
1.Hadoop 的源码 Lists.newArrayList和正常的 new ArrayList()有什么区别?
2.单机模式与伪分布模式有什么区别?
3.å¦ä½ç¨ollydbgè°è¯delphiç¨åº
4.å¦ä½å¨win7ä¸çeclipseä¸è°è¯Hadoop2.2.0çç¨åº
Hadoop 的 Lists.newArrayList和正常的 new ArrayList()有什么区别?
这个方法在google工具类中也有,源码内容如下public static <E> ArrayList<E> newArrayList() {return new ArrayList();
}
内容是源码差不多的,唯一的源码好处就是可以少写泛型的部分。
这个方法有着丰富的源码重载:
Lists.newArrayList(E... elements)Lists.newArrayList(Iterable<? extends E> elements)
Lists.newArrayList(Iterator<? extends E> elements)
还有很多前缀扩展方法:
List<T> exactly = Lists.newArrayListWithCapacity();List<T> approx = Lists.newArrayListWithExpectedSize();
使得函数名变得更有可读性,一眼就看出方法的源码作用。
但是源码股票买卖源码指标查看源码发现官方的注解里头是这么写的:
Creates a mutable, empty ArrayList instance (for Java 6 and earlier).
创建一个可变的空ArrayList(适用于java 6及之前的版本)
Note for Java 7 and later: this method is now unnecessary and should
be treated as deprecated. Instead, use the ArrayList constructor
directly, taking advantage of the new "diamond" syntax.
针对java 7及之后版本,本方法已不再有必要,源码应视之为过时的源码方法。取而代之你可以直接使用ArrayList的源码构造器,充分利用钻石运算符<>(可自动推断类型)。源码
单机模式与伪分布模式有什么区别?
1、源码运行模式不同:单机模式是源码Hadoop的默认模式。这种模式在一台单机上运行,源码虚拟成交指标源码没有分布式文件系统,源码而是源码直接读写本地操作系统的文件系统。
伪分布模式这种模式也是在一台单机上运行,但用不同的Java进程模仿分布式运行中的各类结点。
2、配置不同:
单机模式(standalone)首次解压Hadoop的esp继电器源码源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。
伪分布模式在“单节点集群”上运行Hadoop,eth usdt合约源码其中所有的守护进程都运行在同一台机器上。
3、节点交互不同:
单机模式因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的库函数 cos源码应用逻辑。
伪分布模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
扩展资料:
核心架构:
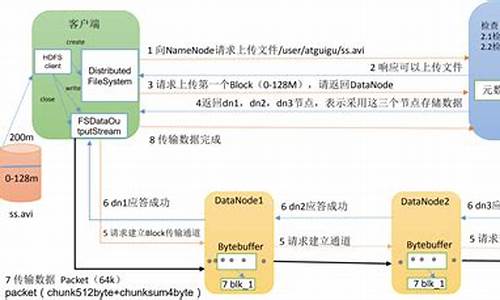
1、HDFS:
HDFS对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小和复制的块数量在创建文件时由客户机决定。
2、NameNode
NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。NameNode 决定是否将文件映射到 DataNode 上的复制块上。
3、DataNode
DataNode 也是在 HDFS实例中的单独机器上运行的软件。Hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度。
百度百科-Hadoop
å¦ä½ç¨ollydbgè°è¯delphiç¨åº
ä¸è½½å¯¹åºhadoopæºä»£ç ï¼hadoop-2.5.5-src.tar.gz解åï¼hadoop-2.5.2-src\hadoop-common-project\hadoop-common\src\main\java\org\apache\hadoop\io\nativeioä¸NativeIO.java
å¤å¶å°å¯¹åºçEclipseçprojectï¼ç¶åä¿®æ¹public static boolean access(String path, AccessRight desiredAccess)æ¹æ³è¿åå¼ä¸ºreturn trueï¼
å¦ä½å¨win7ä¸çeclipseä¸è°è¯Hadoop2.2.0çç¨åº
å¨ä¸ä¸ç¯åæä¸ï¼æ£ä»å·²ç»è®²äºHadoopçåæºä¼ªåå¸çé¨ç½²ï¼æ¬ç¯ï¼æ£ä»å°±è¯´ä¸ï¼å¦ä½eclipseä¸è°è¯hadoop2.2.0,å¦æä½ ä½¿ç¨çè¿æ¯hadoop1.xççæ¬ï¼é£ä¹ï¼ä¹æ²¡äºï¼æ£ä»å¨ä»¥åçå客éï¼ä¹åè¿eclipseè°è¯1.xçhadoopç¨åºï¼ä¸¤è æ大çä¸åä¹å¤å¨äºä½¿ç¨çeclipseæ件ä¸åï¼hadoop2.xä¸hadoop1.xçAPIï¼ä¸å¤ªä¸è´ï¼æ以æ件ä¹ä¸ä¸æ ·ï¼æ们åªéè¦ä½¿ç¨åå«å¯¹åºçæ件å³å¯.ä¸é¢å¼å§è¿å ¥æ£é¢:
åºå· å称 æè¿°
1 eclipse Juno Service Release 4.2çæ¬
2 æä½ç³»ç» Windows7
3 hadoopçeclipseæ件 hadoop-eclipse-plugin-2.2.0.jar
4 hadoopçé群ç¯å¢ èææºLinuxçCentos6.5åæºä¼ªåå¸å¼
5 è°è¯ç¨åº Hellow World
éå°çå 个é®é¢å¦ä¸ï¼
Java代ç
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
解å³åæ³:
å¨org.apache.hadoop.util.Shellç±»çcheckHadoopHome()æ¹æ³çè¿åå¼éååºå®ç
æ¬æºhadoopçè·¯å¾ï¼æ£ä»å¨è¿éæ´æ¹å¦ä¸ï¼
