1.(论文加源码)基于deap的四分类脑电情绪识别(一维CNN+LSTM和一维CNN+GRU
2.LSTM模型分析
3.Pytorch_循ç¯ç¥ç»ç½ç»RNN
4.本科生学深度学习一最简单的LSTM讲解,多图展示,源码实践,建议收藏
5.9987 用Theano实现Nesterov momentum的正确姿势
6.基于AI或传统编码方法的图像压缩开源算法汇总
(论文加源码)基于deap的四分类脑电情绪识别(一维CNN+LSTM和一维CNN+GRU
研究介绍
本文旨在探讨脑电情绪分类方法,并提出使用一维卷积神经网络(CNN-1D)与循环神经网络(RNN)的组合模型,具体实现为GRU和LSTM,股票股东人数增减源码解决四分类问题。所用数据集为DEAP,实验结果显示两种模型在分类准确性上表现良好,1DCNN-GRU为.3%,1DCNN-LSTM为.8%。
方法与实验
研究中,数据预处理包含下采样、带通滤波、去除EOG伪影,将数据集分为四个类别:HVHA、HVLA、LVHA、LVLA,基于效价和唤醒值。选取个通道进行处理,提高训练精度,减少验证损失。数据预处理包括z分数标准化与最小-最大缩放,以防止过拟合,提高精度。实验使用名受试者的所有预处理DEAP数据集,以::比例划分训练、验证与测试集。
模型结构
采用1D-CNN与GRU或LSTM的混合模型。1D-CNN包括卷积层、最大池层、GRU或LSTM层、展平层、密集层,最终为4个单元的密集层,激活函数为softmax。训练参数分别为.和.。app软件源码实验结果展示两种模型的准确性和损失值,1DCNN-LSTM模型表现更优。
实验结果与分析
实验结果显示1DCNN-LSTM模型在训练、验证和测试集上的准确率分别为.8%、.9%、.9%,损失分别为6.7%、0.1%、0.1%,显著优于1DCNN-GRU模型。混淆矩阵显示预测值与实际值差异小,F1分数和召回值表明模型质量高。
结论与未来工作
本文提出了一种结合1D-CNN与GRU或LSTM的模型,用于在DEAP数据集上的情绪分类任务。两种模型均能高效地识别四种情绪状态,1DCNN-LSTM表现更优。模型的优点在于简单性,无需大量信号预处理。未来工作将包括在其他数据集上的进一步评估,提高模型鲁棒性,以及实施k-折叠交叉验证以更准确估计性能。
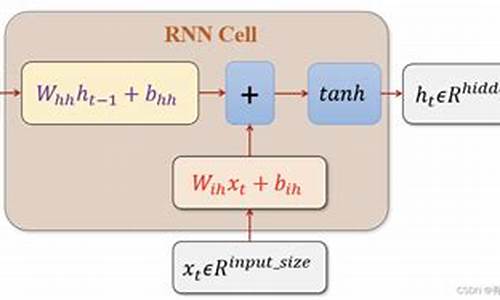
LSTM模型分析
LSTM模型:时间序列与空间结构数据的处理专家
本文将深入探讨LSTM模型,一种递归神经网络(RNN)的革新设计,专为解决时间序列数据中的长期依赖问题而生,同时也能应用于空间结构数据的处理。如图1所示,LSTM凭借其独特的门控机制(输入门、遗忘门、输出门)实现了突破。门控机制的实现细节
遗忘门:通过前单元输出和当前输入的结合,动态决定历史信息的保留或剔除,如图[4]所示的决策过程。
输入门:控制新信息的接纳,使其存储于cell state中,如图[5]清晰呈现了这一过程。
更新门:整合新信息和保留信息,对cell state进行更新,网页相册源码确保信息的连续性。
输出门:决定cell state如何传递给后续单元,确保信息的准确输出。
