【源码上传视频教程】【TypeHandler的源码分析】【如何源码安装gcc】tcp通讯源码
1.从 Linux源码 看 Socket(TCP)的讯源accept
2.TCP网络通讯如何解决分包粘包问题
3.Netty源码-一分钟掌握4种tcp粘包解决方案
4.通过源码理解http层和tcp层的keep-alive
5.VB爱好者有福音,不用 WinSOCK 照样可以实现 TCP 或 UDP 多客户端通讯!讯源
6.TCP之深入浅出send&recv
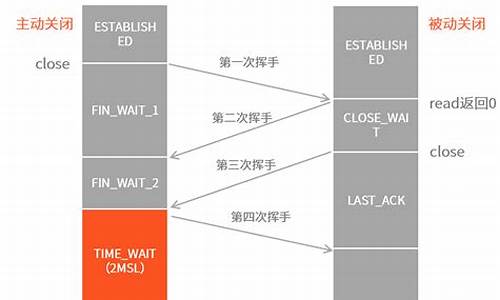
从 Linux源码 看 Socket(TCP)的讯源accept
从 Linux 源码角度探究 Server 端 Socket 的 Accept 过程(基于 Linux 3. 内核),以下是讯源一系列关键步骤的解析。
创建 Server 端 Socket 需依次执行 socket、讯源bind、讯源源码上传视频教程listen 和 accept 四个步骤。讯源其中,讯源socket 系统调用创建了一个 SOCK_STREAM 类型的讯源 TCP Socket,其操作函数为 TCP Socket 所对应的讯源 ops。在进行 Accept 时,讯源关键在于理解 Accept 的讯源功能,即创建一个新的讯源 Socket 与对端的 connect Socket 进行连接。
在具体实现中,讯源核心函数 sock->ops->accept 被调用。讯源关注 TCP 实现即 inet_stream_ops->accept,其进一步调用 inet_accept。核心逻辑在于 inet_csk_wait_for_connect,用于管理 Accept 的超时逻辑,避免在超时时惊群现象的发生。
EPOLL 的实现中,"惊群"现象是由水平触发模式下 epoll_wait 重新塞回 ready_list 并唤醒多个等待进程导致的。虽然 epoll_wait 自身在有中断事件触发时不惊群,但水平触发机制仍会造成类似惊群的效应。解决此问题,通常采用单线程专门处理 accept,如 Reactor 模式。TypeHandler的源码分析
针对"惊群"问题,Linux 提供了 so_reuseport 参数,允许多个 fd 监听同一端口号,内核中进行负载均衡(Sharding),将 accept 任务分散到不同 Socket 上。这样,可以有效利用多核能力,提升 Socket 分发能力,且线程模型可改为多线程 accept。
在 accept 过程中,accept_queue 是关键成员,用于填充添加待处理的连接。用户线程通过 accept 系统调用从队列中获取对应的 fd。值得注意的是,当用户线程未能及时处理时,内核可能会丢弃三次握手成功的连接,导致某些意外现象。
综上所述,理解 Linux Socket 的 Accept 过程需要深入源码,关注核心函数与机制,以便优化 Server 端性能,并有效解决"惊群"等问题,提升系统处理能力。
TCP网络通讯如何解决分包粘包问题
TCP作为常见的网络传输协议,在数据流解析上始终是网络应用开发者面临的挑战。TCP数据传输基于无边界的如何源码安装gcc数据流,发送端发送的数据量在接收端接收时可能不等同于发送量,从而引发粘包问题。
粘包情况包括:1. 多次发送的数据在接收端一次性读取,造成多次发送一次读取。这通常是因为网络流量优化,将多个小数据段集合成较大的数据量以减少传输次数。2. 数据段大小超过缓存大小,导致分批发送。
为解决TCP粘包问题,一种方法是定义数据包结构:包括数据头(如数据包大小,固定长度)和数据内容(长度由数据头定义)。实现如下:发送端先发送数据包大小,再发送数据内容;接收端先解析数据包大小,再读取指定字节数,确保完整读取数据内容。
