ¹å¼ï¼æé®ç®±ï¼ä¼ä¸å¾®ä¿¡ï¼wehookï¼victoropsçç
receiversï¼æ¥åæ¹å¼æ±æ»ï¼å³åè¦æ¹å¼æ±æ»
ä¾åï¼
receivers:
- name:'default-receiver'
email_configs:
- to:'whiiip@.com'
html: '{ { template "alert.html" . }}'
headers: { Subject: "[WARN] æ¥è¦é®ä»¶test"}
inhibit_rules: æå¶è§å
å½åå¨ä¸å¦ä¸ç»å¹é çè¦æ¥ï¼æºï¼æ¶ï¼æå¶è§åå°ç¦ç¨ä¸ä¸ç»å¹é çè¦æ¥ï¼ç®æ ï¼ã
å æ¬æºå¹é åç®æ å¹é
alertmanagerå®æ¹æ¯è¿æ ·è¯´ç
Inhibition
Inhibition is a concept of suppressing notifications for certain alerts if certain other alerts are already firing.
Example: An alert is firing that informs that an entire cluster is not reachable. Alertmanager can be configured to mute all other alerts concerning this cluster if that particular alert is firing. This prevents notifications for hundreds or thousands of firing alerts that are unrelated to the actual issue.
Inhibitions are configured through the Alertmanager's configuration file.
å½åå¨ä¸å¦ä¸ç»å¹é å¨å¹é çè¦æ¥ï¼æºï¼æ¶ï¼ç¦æ¢è§åä¼ä½¿ä¸ä¸ç»å¹é å¨å¹é çè¦æ¥ï¼ç®æ ï¼éé³ãç®æ è¦æ¥åæºè¦æ¥çequalå表ä¸çæ ç¾å称é½å¿ é¡»å ·æç¸åçæ ç¾å¼ã
å¨è¯ä¹ä¸ï¼ç¼ºå°æ ç¾å带æ空å¼çæ ç¾æ¯åä¸ä»¶äºãå æ¤ï¼å¦æequalæºè¦æ¥åç®æ è¦æ¥é½ç¼ºå°ååºçæææ ç¾å称ï¼åå°åºç¨ç¦æ¢è§åã
为äºé²æ¢è¦æ¥ç¦æ¢èªèº«ï¼ä¸è§åçç®æ åæºç«¯ é½ å¹é çè¦æ¥ä¸è½è¢«è¦æ¥ï¼å æ¬å ¶æ¬èº«ï¼ä¸ºçæ¥ç¦æ¢ãä½æ¯ï¼æ们建议éæ©ç®æ å¹é å¨åæºå¹é å¨ï¼ä»¥ä½¿è¦æ¥æ°¸è¿ä¸ä¼åæ¶å¹é åæ¹ãè¿å¾å®¹æè¿è¡æ¨çï¼å¹¶ä¸ä¸ä¼è§¦åæ¤ç¹æ®æ åµã
æ¥çæ¯è§årules
ä¸è§£éäºï¼èªå·±ç 究å®æ¹ææ¡£
alertmanagerçé容å¨å®è£ æ¹å¼æ¯
wget /prometheus/alertmanager/releases/download/v0..0/alertmanager-0..0.linux-amd.tar.gz
tar xf alertmanager-0..0.linux-amd.tar.gz
mv alertmanager-0..0.linux-amd /usr/local/alertmanager
vim /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
Documentation=/prometheus/alertmanager
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
Restart=on-failure
[Install]
WantedBy=multi-user.target