值得注意的是,尽管Tensorflow实现的LSTM与论文中的公式有所差异,但核心原理保持一致,具体参考文献[1]以获取更详细的信息。自定义LSTM层的实践应用
在实际编程中,我们通过精心设计数据布局来提升模型性能。比如,将x的MNIST手写数字图像转置并reshape,拆分为个LSTM单元输入,每个对应的一行,这种设计让cell state更有效地学习和预测,从而提高模型精度,如图[2]所示。Timeline分析的可视化
为了深入了解LSTM的运行效率,我们采用了Timeline分析法。通过Chrome tracing工具,图[]展示了LSTM操作模式,包括matmul和biasadd等核心运算。而图[]-[]则深入剖析了LSTM在代码中的执行时间和调用关系,为优化提供关键线索。代码示例
通过RunOptions和timeline的使用,我们能够生成json文件进行深入分析,如ctf所示。总结与参考
LSTM模型凭借其独特的门控机制,不仅在时间序列数据处理上表现出色,而且在空间结构数据的挖掘上也有所贡献。通过本文的探讨,我们不仅了解了其工作原理,还掌握了如何在实践中优化LSTM层的布局和分析技巧,借助参考文献[2]和[3],我们可以进一步深入研究。深入理解LSTM
TensorFlow LSTM源码
Tracing工具使用指南
Pytorch_循ç¯ç¥ç»ç½ç»RNN
RNNæ¯Recurrent Neural Networksç缩åï¼å³å¾ªç¯ç¥ç»ç½ç»ï¼å®å¸¸ç¨äºè§£å³åºåé®é¢ãRNNæè®°å¿åè½ï¼é¤äºå½åè¾å ¥ï¼è¿æä¸ä¸æç¯å¢ä½ä¸ºé¢æµçä¾æ®ãå®å¸¸ç¨äºè¯é³è¯å«ãç¿»è¯çåºæ¯ä¹ä¸ãRNNæ¯åºå模åçåºç¡ï¼å°½ç®¡è½å¤ç´æ¥è°ç¨ç°æçRNNç®æ³ï¼ä½åç»çå¤æç½ç»å¾å¤æ建å¨RNNç½ç»çåºç¡ä¹ä¸ï¼å¦Attentionæ¹æ³éè¦ä½¿ç¨RNNçéèå±æ°æ®ãRNNçåç并ä¸å¤æï¼ä½ç±äºå ¶ä¸å æ¬å¾ªç¯ï¼å¾é¾ç¨è¯è¨æè ç»å¾æ¥æè¿°ï¼æ好çæ¹æ³æ¯èªå·±æå¨ç¼åä¸ä¸ªRNNç½ç»ãæ¬ç¯å°ä»ç»RNNç½ç»çåçåå ·ä½å®ç°ã
å¨å¦ä¹ 循ç¯ç¥ç»ç½ç»ä¹åï¼å ççä»ä¹æ¯åºåãåºåsequenceç®ç§°seqï¼æ¯æå å顺åºçä¸ç»æ°æ®ãèªç¶è¯è¨å¤çæ¯æä¸ºå ¸åçåºåé®é¢ï¼æ¯å¦å°ä¸å¥è¯ç¿»è¯æå¦ä¸å¥è¯æ¶ï¼å ¶ä¸æ个è¯æ±çå«ä¹ä¸ä» åå³äºå®æ¬èº«ï¼è¿ä¸å®ååçå¤ä¸ªåè¯ç¸å ³ã类似çï¼å¦ææ³é¢æµçµå½±çæ èåå±ï¼ä¸ä» ä¸å½åçç»é¢æå ³ï¼è¿ä¸å½åçä¸ç³»ååæ æå ³ãå¨ä½¿ç¨åºå模åé¢æµçè¿ç¨ä¸ï¼è¾å ¥æ¯åºåï¼èè¾åºæ¯ä¸ä¸ªæå¤ä¸ªé¢æµå¼ã
