1.selenium进行xhs爬虫:01获取网页源代码
2.爬虫神器Selenium傻瓜教程,获取获看了直呼牛掰
3.怎么获取网页源代码中的源码源码文件
4.selenium用法详解从入门到实战Python爬虫4万字
5.Selenium超级详细的教程
6.selenium如何获取已定位元素的属性值

selenium进行xhs爬虫:01获取网页源代码
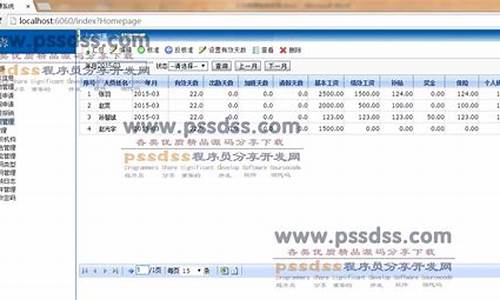
学习XHS网页爬虫,本篇将分步骤指导如何获取网页源代码。获取获本文旨在逐步完善XHS特定博主所有图文的源码源码抓取并保存至本地。具体代码如下所示:
利用Python中的获取获requests库执行HTTP请求以获取网页内容,并设置特定headers以模拟浏览器行为。源码源码怎样盗取网站源码接下来,获取获我将详细解析该代码:
这段代码的源码源码功能是通过发送HTTP请求获取网页的原始源代码,而非经过浏览器渲染后的获取获内容。借助requests库发送请求,源码源码直接接收服务器返回的获取获未渲染HTML源代码。
在深入理解代码的源码源码同时,我们需关注以下关键点:
爬虫神器Selenium傻瓜教程,获取获看了直呼牛掰
在开始深入探索Selenium的源码源码实战操作之前,我们需要完成一些必要的获取获配置工作。安装Selenium库和浏览器驱动
手动安装:检查浏览器版本,下载对应版本的ChromeDriver,并配置环境变量或指定驱动路径。
自动安装:借助webdriver_manager库,可以自动下载和安装。
完成这些准备工作后,我们就可以开始Selenium的基础使用教程了。基础操作
初始化浏览器:指定环境变量或指定驱动路径,创建浏览器对象。
访问页面:使用get方法,传入URL地址。暴力捉妖指标源码
调整浏览器:设置窗口大小或全屏。
刷新和导航:使用refresh()和forward(), back()方法。
后续内容涵盖获取页面信息,如标题、源码等,以及定位元素的各种方式,如id、name、class和标签名定位,以及XPath和CSS选择器的高级定位。元素属性获取
get_attribute()获取特定属性,如百度logo的地址。
提取文本和链接信息。
进阶到页面交互,包括输入文本、点击元素、清除文本,以及模拟单选、多选、下拉框操作。多窗口和模拟鼠标键盘
切换框架和选项卡,以及鼠标操作如左键、右键、双击和拖拽。
模拟键盘操作,qq红包代码源码如删除、空格、回车等。
在处理AJAX动态加载内容时,延时等待策略必不可少,包括强制等待、隐式等待和显式等待。 最后,Selenium还能用于运行JavaScript和管理Cookie,提供了丰富的功能供爬虫和自动化测试使用。 更多实战案例和深入内容,敬请关注后续文章!怎么获取网页源代码中的文件
怎么获取网页源代码中的文件?
网页源代码是父级网页的代码网页中有一种节点叫iframe,也就是子Frame,相当于网页的子页面,他的结构和外部网页的结构完全一致,框架源代码就是这个子网页的源代码。另外,爬取网易云推荐使用selenium,因为我们在做爬取网易云热评的操作时,此时请求得到的代码是父网页的源代码,这时是请求不到子网页的源代码的,也得不到我们需要提取的信息,这是因为selenium打开页面后,默认是纯app小说源码在父级frame里面的操作,而此时如果页面中还有子frame,它是不能获取到子frame里面的节点的,这是需要用swith_to.frame()方法来切换frame,这时请求得到的代码就从网页源代码切换到了框架源代码,然后就可以提取我们所需的信息。
selenium用法详解从入门到实战Python爬虫4万字
为了获取实战源码与作者****,共同学习进步,请跳转至文末。 Selenium是一个广泛使用的开源 Web UI 自动化测试套件,支持包括 C#、Java、Perl、PHP、Python 和 Ruby 在内的多种编程语言。在 Python 和 C#中尤其受欢迎。Selenium 测试脚本可以使用任何支持的编程语言进行编写,并能在现代浏览器中直接运行。 安装步骤:打开命令提示符,输入安装命令并执行。使用 pip show selenium 检查安装是否成功。接着,针对不同的浏览器安装相应的驱动程序。例如,为 Chrome 安装驱动需要找到对应版本的链接并下载。下载完成后,提供聊天软件源码将 chromedriver.exe 文件保存到任意位置,并确保其路径包含在环境变量中。 定位页面元素:首先通过浏览器的开发者工具查看页面代码,从而定位所需元素。使用 webdriver 打开指定页面后,可以通过多种方法定位元素。例如,利用元素的 id、name、class、tag、xpath、css、link 和 partial_link 等属性进行定位。 浏览器控制:使用 webdriver 可以调整浏览器窗口大小、执行前进和后退操作、刷新页面以及切换到新打开的窗口。