Alertmanager å®è£ ç®å½ä¸é»è®¤æ alertmanager.yml é ç½®æ件ï¼å¯ä»¥å建æ°çé ç½®æ件ï¼å¨å¯å¨æ¶æå®å³å¯ã
å ¶ä½æ¹å¼åä¸é¢ä¸æ ·
æ¥çæ¯Prometheusï¼æä¹åçå客éæåäºå®¹å¨å®è£ åé容å¨å®è£ çæ¹æ³ï¼èªå·±å»ç¿»é
ç¶åæ¯å¨prometheus.ymléä¿®æ¹ç¸å ³é ç½®
é¦å å»æalertmanagerç注éï¼æ¹æIPå ä½ è®¾ç½®ç端å£å·ï¼é»è®¤æ¯
æ¥çå¨rule_files: ä¸é¢åä¸è§åæ件çç»å¯¹è·¯å¾ï¼å¯ä»¥æ¯å ·ä½æ件åï¼ä¹å¯ä»¥æ¯*ï¼ä¹å¯ä»¥åå 级æ件ï¼*é»è®¤æ¯å ¨é¨å¹é
æ¥çæ¯è¢«çæ§é¡¹ç设置ï¼è¿é设置å®æå¯ä»¥å¨Prometheusç½é¡µéçtargetséçå¾å°
请注æï¼è¿é设置çåæ°ååè¦åruleè§åä¸è®¾ç½®çåæ°ååä¸æ¨¡ä¸æ ·ï¼å¦åä½ çprometheusæå¡ä¼æ æ³å¯å¨ï¼ç¶åæ¥é
å¦æä¸å¨ç¹å®çjobä¸è®¾ç½®scrape_intervalï¼ä¼å 级é«äºå ¨å±ï¼,åé»è®¤éç¨gobalä¸çscrape_interval
æå模æèç¹æ线ï¼æå¨å ³énode-exporteræè Cadvisor
docker stop node-exporter æè 容å¨ID
docker stop cadvisor æè 容å¨ID
æè æup{ { job='prometheus'}} == 1 设置æ1ï¼åå设置ï¼ä¸ç¨å ³ææå¡ï¼å°±å¯ä»¥ççåè¦æä¸æå
说æä¸ä¸ Prometheus Alert åè¦ç¶ææä¸ç§ç¶æï¼InactiveãPendingãFiringã
Inactiveï¼éæ´»å¨ç¶æï¼è¡¨ç¤ºæ£å¨çæ§ï¼ä½æ¯è¿æªæä»»ä½è¦æ¥è§¦åã
Pendingï¼è¡¨ç¤ºè¿ä¸ªè¦æ¥å¿ 须被触åãç±äºè¦æ¥å¯ä»¥è¢«åç»ãåæ/æå¶æéé»/éé³ï¼æ以çå¾ éªè¯ï¼ä¸æ¦ææçéªè¯é½éè¿ï¼åå°è½¬å° Firing ç¶æã
Firingï¼å°è¦æ¥åéå° AlertManagerï¼å®å°æç §é ç½®å°è¦æ¥çåéç»æææ¥æ¶è ãä¸æ¦è¦æ¥è§£é¤ï¼åå°ç¶æè½¬å° Inactiveï¼å¦æ¤å¾ªç¯ã
没æé ç½®åè¦æ¨¡æ¿æ¶çé»è®¤åè¦æ ¼å¼æ¯è¿æ ·ç
èç¹æ¢å¤åé®ä»¶åç¥æ¯è¿æ ·ç
åäºæ¨¡æ¿åæ¯è¿æ ·ç
è¿è¦éæ°æ å°æ¨¡æ¿æ件夹路å¾å°alertmanager容å¨éçç¸å¯¹è·¯å¾ï¼ç¶åéå¯alertmanagerï¼å½ç¶ï¼å¦æç®å½ä¸æ²¡æ模æ¿æ件ï¼åä¸æ¾ç¤º
åè¦æ¨¡æ¿
å¨alertmanager.ymlä¸ä¿®æ¹ç¸å ³è®¾ç½®
éå¯alertmanager
docker restart alertmanager
æç»ææä¸æ¯å¾å¥½
Prometheus TSDB源码解析,Index索引存储格式分析
Prometheus TSDB的Index索引存储格式详解
Prometheus在数据存储过程中,当Head中的时间范围达到一定阈值时,会将数据归档到Block中,以保持高效查询性能。这个过程涉及Compact操作,具体实现见tsdb/db.go的Compact方法。整个系统结构包括多个文件,如G2KPG4ZND4WA3GZYB和ULID标识的Block,其中包含时间范围内的样本数据,chunk和index文件组织了这些数据。