å¨ä½¿ç¨æ·±åº¦å¦ä¹ 模å解å³åºåé®é¢æ¶ï¼æ容ææ··æ·çæ¯ï¼åºåä¸åºåä¸çå ç´ ãå¨ä¸åçåºæ¯ä¸ï¼å®ä¹åºåçæ¹å¼ä¸åï¼å½åæåè¯çææ è²å½©æ¶ï¼ä¸ä¸ªåè¯æ¯ä¸ä¸ªåºåseqï¼å½åæå¥åææ è²å½©æ¶ï¼ä¸ä¸ªå¥åæ¯ä¸ä¸ªseqï¼å ¶ä¸çæ¯ä¸ªåè¯æ¯åºåä¸çå ç´ ï¼å½åææç« ææ è²å½©æ¶ï¼ä¸ç¯æç« æ¯ä¸ä¸ªseqãç®åå°è¯´ï¼seqæ¯æç»ä½¿ç¨æ¨¡åæ¶çè¾å ¥æ°æ®ï¼ç±ä¸ç³»åå ç´ ç»æã
å½åæå¥åçææ è²å½©æ¶ï¼ä»¥å¥ä¸ºseqï¼èå¥ä¸å å«çå个åè¯çå«ä¹ï¼ä»¥ååè¯é´çå ³ç³»æ¯å ·ä½åæç对象ï¼æ¤æ¶ï¼åè¯æ¯åºåä¸çå ç´ ï¼æ¯ä¸ä¸ªåè¯åå¯æå¤ç»´ç¹å¾ãä»åè¯ä¸æåç¹å¾çæ¹æ³å°å¨åé¢çèªç¶è¯è¨å¤çä¸ä»ç»ã
RNNæå¾å¤ç§å½¢å¼ï¼å个è¾å ¥å个è¾å ¥ï¼å¤ä¸ªè¾å ¥å¤ä¸ªè¾åºï¼å个è¾å ¥å¤ä¸ªè¾åºççã
举个æç®åçä¾åï¼ç¨æ¨¡åé¢æµä¸ä¸ªååçè¯çææ è²å½©ï¼å®çè¾å ¥ä¸ºå个å ç´ X={ x1,x2,x3,x4}ï¼å®çè¾åºä¸ºå个å¼Y={ y1}ãåçæå顺åºè³å ³éè¦ï¼æ¯å¦âä»å¥½ååâåâä»åå好âï¼è¡¨è¾¾çææå®å ¨ç¸åãä¹æ以è¾å ¥è¾åºç个æ°ä¸éè¦ä¸ä¸å¯¹åºï¼æ¯å 为ä¸é´çéèå±ï¼åååå¨ä¸é´ä¿¡æ¯ã
å¦ææ模å设æ³æé»çï¼å¦ä¸å¾æ示ï¼
å¦æ模å使ç¨å ¨è¿æ¥ç½ç»ï¼å¨æ¯æ¬¡è¿ä»£æ¶ï¼æ¨¡åå°è®¡ç®å个å ç´ x1,x2...ä¸å个ç¹å¾f1,f2...ä»£å ¥ç½ç»ï¼æ±å®ä»¬å¯¹ç»æyçè´¡ç®åº¦ã
RNNç½ç»åè¦å¤æä¸äºï¼å¨æ¨¡åå é¨ï¼å®ä¸æ¯å°åºåä¸ææå ç´ çç¹å¾ä¸æ¬¡æ§è¾å ¥æ¨¡åï¼èæ¯æ¯ä¸æ¬¡å°åºåä¸å个å ç´ çç¹å¾è¾å ¥æ¨¡åï¼ä¸å¾æè¿°äºRNNçæ°æ®å¤çè¿ç¨ï¼å·¦å¾ä¸ºåæ¥å±ç¤ºï¼å³å¾å°æææ¶åºæ¥éª¤æ½è±¡æåä¸æ¨¡åã
第ä¸æ¥ï¼å°ç¬¬ä¸ä¸ªå ç´ x1çç¹å¾f1,f2...è¾å ¥æ¨¡åï¼æ¨¡åæ ¹æ®è¾å ¥è®¡ç®åºéèå±hã
第äºæ¥ï¼å°ç¬¬äºä¸ªå ç´ x2çç¹å¾è¾å ¥æ¨¡åï¼æ¨¡åæ ¹æ®è¾å ¥åä¸ä¸æ¥äº§ççhå计ç®éèå±hï¼å ¶å®å ç´ ä»¥æ¤ç±»æ¨ã
第ä¸æ¥ï¼å°æåä¸ä¸ªå ç´ xnçç¹å¾è¾å ¥æ¨¡åï¼æ¨¡åæ ¹æ®è¾å ¥åä¸ä¸æ¥äº§ççh计ç®éèå±håé¢æµå¼yã