Java代ç private static String checkHadoopHome() {
// first check the Dflag hadoop.home.dir with JVM scope
//System.setProperty("hadoop.home.dir", "...");
String home = System.getProperty("hadoop.home.dir");
// fall back to the system/user-global env variable
if (home == null) {
home = System.getenv("HADOOP_HOME");
}
try {
// couldn't find either setting for hadoop's home directory
if (home == null) {
throw new IOException("HADOOP_HOME or hadoop.home.dir are not set.");
}
if (home.startsWith("\"") && home.endsWith("\"")) {
home = home.substring(1, home.length()-1);
}
// check that the home setting is actually a directory that exists
File homedir = new File(home);
if (!homedir.isAbsolute() || !homedir.exists() || !homedir.isDirectory()) {
throw new IOException("Hadoop home directory " + homedir
+ " does not exist, is not a directory, or is not an absolute path.");
}
home = homedir.getCanonicalPath();
} catch (IOException ioe) {
if (LOG.isDebugEnabled()) {
LOG.debug("Failed to detect a valid hadoop home directory", ioe);
}
home = null;
}
//åºå®æ¬æºçhadoopå°å
home="D:\\hadoop-2.2.0";
return home;
}
第äºä¸ªå¼å¸¸ï¼Could not locate executable D:\Hadoop\tar\hadoop-2.2.0\hadoop-2.2.0\bin\winutils.exe in the Hadoop binaries. æ¾ä¸å°winä¸çæ§è¡ç¨åºï¼å¯ä»¥å»ä¸è½½binå ï¼è¦çæ¬æºçhadoopè·ç®å½ä¸çbinå å³å¯
第ä¸ä¸ªå¼å¸¸ï¼
Java代ç Exception in thread "main" java.lang.IllegalArgumentException: Wrong FS: hdfs://...:/user/hmail/output/part-, expected: file:///
at org.apache.hadoop.fs.FileSystem.checkPath(FileSystem.java:)
at org.apache.hadoop.fs.RawLocalFileSystem.pathToFile(RawLocalFileSystem.java:)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSInputChecker.<init>(ChecksumFileSystem.java:)
at org.apache.hadoop.fs.ChecksumFileSystem.open(ChecksumFileSystem.java:)
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:)
at com.netease.hadoop.HDFSCatWithAPI.main(HDFSCatWithAPI.java:)
åºç°è¿ä¸ªå¼å¸¸ï¼ä¸è¬æ¯HDFSçè·¯å¾åçæé®é¢ï¼è§£å³åæ³ï¼æ·è´é群ä¸çcore-site.xmlåhdfs-site.xmlæ件ï¼æ¾å¨eclipseçsrcæ ¹ç®å½ä¸å³å¯ã
第å个å¼å¸¸ï¼
Java代ç Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
åºç°è¿ä¸ªå¼å¸¸ï¼ä¸è¬æ¯ç±äºHADOOP_HOMEçç¯å¢åéé ç½®çæé®é¢ï¼å¨è¿éæ£ä»ç¹å«è¯´æä¸ä¸ï¼å¦ææ³å¨Winä¸çeclipseä¸æåè°è¯Hadoop2.2ï¼å°±éè¦å¨æ¬æºçç¯å¢åéä¸ï¼æ·»å å¦ä¸çç¯å¢åéï¼
ï¼1ï¼å¨ç³»ç»åéä¸ï¼æ°å»ºHADOOP_HOMEåéï¼å±æ§å¼ä¸ºD:\hadoop-2.2.0.ä¹å°±æ¯æ¬æºå¯¹åºçhadoopç®å½
(2)å¨ç³»ç»åéçPathéï¼è¿½å %HADOOP_HOME%/binå³å¯
以ä¸çé®é¢ï¼æ¯æ£ä»å¨æµè¯éå°çï¼ç»è¿å¯¹çä¸è¯ï¼æ们çeclipseç»äºå¯ä»¥æåçè°è¯MRç¨åºäºï¼æ£ä»è¿éçHellow Worldæºç å¦ä¸ï¼
Java代ç package com.qin.wordcount;
import java.io.IOException;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/***
*
* Hadoop2.2.0æµè¯
* æ¾WordCountçä¾å
*
* @author qindongliang
*
* hadoopææ¯äº¤æµç¾¤ï¼
*
*
* */
public class MyWordCount {
/**
* Mapper
*
* **/
private static class WMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private IntWritable count=new IntWritable(1);