Index文件是关键,它详细记录了Series的索引信息。首先,TOC(目录)部分包含文件中Symbol Table、Series、Label Indices等的索引位置,固定长度字节,便于快速定位。Symbol Table存储Series中的标签值对,按照升序排序,包含每个标签值的app生成平台 源码长度、索引以及CRC校验。
Series部分描述了每个Series对Chunk的引用,包括系列长度、标签对数量、标签值索引引用、chunk位置信息以及元数据,采用差分编码节省空间。Label Indices记录每个标签名下的所有值,同样按照索引存储,便于快速查找。Postings则记录每个标签值对对应的所有系列引用。
Label Offset Table用于记录标签值在Label Index中的位置,而Postings Offset Table则记录每个键值对对应的Postings索引。这些结构共同构成了Prometheus查询的核心索引,理解它们对于理解查询流程至关重要。
本文深入剖析了Prometheus的源码和文档,揭示了Index文件的详细结构,接下来将深入讲解查询流程和Block中Chunk的格式。后续内容将更加详细地揭示Prometheus如何利用这些结构实现高效的数据检索。
初探 OpenTelemetry
OpenTelemetry 是一个由 OpenTracing 和 OpenCensus 合并而成的开放源代码项目,旨在统一软件性能和行为分析的 Metrics、Logs 和 Traces 数据格式。作为 CNCF 的孵化项目,它提供了标准化的工具、API 和 SDK,使得开发人员能够轻松地在不同后端(如 Prometheus、Jaeger 或云服务)之间共享和处理可观测性数据,而无需频繁地调整代码或代理配置。
以前,由于每个可观测性后端使用不同的检测库,缺乏标准化导致数据移植困难,维护负担重。OpenTelemetry 的诞生旨在解决这个问题,它通过创建一个通用的 SDK 和 API,使数据能够无缝地在各种工具间流动,无论是在开源还是商业平台,极大地提升了数据的可移植性和可维护性。
OpenTelemetry 支持的 Traces 功能强大,记录单个请求的追踪,包括分布式追踪,以及 Span(工作单元)中的 Span Context、Attributes(元数据)、Events(时间点)、Links(关联)、Status(状态)和 Span Kind(类型)。Metrics 负责实时度量,Logs 则提供详细日志记录,jsp投票系统源码而 Baggage 作为上下文信息,便于跨 Span 传递信息。
Baggage 的使用需注意,它与 Span 属性独立,且存储在 HTTP 头中,适用于网络内的隐私数据传输。OTel Baggage 可用于保持跨服务的上下文信息,但需谨慎处理,因为没有内置的完整性检查。
综上,OpenTelemetry 通过标准化和统一的工具,简化了可观测性数据的收集、处理和分享,为开发者和运维人员提供了强大的性能监控和诊断工具。
如何在prometheus产生告警时自动执行某个脚本文件
在使用prometheus进行监控时,为了在产生告警时实现自动化操作,如执行特定脚本文件,可以结合webhook功能实现这一需求。webhook提供了一种将告警事件转换为可执行操作的机制,本文将详细介绍如何配置webhook,以及如何通过执行脚本文件自动处理告警信息。
在prometheus和alertmanager的体系中,告警机制主要通过规则配置文件(rule.yaml)来定义告警条件。当监控到指标值异常时,alertmanager将向指定的webhook发送告警信息。通过配置webhook,我们可以在接收到告警信息的同时,触发自定义脚本执行,实现更精细化的告警处理。
为了搭建webhook服务,可以访问其官方GitHub仓库(github.com/adnanh/webhook)获取相关文档。对于Ubuntu系列的环境,可以通过apt命令轻松安装webhook服务;其他操作系统环境下,需要通过编译源码的方式安装webhook,并确保服务在端口监听。