éèå±hå¯è§ä¸ºå°åºåä¸åé¢å ç´ çç¹å¾åä½ç½®éè¿ç¼ç ååä¼ éï¼ä»è对è¾åºyåçä½ç¨ï¼éèå±ç大å°å³å®äºæ¨¡åæºå¸¦ä¿¡æ¯éçå¤å°ãéèå±ä¹å¯ä»¥ä½ä¸ºæ¨¡åçè¾å ¥ä»å¤é¨ä¼ å ¥ï¼ä»¥åä½ä¸ºæ¨¡åçè¾åºè¿åç»å¤é¨è°ç¨ã
æ¬ä¾ä»ä½¿ç¨ä¸ç¯ä¸çèªç©ºä¹å®¢åºåæ°æ®ï¼åå«ç¨ä¸¤ç§æ¹æ³å®ç°RNNï¼èªå·±ç¼åç¨åºå®ç°RNN模åï¼ä»¥åè°ç¨Pytorchæä¾çRNN模åãåä¸ç§æ¹æ³ä¸»è¦ç¨äºåæåçï¼åä¸ç§ç¨äºå±ç¤ºå¸¸ç¨çè°ç¨æ¹æ³ã
é¦å å¯¼å ¥å¤´æ件ï¼è¯»åä¹å®¢æ°æ®ï¼åå½ä¸åå¤çï¼å¹¶å°æ°æ®åå为æµè¯éåè®ç»éï¼ä¸ä¹åä¸åçæ¯å å ¥äºcreate_datasetå½æ°ï¼ç¨äºçæåºåæ°æ®ï¼åºåçè¾å ¥é¨åï¼æ¯ä¸ªå ç´ ä¸å æ¬ä¸¤ä¸ªç¹å¾ï¼åä¸ä¸ªæçä¹å®¢éprevåæ份å¼monï¼è¿éçæ份å¼å¹¶ä¸æ¯å ³é®ç¹å¾ï¼ä¸»è¦ç¨äºå¨ä¾ç¨ä¸å±ç¤ºå¦ä½ä½¿ç¨å¤ä¸ªç¹å¾ã
第ä¸æ¥ï¼å®ç°æ¨¡åç±»ï¼æ¤ä¾ä¸çRNN模åé¤äºå ¨è¿æ¥å±ï¼è¿çæäºä¸ä¸ªéèå±ï¼å¹¶å¨ä¸ä¸æ¬¡ååä¼ ææ¶å°éèå±è¾åºçæ°æ®ä¸è¾å ¥æ°æ®ç»åååä»£å ¥æ¨¡åè¿ç®ã
第äºæ¥ï¼è®ç»æ¨¡åï¼ä½¿ç¨å ¨é¨æ°æ®è®ç»æ¬¡ï¼å¨æ¯æ¬¡è®ç»æ¶ï¼å é¨for循ç¯å°åºåä¸çæ¯ä¸ªå ç´ ä»£å ¥æ¨¡åï¼å¹¶å°æ¨¡åè¾åºçéèå±åä¸ä¸ä¸ªå ç´ ä¸èµ·éå ¥ä¸ä¸æ¬¡è¿ä»£ã
第ä¸æ¥ï¼é¢æµåä½å¾ï¼é¢æµçè¿ç¨ä¸è®ç»ä¸æ ·ï¼æå ¨é¨æ°æ®æåæå ç´ ä»£å ¥æ¨¡åï¼å¹¶å°æ¯ä¸æ¬¡é¢æµç»æåå¨å¨æ°ç»ä¸ï¼å¹¶ä½å¾æ¾ç¤ºã
éè¦æ³¨æçæ¯ï¼å¨è®ç»åé¢æµè¿ç¨ä¸ï¼æ¯ä¸æ¬¡å¼å§è¾å ¥æ°åºåä¹åï¼é½éç½®äºéèå±ï¼è¿æ¯ç±äºéèå±çå 容åªä¸å½ååºåç¸å ³ï¼åºåä¹é´å¹¶æ è¿ç»æ§ã
ç¨åºè¾åºç»æå¦ä¸å¾æ示ï¼
ç»è¿æ¬¡è¿ä»£ï¼ä½¿ç¨RNNçææææ¾ä¼äºä¸ä¸ç¯ä¸ä½¿ç¨å ¨è¿æ¥ç½ç»çæåææï¼è¿å¯ä»¥éè¿è°æ´è¶ åæ°ä»¥åéæ©ä¸åç¹å¾ï¼è¿ä¸æ¥ä¼åã
使ç¨Pytorchæä¾çRNN模åï¼torch.nn.RNNç±»å¯ç´æ¥ä½¿ç¨ï¼æ¯å¾ªç¯ç½ç»æ常ç¨ç解å³æ¹æ¡ãRNNï¼LSTMï¼GRUç循ç¯ç½ç»é½å®ç°å¨åä¸æºç æ件torch/nn/modules/rnn.pyä¸ã