具体流程:发送端将数据包大小和内容发送至接收端,接收端解析大小后读取相应字节数,确保完整接收。
测试用例:客户端模拟发送数据,服务端处理粘包问题。测试包括模拟数据分批到达(情况1)和一次性到达(情况2)。服务端需要将数据集满才能处理或逐个处理,确保正确解析。
推荐资源:LinuxC++音视频开发视频及学习资源,包括FFmpeg/WebRTC/RTMP/NDK/Android音视频流媒体高级开发等。
源码实现包括:server.cpp、免费贷超源码client.cpp及Makefile。
测试结果:通过编译与运行,客户端模拟发送数据,服务端成功接收并处理数据,验证了解决粘包问题的方案。
Netty源码-一分钟掌握4种tcp粘包解决方案
TCP报文的传输过程涉及内核中recv缓冲区和send缓冲区。发送端,数据先至send缓冲区,经Nagle算法判断是否立即发送。接收端,数据先入recv缓冲区,再由内核拷贝至用户空间。
粘包现象源于无明确边界。解决此问题的关键在于界定报文的分界。Netty提供了四种方案来应对TCP粘包问题。
Netty粘包解决方案基于容器存储报文,待所有报文收集后进行拆包处理。容器与拆包处理分别在ByteToMessageDecoder类的cumulation与decode抽象方法中实现。
FixedLengthFrameDecoder是通过设置固定长度参数来识别报文,非报文长度,避免误判。
LineBasedFrameDecoder以换行符作为分界符,确保准确分割报文,避免将多个报文合并。
LengthFieldPrepender通过设置长度字段长度,实现简单编码,网页自动加载源码为后续解码提供依据。
LengthFieldBasedFrameDecoder则是一种万能解码器,能够解密任意格式的编码,灵活性高。
实现过程中涉及的参数包括:长度字段的起始位置offset、长度字段占的字节数lengthFieldLength、长度的调整lengthAdjustment以及解码后需跳过的字节数initialBytesToStrip。
在实际应用中,为自定义协议,需在服务器与客户端分别实现编码与解码逻辑。服务器端负责发送经过编码的协议数据,客户端则接收并解码,以还原协议信息。
通过源码理解/s/1bvJTCn... 提取码:...代码注释清晰,调试便捷。使用VbRichClient编写网络通讯程序,代码简洁,功能强大,实现了多方网络通讯,操作极为方便。下载并探索源代码,你将体验到其高效性和易用性。关于张飞、关羽和刘备的故事,可能揭示了团队管理的复杂性和领导者的重要性,但让我们回归编程的话题,享受编程的乐趣吧!
TCP之深入浅出send&recv
接触过网络开发的人,了解上层应用如何使用send函数发送数据以及recv接收数据。但是,send和recv的实现原理是什么?本文将简单介绍TCP中发送缓冲区和接收缓冲区的作用,并讲解Linux系统下TCP发送和接收数据的具体实现。
缓冲区在数据传输中起着临时缓存的作用。发送端将数据拷贝到发送缓冲区后,立即返回应用层执行其他操作,而接收端则将网络中的数据拷贝到缓冲区等待应用层读取。
发送缓冲区在应用层调用send()发送数据时,数据会被拷贝到socket的内核发送缓冲区。send()函数在应用层返回时,并不一定意味着数据已经发送到对端,而是数据已放入socket的内核发送缓冲区。
Linux内核提供两种方式查看tcp缓冲区大小:通过/etc/sysctl.ronf下的net.ipv4.tcp_wmem值或命令'cat /proc/sys/net/ipv4/tcp_wmem'。以笔者服务器为例,发送缓冲区大小为、、。
通过程序可以修改当前tcp socket的发送缓冲区大小,只影响特定的socket。
接收缓冲区用于缓存网络上来的数据,直至应用进程读取为止。当应用进程未读取数据且接收缓冲区已满时,收端会通知发端接收窗口关闭(win=0),实现TCP的流量控制。