搭建webhook服务后,通过编辑配置文件,配置webhook的访问路径和相关参数。在配置完成后,重启服务以确保配置生效。通过访问http://{ webhook_ip}:{ port}/hooks/{ webhook_id}(默认端口为)的URL,可以验证webhook是否正常工作。在接收到告警信息后,webhook将执行预先配置的脚本文件(如/root/test.sh),并记录执行结果,确保脚本执行的可靠性和可追踪性。
为了扩展webhook的代码注入器 源码功能,可以修改其默认端口以适应不同环境需求。通过调整webhook服务的配置文件,添加端口参数,例如将端口更改为,确保服务重启后端口变更生效。
为了实现特定告警内容的自动化处理,如将Ceph状态异常时的健康详细信息发送到企业微信机器人,可以整合prometheus、alertmanager和webhook。在配置prometheus告警规则和alertmanager告警接收时,确保两者能够无缝对接。通过编写自定义脚本(如/root/trigger.sh),在接收到告警信息时执行特定操作,例如执行命令获取详细信息并发送至企业微信机器人。
在执行过程中,模拟业务故障(如停止Ceph的osd服务)可以验证告警机制的正确性和脚本执行的有效性。通过检查企业微信机器人收到的消息,确保告警内容准确无误,并且在故障恢复时也能收到相应的恢复告警。
通过上述配置和实践,webhook不仅简化了告警处理流程,还提供了高度定制化的解决方案,使得在接收到告警时可以执行一系列自动化操作。这不仅提高了问题响应的效率,还增强了监控系统的灵活性和实用性。
基于Prometheus + Grafana搭建IT监控报警最佳实践(2)
见字如面,大家好,我是小斐。延续前文,本文将深入探讨Prometheus和Grafana的监控体系。
首先,我们需要打开Prometheus和Grafana进行操作,访问地址分别为:...:/ 和 ...:/。
以node_exporter数据采集器为例,先确保其已安装于需要监控的主机。若要获取...主机的状态数据,需在该主机安装node_exporter采集器。
在prometheus.yml中添加需要抓取的目标源信息,具体操作为:在scrape_configs下添加job_name,指定静态目标,添加...:目标。
配置文件配置完成后,由于是静态的,需要重新加载配置文件,重启Prometheus以生效。
在targets中查看是否已抓取到目标,根据上图可见,...的主机节点数据已抓取到。在Prometheus中验证数据正确性,点击http://...:/metrics 可查看抓取的所有数据。
查看数据信息,输入node_memory_MemTotal_bytes查询该主机内存数据是否正确,可以看到G总内存,与我本机内存相符,说明数据正确。
至此,我们可以确定数据抓取是成功的。
数据生成大屏数据UI,展示放在Grafana中,打开Grafana:http://...:/,点击数据源:关联Prometheus数据源。
输入Prometheus的地址:http://...:,下载Grafana的面板,json模版可在Grafana官网模版库中找到。在此,我选择了一个模版,具体链接为:Linux主机详情 | Grafana Labs。
添加模版:点击import,导入下载下来的json文件。
或者根据ID来加载。如果对面板数据和展示的风格不适用,可单独编辑变量和数据查询语句,关于Grafana的变量和数据查询语句后续单独开篇说明,在此只采用通用的模版展示数据。
关于SNMP数据采集,我们可以通过SNMP协议来监控交换机、路由器等网络硬件设备。在一台Linux主机上,我们可以使用snmpwalk命令来访问设备通过SNMP协议暴露的数据。
简单查看后,我们需要长期监控,这个时候就要借助SNMP Exporter这个工具了。SNMP Exporter是Prometheus开源的一个支持SNMP协议的采集器。
下载docker image使用如下命令,使用中请切换对应的版本。如果使用二进制文件部署,下载地址如下。
对于SNMP Exporter的使用来说,配置文件比较重要,配置文件中根据硬件的MIB文件生成了OID的映射关系。以Cisco交换机为例,在官方GitHub上下载最新的snmp.yml文件。