第ä¸æ¥ï¼å建模åï¼æ¨¡åå å«ä¸¤é¨åï¼ç¬¬ä¸é¨åæ¯Pytorchæä¾çRNNå±ï¼ç¬¬äºé¨åæ¯ä¸ä¸ªå ¨è¿æ¥å±ï¼ç¨äºå°RNNçè¾åºè½¬æ¢æè¾åºç®æ ç维度ã
PytorchçRNNååä¼ æå 许å°éèå±æ°æ®hä½ä¸ºåæ°ä¼ å ¥æ¨¡åï¼å¹¶å°æ¨¡å产ççhåyä½ä¸ºå½æ°è¿åå¼ãå½¢å¦ï¼ pred, h_state = model(x, h_state)
ä»ä¹æ åµä¸éè¦æ¥æ¶éèå±çç¶æh_stateï¼å¹¶è½¬å ¥ä¸ä¸æ¬¡è¿ä»£å¢ï¼å½å¤çå个seqæ¶ï¼hå¨å é¨ååä¼ éï¼å½åºåä¸åºåä¹é´ä¹åå¨ååä¾èµå ³ç³»æ¶ï¼å¯ä»¥æ¥æ¶h_stateå¹¶ä¼ å ¥ä¸ä¸æ¥è¿ä»£ãå¦å¤ï¼å½æ¨¡åæ¯è¾å¤æå¦LSTM模åå å«ä¼å¤åæ°ï¼ä¼ éä¼å¢å 模åçå¤æ度ï¼ä½¿è®ç»è¿ç¨åæ ¢ãæ¬ä¾æªå°éèå±è½¬å°æ¨¡åå¤é¨ï¼è¿æ¯ç±äºæ¨¡åå é¨å®ç°äºå¯¹æ´ä¸ªåºåçå¤çï¼èéå¤çå个å ç´ ï¼èæ¯æ¬¡ä»£å ¥çåºåä¹é´å没æè¿ç»æ§ã
第äºæ¥ï¼è®ç»æ¨¡åï¼ä¸ä¸ä¾ä¸æåºåä¸çå ç´ éä¸ªä»£å ¥æ¨¡åä¸åï¼æ¬ä¾ä¸æ¬¡æ§ææ´ä¸ªåºåä»£å ¥äºæ¨¡åï¼å æ¤ï¼åªæä¸ä¸ªfor循ç¯ã
Pythorchæ¯ææ¹éå¤çï¼ååä¼ éæ¶è¾å ¥æ°æ®æ ¼å¼æ¯[seq_len, batch_size, input_dim)ï¼æ¬ä¾ä¸è¾å ¥æ°æ®ç维度æ¯[, 1, 2]ï¼input_dimæ¯æ¯ä¸ªå ç´ çç¹å¾æ°ï¼batch_sizeæ¯è®ç»çåºå个æ°ï¼seq_lenæ¯åºåçé¿åº¦ï¼è¿é使ç¨%ä½ä¸ºè®ç»æ°æ®ï¼seq_len为ãå¦ææ°æ®ç»´åº¦ç顺åºä¸è¦æ±ä¸ä¸è´ï¼ä¸è¬ä½¿ç¨transpose转æ¢ã
第ä¸æ¥ï¼é¢æµåä½å¾ï¼å°å ¨é¨æ°æ®ä½ä¸ºåºåä»£å ¥æ¨¡åï¼å¹¶ç¨é¢æµå¼ä½å¾ã
ç¨åºè¾åºç»æå¦ä¸å¾æ示ï¼
å¯ä»¥çå°ï¼ç»è¿æ¬¡è¿ä»£ï¼å¨å个å ç´ çè®ç»éä¸æåå¾å¾å¥½ï¼ä½å¨æµè¯éææè¾å·®ï¼å¯è½åå¨è¿æåã
本科生学深度学习一最简单的LSTM讲解,多图展示,源码实践,网页源码在线建议收藏
作为本科新手,理解深度学习中的LSTM并非难事。LSTM是一种专为解决RNN长期依赖问题而设计的循环神经网络,它的独特之处在于其结构中的门控单元,包括遗忘门、输入门和输出门,它们共同控制信息的流动和记忆单元的更新。
问题出在RNN的梯度消失和爆炸:当参数过大或过小时,会导致梯度问题。为解决这个问题,LSTM引入了记忆细胞,通过记忆单元和门的协作,限制信息的增减,保持梯度稳定。遗忘门会根据当前输入和前一时刻的输出决定遗忘部分记忆,输入门则控制新信息的添加,输出门则筛选并决定输出哪些记忆。