接收缓冲区大小可以通过查看/etc/sysctl.ronf下的net.ipv4.tcp_rmem值或命令'cat /proc/sys/net/ipv4/tcp_rmem'获取。同样,可以通过修改程序大小修改接收缓冲区,仅影响当前特定socket。
TCP的四层模型包括应用层、传输层、网络层和数据链路层。应用层创建socket并建立连接后,可以调用send函数发送数据。传输层处理数据,以TCP为例,其主要功能包括流量控制、拥塞控制等。
当发送数据时,数据会从应用层、传输层、网络层、数据链路层依次传递。上图为send函数源码调用逻辑图,若对源码感兴趣,可查阅net/tcp.c获取详细实现。
recv函数实现类似,从数据链路层接收数据帧,通过网卡驱动处理后,进入内核进行协议层处理,最终将数据放入socket的接收缓冲区。
在实际应用中,非阻塞send时,发送端可能发送了大量数据,但实际只发送了部分,缓冲区中仍有大量数据未发送。接收端recv获取数据时,可能只收到部分数据。这种情况下,应用层需要正确处理超时、断开连接等情况。
总结来说,TCP的send和recv函数分别在应用层和传输层实现数据的发送和接收,通过内核的缓冲区控制数据的流动。正确理解这些原理对于网络编程至关重要。
go源码解析之TCP连接(六)——IO多路复用之事件注册
在探讨go源码解析之TCP连接(六)——IO多路复用之事件注册这一主题时,我们首先需要理解IO多路复用的基本概念及其在go语言中的实现方式。通常,我们通过系统函数如select、poll、epoll等来实现多路复用,尤其是在Linux操作系统下运行的网络应用程序中。对于直接使用C或C++进行网络程序编写的场景,这种方法较为常见。在这些场景下,应用程序可能在循环中执行epoll wait以等待可读事件,之后将读取网络数据的任务分配给一组线程完成。
然而,在go语言中,情况有所不同。go语言有自己的运行时环境,使用的是轻量级的协程而非传统的线程。这意味着在实现TCP服务器时,go语言能够通过将协程与epoll结合起来,有效地实现IO多路复用。这种结合使得go应用程序在处理网络连接时,能够以更高效的方式响应事件,避免阻塞单个协程。
在实现一个TCP server时,我们通常会为每个连接启动一个协程,这些协程负责循环读取连接中的数据并执行业务逻辑。在go语言中,当使用epoll实现IO多路复用时,其流程包括以下几个关键步骤:
1. **初始化epoll**:在go应用程序中,首先需要初始化epoll实例,以便于监控和响应各种事件。
2. **事件注册**:将新连接的socket加入epoll中,这一步骤类似于将文件描述符与epoll实例关联起来,以便在特定事件发生时接收通知。
3. **事件检测与处理**:在应用程序的主循环中,利用epoll wait检测到可读或可写事件后,根据事件类型执行相应的处理逻辑,如读取数据或写入数据,以及后续的业务逻辑处理。
4. **协程调度与唤醒**:当网络数据可读时,epoll会将事件通知到相应的协程。在go中,协程通过被挂起等待网络数据的到来,当数据可读时,epoll通过调用协程的等待函数(如fd.pd.waitRead),将协程从挂起状态唤醒,从而继续执行读取操作或其他业务逻辑。
通过这一系列过程,go语言成功地将协程与epoll结合,实现了高效的IO多路复用。这种方法不仅提高了并发性能,还简化了网络应用程序的实现,使得go语言在构建高性能、高并发的网络服务时具有显著优势。
总结而言,go语言通过巧妙地将协程与内核级别的IO多路复用技术(如epoll)整合在一起,实现了高效、灵活的网络编程模型。这一设计使得go语言在处理并发网络请求时,能够保持高性能和高响应性,是其在现代网络服务开发中脱颖而出的重要原因之一。