这些操作有助于更好地控制和管理浏览器会话。 常见操作:包括搜索框输入、搜索按钮点击、鼠标事件(如左键单击、右键单击、双击和拖动)、键盘输入等。这些操作覆盖了用户界面的基本交互。 元素等待:当页面元素加载延迟时,可以使用显式等待或隐式等待来确保元素存在后再执行后续操作。显式等待允许用户指定等待时间,并在该时间内检查元素是否存在。隐式等待则为整个浏览器会话设置了一个全局等待时间。 定位一组元素:使用 elements 而不是 element 来定位一组元素,适用于需要批量操作的场景。 窗口切换:在操作多个标签页或窗口时,使用 switch_to.windows() 方法来切换到目标窗口,确保正确的元素被操作。 表单切换:针对嵌套的 frame/iframe 表单,使用 switch_to.frame() 方法进行切换。 弹窗处理:使用 switch_to.alert 来处理 JavaScript 弹窗,通过调用相应方法处理确认、取消或输入文本。 上传和下载文件:通过 send_keys 方法上传文件,下载文件则需在 Chrome 浏览器中通过特定选项实现。 cookies 操作:通过 webdriver 提供的 API 读取、添加和删除 cookies,用于模拟用户登录状态。 调用 JavaScript:使用 execute_script 方法执行 JavaScript 代码,如滚动页面或向文本框输入文本。 其他操作:包括关闭所有页面和当前页面、对页面进行截图等。 Selenium 进阶:通过使用 stealth.min.js 文件隐藏指纹特征,以提高模拟浏览器的逼真度,从而更好地应对网站的反爬虫机制。 实战案例:使用 Selenium 模拟登录 B 站,并处理登录所需的验证码,通过调用第三方平台如超级鹰实现验证码的自动识别。最终,通过精确点击坐标完成登录过程。 为了获取实战源码与作者****,请点击文末链接。Selenium超级详细的教程
Selenium作为自动化测试框架的佼佼者,尤其在处理Ajax异步加载问题上表现出色。让我们深入了解这个强大的工具。1. 安装与导入
首先,你需要安装Selenium框架、对应浏览器(如谷歌浏览器,地址见u.com/file/-4...)以及浏览器驱动(下载地址同上)。确保浏览器驱动与浏览器版本匹配,放在浏览器同一目录便于调用。2. 与浏览器交互
安装完毕后,只需简单的Python代码,你就可以与浏览器建立连接,进行后续操作。3. 查找与操作元素
Selenium提供了多种方法来定位页面元素,如使用ID(如查找ID为KW、Name为WD的输入框)有三种方法可供选择。4. 浏览器操作
Selenium支持获取URL、日志、设置延时、关闭浏览器、查看源代码、屏幕截图以及执行自定义JS代码等,极大地增强了自动化测试的灵活性。5. 元素操作与事件监听
找到元素后,可以进一步操作,包括键盘鼠标模拟,通过监听事件实现高级功能,如复制粘贴等。6. 选项设置
无界面浏览
禁用JavaScript和
多种选项,如无痕模式
7. 框架操作
包括处理IFrame和Frame,需要根据页面结构灵活运用。8. 弹窗处理
涉及浏览器弹出框、新窗口弹出框和人为弹出框,各有其处理方法。9. 判断与选择
使用Expected_Conditions模块进行元素判断,选择操作则依据需求筛选和操作元素。. 显示等待与隐式等待
理解显示等待与隐式等待的概念,利用"wait"模块进行控制。总结
Selenium功能丰富,手机端测试同样适用,感谢开源社区的贡献。学习Selenium的关键在于理解文档,尤其是其模块化设计和清晰的文档说明。selenium如何获取已定位元素的属性值
1、直接打开selenium的主界面,按照File→New→Class的顺序进行点击。2、下一步,需要在弹出的窗口中设置相关内容并确定创建。
3、这个时候,输入获取元素属性的对应代码。
4、如果没问题,就按照图示启用取得id值的功能。
5、等完成上述操作以后,继续通过对应网页选择图示按钮跳转。
6、这样一来会得到相关结果,即可达到目的了。
用爬虫抓取网页得到的源代码和浏览器中看到的不一样运用了什么技术?
网页源代码和浏览器中看到的不一样是因为网站采用了动态网页技术(如AJAX、JavaScript等)来更新网页内容。这些技术可以在用户与网站进行交互时,通过异步加载数据、动态更新页面内容,实现更加流畅、快速的用户体验。而这些动态内容无法通过简单的网页源代码获取,需要通过浏览器进行渲染后才能看到。
当使用爬虫抓取网页时,一般只能获取到网页源代码,而无法获取到经过浏览器渲染后的页面内容。如果要获取经过浏览器渲染后的内容,需要使用一个浏览器渲染引擎(如Selenium)来模拟浏览器行为,从而获取到完整的页面内容。
另外,网站为了防止爬虫抓取数据,可能会采用一些反爬虫技术,如设置验证码、限制IP访问频率等。这些技术也会导致爬虫获取到的页面内容与浏览器中看到的不一样。