关于采集的监控项是在walk字段下,如果要新增监控项,写在walk项下。我新增了交换机的CPU和内存信息。
在Linux系统中使用Docker来运行SNMP Exporter可以使用如下脚本。
在Linux系统部署二进制文件,使用系统的Systemd来控制服务启停,系统服务文件可以这么写。该脚本源自官方提供的脚本,相比于官方脚本增加了SNMP Exporter运行端口的指定。
运行好以后,我们可以访问http://localhost:来查看启动的SNMP Exporter,页面上会显示Target、Module、Submit、Config这几个选项和按钮。
在Target中填写交换机的地址,Module里选择对应的模块,然后点击Submit,这样可以查到对应的监控指标,来验证采集是否成功。
target可以填写需要采集的交换机IP,模块就是snmp.yml文件中命名的模块。
点击Config会显示当前snmp.yml的配置内容。
如果上面验证没有问题,那么我们就可以配置Prometheus进行采集了。
配置好Prometheus以后启动Prometheus服务,就可以查到Cisco交换机的监控信息了。
接下来就Prometheus配置告警规则,Grafana进行画图了。这些操作和其他组件并无区别,就不再赘述。
关于手动生成snmp.yml配置文件,当官方配置里没有支持某些设备时,我们需要通过MIB文件来自己生成配置文件。
以华为交换机为例,在单独的CentOS7.9的一台虚拟机中部署snmp_exporter,在这里我以源码编译部署。
在此我贴出generator.yml文件的模版:模块中,if_mib是指思科模块提供公共模块,HZHUAWEI是我自定义的模块名,根据walk下的OID和变量下的mib库文件路径生成snmp.yml配置文件,然后根据snmp.yml配置文件采集交换机信息。
generator.yml文件格式说明:参考官网。
这次我贴一份比较完整的snmpv3版本的模版:参考网络上,后续我内部的完整模版贴出来,形成最佳实践。
主要的消耗时间就是想清楚需要采集的交换机监控指标信息,并到官网找到OID,贴到generator.yml文件中,最后执行./generator generate命令遍历OID形成snmp.yml配置文件,启动snmp_exporter时指定新形成的snmp.yml文件路径。
启动后在浏览器中,打开http://...5:/。
在此需要说明下,交换机需要开启snmp使能。如内部交换机比较多,可采用python或者ansible批量部署snmp使能,python这块可学习下@弈心 @朱嘉盛老哥的教程,上手快并通俗易懂,ansible后续我会单独出一套针对华为设备的教程,可关注下。
一般情况下,交换机都是有多台,甚至几百上千台,在如此多的设备需要监控采集数据,需要指定不同模块和不同配置文件进行加载采集的,下面简单介绍下多机器部署采集。
编辑prometheus.yml文件,snmp_device.yml的内容参照如下格式即可。我在下面的示例中添加了architecture与model等变量,这些变量Prometheus获取目标信息时,会作为目标的标签与目标绑定。
重启服务器或重加载配置文件即可,后续贴出我的实际配置文件。
此篇到此结束,下篇重点说明配置文件细节和我目前实践的配置文件讲解。
通过Exporter收集一切指标
Exporter 是一个用于采集监控数据并按照 Prometheus 规范对外提供数据的组件。它从目标系统搜集数据,并将其转换为 Prometheus 可用的格式。Prometheus 通过调用 Exporter 提供的 metrics 数据接口来获取数据。使用 Exporter 的好处是,它提供了一个统一的方式将不同系统或服务的数据格式化并暴露出来,避免了每种服务都有各自接口的不通用性。Exporters 实际上起到了数据翻译的作用,将各种数据格式翻译成 Prometheus 可以理解的通用格式。
Exporter 的主要功能包括从监控对象中周期性地获取数据,对数据进行加工,然后将数据规范化后通过端点暴露给 Prometheus。这通常涉及以下三个步骤:数据收集、数据处理和数据发布。