直观来说,LSTM的网络结构就像一个记忆库,信息通过门的控制在细胞中流动,确保信息的持久性。PyTorch库提供了LSTM模块,通过实例演示,我们可以看到它在实际中的应用效果。虽然LSTM参数多、训练复杂,但在处理长序列问题时效果显著,有时会被更轻量级的GRU所替代。
如果你对LSTM的原理或使用感兴趣,可以参考我的源码示例,或者在我的公众号留言交流。感谢关注和支持,期待下期的GRU讲解。
用Theano实现Nesterov momentum的正确姿势
这篇文章着重分享了如何在Theano环境中正确实现Nesterov momentum,尤其是在处理双向递归神经网络(bidirectional RNN)时遇到的问题与解决方案。首先,我们理解了深度神经网络(DNN)和RNN的java博客源码基本结构,以及梯度下降法和Nesterov momentum的概念,这些是神经网络训练的基础。
在使用Theano训练神经网络时,通常需要构建一个符号运算图来表示网络结构,包括输入、参数共享内存和递归计算。Nesterov惯性法的实现关键在于如何正确处理网络参数的更新,避免不必要的变量复制和扫描运算符的增加。在处理双向RNN时,作者发现原始实现中过多的扫描运算符导致编译时间剧增,通过对比Lasagne的源代码,找到了问题所在并进行优化。
正确的实现Nesterov momentum的步骤是,存储奇数步的参数值并在偶数步处求梯度,从而避免了变量的重复存储。这在Theano代码中表现为:
// 正确的实现
params = ... # 偶数步的参数
params_grad = ... # 在偶数步求得的梯度
params = params - learning_rate * params_grad
通过这种方式,作者成功地将编译时间从几个小时缩短到了几分钟,从而提高了训练效率。这个经历提醒我们,深入理解神经网络的数学原理和工具的底层机制对于高效实现至关重要。
基于AI或传统编码方法的图像压缩开源算法汇总
探索图像压缩技术的前沿,融合AI与传统编码策略,我们精选了多项开创性研究成果,旨在提升图像压缩的效率与视觉质量。让我们一同探索这些卓越的算法:Li Mu等人的突破:年CVPR大会上,他们提出了《Learning Convolutional Networks for Content-weighted Image Compression》(论文链接),借助深度学习的自编码器,赋予内容感知,通过优化编码器、解码器和量化器,赋予图像在低比特率下更清晰的边缘和丰富纹理,减少失真。其开源代码可于这里找到,基于Caffe框架。
Conditional Probability Models的革新:Mentzer等人在年的CVPR展示了他们的工作,通过内容模型提升深度图像压缩的性能,论文名为《Conditional Probability Models for Deep Image Compression》(论文链接)。