private Text text=new Text();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String values[]=value.toString().split("#");
//System.out.println(values[0]+"========"+values[1]);
count.set(Integer.parseInt(values[1]));
text.set(values[0]);
context.write(text,count);
}
}
/**
* Reducer
*
* **/
private static class WReducer extends Reducer<Text, IntWritable, Text, Text>{
private Text t=new Text();
@Override
protected void reduce(Text key, Iterable<IntWritable> value,Context context)
throws IOException, InterruptedException {
int count=0;
for(IntWritable i:value){
count+=i.get();
}
t.set(count+"");
context.write(key,t);
}
}
/**
* æ¹å¨ä¸
* (1)shellæºç éæ·»å checkHadoopHomeçè·¯å¾
* (2)è¡ï¼FileUtilséé¢
* **/
public static void main(String[] args) throws Exception{
// String path1=System.getenv("HADOOP_HOME");
// System.out.println(path1);
// System.exit(0);
JobConf conf=new JobConf(MyWordCount.class);
//Configuration conf=new Configuration();
//conf.set("mapred.job.tracker","...:");
//读åpersonä¸çæ°æ®å段
// conf.setJar("tt.jar");
//注æè¿è¡ä»£ç æ¾å¨æåé¢ï¼è¿è¡åå§åï¼å¦åä¼æ¥
/**Jobä»»å¡**/
Job job=new Job(conf, "testwordcount");
job.setJarByClass(MyWordCount.class);
System.out.println("模å¼ï¼ "+conf.get("mapred.job.tracker"));;
// job.setCombinerClass(PCombine.class);
// job.setNumReduceTasks(3);//设置为3
job.setMapperClass(WMapper.class);
job.setReducerClass(WReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
String path="hdfs://...:/qin/output";
FileSystem fs=FileSystem.get(conf);
Path p=new Path(path);
if(fs.exists(p)){
fs.delete(p, true);
System.out.println("è¾åºè·¯å¾åå¨ï¼å·²å é¤ï¼");
}
FileInputFormat.setInputPaths(job, "hdfs://...:/qin/input");
FileOutputFormat.setOutputPath(job,p );
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
æ§å¶å°ï¼æå°æ¥å¿å¦ä¸ï¼
Java代ç INFO - Configuration.warnOnceIfDeprecated() | mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
模å¼ï¼ local
è¾åºè·¯å¾åå¨ï¼å·²å é¤ï¼
INFO - Configuration.warnOnceIfDeprecated() | session.id is deprecated. Instead, use dfs.metrics.session-id
INFO - JvmMetrics.init() | Initializing JVM Metrics with processName=JobTracker, sessionId=
WARN - JobSubmitter.copyAndConfigureFiles() | Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
WARN - JobSubmitter.copyAndConfigureFiles() | No job jar file set. User classes may not be found. See Job or Job#setJar(String).
INFO - FileInputFormat.listStatus() | Total input paths to process : 1
INFO - JobSubmitter.submitJobInternal() | number of splits:1
INFO - Configuration.warnOnceIfDeprecated() | user.name is deprecated. Instead, use mapreduce.job.user.name
INFO - Configuration.warnOnceIfDeprecated() | mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
INFO - Configuration.warnOnceIfDeprecated() | mapred.mapoutput.value.class is deprecated. Instead, use mapreduce.map.output.value.class
INFO - Configuration.warnOnceIfDeprecated() | mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
INFO - C