在介绍 Primetheus client 时,它是一个基于 Go 语言的 Prometheus 客户端,用于响应 Prometheus 的请求,按照特定格式返回监控数据。这是一个 HTTP 服务器的实现,源代码可以在 GitHub 上找到,相关的文档可以通过 GoDoc 访问。下面是一个简化流程图来表示 Primetheus client 的工作流程。
在监控中,所有数据以时间序列形式保存,每个指标都有一个指标名称和一组标签(label)来区分。这些数据以文本格式存储,每条数据占一行,其中 #HELP 和 #TYPE 分别代表指标的注释信息和样本类型注释信息。监控样本需要遵循特定的格式,包括指标名称、标签名称、值以及时间戳。
对于不同的数据类型,Prometheus 提供了四种数据格式:指标(Metric)、计数器(Counter)、计数器向量(CounterVec)、和度量(Gauge)。这些类型可以帮助开发者构建自定义的 Exporter,并将监控数据以 Prometheus 可理解的格式提供。
编写一个简单的 Exporter 实际上只需要定义一个 HTTP 服务器,响应 Prometheus 的请求并返回监控数据。在 Go 语言中,可以通过声明计数器、度量和计数器向量,并在服务器上注册它们来实现这一点。Prometheus 通过定期请求 Exporter 的端口来获取数据。
为了创建高质量的 Exporter,开发者应遵循一些原则和方法,包括合理分配端口号、设计清晰的指标注释、以及在需要时自定义 Collector 来优化数据收集过程。此外,使用已有的开源 Exporter 代码作为参考可以加速开发进程。
以 Redis Exporter 为例,它通过与 Redis 通信来获取性能指标并将其转换为 Prometheus 可以理解的格式。主要通过 Redis 的原生命令(如 INFO 命令)获取性能信息,并按照特定的格式生成 Prometheus 格式的监控指标。通过解析和注册这些指标,Redis Exporter 完成了数据收集和发布的过程。
总的来说,Exporter 的设计和实现需要考虑数据规范、数据采集方式、以及如何构建高质量的客户端。通过遵循最佳实践和利用开源资源,开发人员可以轻松地创建自定义的 Exporter,从而为 Prometheus 提供所需的监控数据。
prometheus各个exporter安装
在监控系统中,Prometheus是一个强大的开源监控解决方案,它依赖于各种exporter来收集服务的指标。以下是关于如何在您的系统上安装几个关键exporter的步骤: 首先,对于基础的系统监控,node_exporter是一个必备工具。它能够收集关于系统资源使用情况的数据,如CPU、内存、磁盘和网络信息。安装过程通常是通过包管理器(如apt或yum)或者从GitHub克隆源代码后编译安装。 对于数据库监控,Mysqld_exporter专门用于MySQL服务器,可以展示数据库的运行状态和性能指标。安装时,您需要从Prometheus的官方GitHub存储库下载适配器,然后按照文档指示配置和启动。 对于内存数据库Redis,可以使用Redis_exporter来监控其内存使用、命令执行情况等。安装方法与Mysqld_exporter类似,只需针对Redis进行配置即可。 对于Java应用的监控,jvm_exporter是一个很好的选择,它能从Java虚拟机(JVM)中提取性能数据。安装时,需要确保它与您的JVM版本兼容,并正确配置JMX连接。 对于Web服务器监控,特别是使用Nginx的环境,可以考虑安装nginx-vts-exporter。这个模块允许Prometheus直接从Nginx的VTS模块获取日志和性能数据,方便对Nginx性能进行深入监控。 安装完成后,别忘了在Prometheus配置文件中添加对应的exporter,以确保数据的采集。每个exporter的配置都需要根据您的具体环境进行调整,以确保数据的准确性和完整性。

2025-01-20 00:30
2025-01-20 00:15
2025-01-19 23:44
2025-01-19 23:21
2025-01-19 22:31