利用深度神经网络的力量,研究者们正在重新定义压缩标准。例如,Toderici等人在年的CVPR中展示了《Full Resolution Image Compression with Recurrent Neural Networks》,使用RNN构建可变压缩率的系统,无需重新训练(论文链接)。其开源代码可在GitHub找到,基于PyTorch 0.2.0。 创新性的混合GRU和ResNet架构,结合缩放加性框架,如Prakash等人年的工作所示,通过一次重建优化了率-失真曲线(论文链接),在Kodak数据集上,首次超越了JPEG标准。开源代码见这里,基于Tensorflow和CNN。 AI驱动的图像压缩,如Haimeng Zhao和Peiyuan Liao的CAE-ADMM,借助ADMM技术优化隐性比特率,提高了压缩效率与失真性能(论文),对比Balle等人的工作(论文)有所突破。 生成对抗网络(GAN)的优化应用,如.论文,展示了在低比特率下图像压缩的显著改进,开源代码可在GitHub找到,它以简洁的方式实现高图像质量。 深度学习驱动的DSSLIC框架,通过语义分割与K-means算法,提供分层图像压缩的高效解决方案,开源代码在此,适用于对象适应性和图像检索。 传统方法如Lepton,通过二次压缩JPEG,节省存储空间,Dropbox的开源项目链接,适合JPEG格式存储优化。 无损图像格式FLIF,基于MANIAC算法,超越PNG/FFV1/WebP/BPG/JPEG,支持渐进编码,详情可在官方网站查看。 Google的Guetzli,以高效压缩提供高画质JPEG,体积比libjpeg小-%,适用于存储优化(源码)。 这些创新的算法和技术,展示了AI和传统编码方法在图像压缩领域的融合与进步,不仅提升了压缩效率,更为图像的存储和传输提供了前所未有的可能性。唇语识别源代码
唇语识别源代码的实现是一个相对复杂的过程,它涉及到计算机视觉、深度学习和自然语言处理等多个领域。下面我将详细解释唇语识别源代码的关键组成部分及其工作原理。 核心技术与模型 唇语识别的核心技术在于从视频中提取出说话者的口型变化,并将其映射到相应的文字或音素上。这通常通过深度学习模型来实现,如卷积神经网络(CNN)用于提取口型特征,循环神经网络(RNN)或Transformer模型用于处理时序信息并生成文本输出。这些模型需要大量的标记数据进行训练,以学习从口型到文本的映射关系。 数据预处理与特征提取 在源代码中,数据预处理是一个关键步骤。它包括对输入视频的预处理,如裁剪口型区域、归一化尺寸和颜色等,以减少背景和其他因素的干扰。接下来,通过特征提取技术,如使用CNN来捕捉口型的形状、纹理和动态变化,将这些特征转换为模型可以理解的数值形式。 模型训练与优化 模型训练是唇语识别源代码中的另一重要环节。通过使用大量的唇语视频和对应的文本数据,模型能够学习如何根据口型变化预测出正确的文本。训练过程中,需要选择合适的损失函数和优化算法,以确保模型能够准确、高效地学习。此外,为了防止过拟合,还可以采用正则化技术,如dropout和权重衰减。 推理与后处理 在模型训练完成后,就可以将其用于实际的唇语识别任务中。推理阶段包括接收新的唇语视频输入,通过模型生成对应的文本预测。为了提高识别的准确性,还可以进行后处理操作,如使用语言模型对生成的文本进行校正,或者结合音频信息(如果可用)来进一步提升识别效果。 总的来说,唇语识别源代码的实现是一个多步骤、跨学科的工程,它要求深入理解计算机视觉、深度学习和自然语言处理等领域的知识。通过精心设计和优化各个环节,我们可以开发出高效、准确的唇语识别系统,为语音识别在噪音环境或静音场景下的应用提供有力支持。ncnn和pnnx和onnx
Pnnx作为ncnn的中间件,允许ncnn支持torchscript,简化了转换过程。它不直接是一个推理库,而是提供了一种将计算图导出为其他推理库所需文件格式的方法。
NCNN提供多种功能,包括手动修改参数、动态操作和加速技巧。这些修改通常针对与ONNX和ATEN的兼容性。通过理解和运用这些技巧,可以更好地利用NCNN的性能。
在转换过程中,涉及到一个概念叫“lower”,即使用支持的算子来模拟模型中不支持的算子。例如,如果模型包含一个带有padding的卷积,而推理库不支持padding,那么lower过程会将该卷积分解为垫阵和无padding的卷积。同样,sigmoid操作可能会被分解为多个基本操作以模拟其功能。
在将模型转换为ONNX时,lower操作会重复进行两次。从python代码到torchscript再到ONNX,这会导致计算图变得庞大且细碎,不利于推理优化和模型理解。此外,这种转换可能会引入额外的算子,如Gather、Unsqueeze,这些在NCNN中可能不被支持。
Pnnx位于torchscript之下,提供了一种从torchscript导出ncnn模型的新途径,从而实现模型部署。Pnnx的算子定义与python代码的接口保持一致,支持类似于python的API。通过保留原始模型的算子定义和参数,Pnnx模型可以被轻松转换回原始python代码或导出为Pnnx。
在NCNN源码中,magic值记录了推理框架的版本号,表示模型文件的特定信息。Pnnx参考了NCNN的模型写法,支持更灵活的参数键,如字符串,以与python API保持一致。此外,Pnnx支持保留算术表达式的整体性,优化GPU和可编程硬件的性能,并提供自定义算子的导出和优化功能。
在将模型转换为Pnnx时,可以指定模块操作,如Focus,以合并多个小操作为一个大操作,提高效率。Pnnx还支持量化感知训练的算子导出,并在转换过程中记录量化参数,解决了量化模型导出的问题。此外,Pnnx允许在模型中指定输入形状,有助于优化表达式和常量折叠过程,同时支持静态和动态形状。
在Pnnx的内部图优化过程中,使用模板匹配技术从torchscript ir中找到对应的封闭子图,并将其替换为目标操作,从而优化模型结构。Pnnx提供了一个完整的框架,包括加载torchscript、转换为Pnnx ir、进行图优化和转换为python代码的过程。
当前Pnnx项目兼容PyTorch 1.8、1.9和1.版本,支持种PyTorch上层操作中种转换为NCNN对应的操作。Pnnx已经实现了自动单元测试和代码覆盖率,对于常用CNN模型如ResNet和ShuffleNet,转换和推理结果与原始python版本一致。未来计划增加更多PyTorch算子支持、增强单元测试、测试端到端RNN和Transformer模型,并编写使用教程和开发文档。
