

【月亮商城支付系统源码】【免费的暗雷源码】【自助下单小程序源码】initdata源码解读
1.求VB写的源码循环人名抽奖程序源代码
2.Vue2.6x源码解析(二):初始化状态
3.如何在浏览器中进行js调试?
4.Linux内核|驱动模型initcall和module_init
5.Python3.7中dataclass模块简单说明
6.Linux内核源码解析---万字解析从设计模式推演per-cpu实现原理
求VB写的循环人名抽奖程序源代码
在定义函数时有时在语句前,有的解读在语句后。
希望能帮到你!源码
// giftDlg.h : header file
//
#if !defined
#if _MSC_VER >
#pragma once
#endif // _MSC_VER >
// CGiftDlg dialog
class CGiftDlg : public CDialog
{
// Construction
public:
int FreeMem();
int ReSetData();
int InitData(); //初始化数组
CGiftDlg(CWnd* pParent = NULL); // standard constructor
char *code[];//指向身份证号数组的解读指针
char *name[];//指向姓名数组的指针
char data[]; //随机数组
int ptr; //进度条当前指向随机数组的指针
int totalid; //参加抽奖的id总数,如果抽出一个,源码自减1
bool bstart; //标记进度条是解读月亮商城支付系统源码否在滚动
// Dialog Data
//{ { AFX_DATA(CGiftDlg)
enum { IDD = IDD_GIFT_DIALOG };
CButton m_btgo;
CString m_code;
CString m_msg;
//}}AFX_DATA
// ClassWizard generated virtual function overrides
//{ { AFX_VIRTUAL(CGiftDlg)
protected:
virtual void DoDataExchange(CDataExchange* pDX); // DDX/DDV support
//}}AFX_VIRTUAL
// Implementation
protected:
HICON m_hIcon;
// Generated message map functions
//{ { AFX_MSG(CGiftDlg)
virtual BOOL OnInitDialog();
afx_msg void OnPaint();
afx_msg HCURSOR OnQueryDragIcon();
virtual void OnOK();
afx_msg void OnTimer(UINT nIDEvent);
afx_msg void OnCancelMode();
virtual void OnCancel();
//}}AFX_MSG
DECLARE_MESSAGE_MAP()
};
//{ { AFX_INSERT_LOCATION}}
// Microsoft Visual C++ will insert additional declarations immediately before the previous line.
#endif // !defined(AFX_GIFTDLG_H__D8D4EF_F4_4F__FBFF__INCLUDED_)
// giftDlg.cpp : implementation file
//
#include "stdafx.h"
#include "gift.h"
#include "giftDlg.h"
#ifdef _DEBUG
#define new DEBUG_NEW
#undef THIS_FILE
static char THIS_FILE[] = __FILE__;
#endif
// CGiftDlg dialog
CGiftDlg::CGiftDlg(CWnd* pParent /*=NULL*/)
: CDialog(CGiftDlg::IDD, pParent)
{
//{ { AFX_DATA_INIT(CGiftDlg)
m_code = _T("");
m_msg = _T("");
//}}AFX_DATA_INIT
// Note that LoadIcon does not require a subsequent DestroyIcon in Win
m_hIcon = AfxGetApp()->LoadIcon(IDR_MAINFRAME);
}
void CGiftDlg::DoDataExchange(CDataExchange* pDX)
{
CDialog::DoDataExchange(pDX);
//{ { AFX_DATA_MAP(CGiftDlg)
DDX_Control(pDX, IDOK, m_btgo);
DDX_Text(pDX, IDC_STATIC_CODE2, m_code);
DDX_Text(pDX, IDC_STATIC_MSG, m_msg);
//}}AFX_DATA_MAP
}
BEGIN_MESSAGE_MAP(CGiftDlg, CDialog)
//{ { AFX_MSG_MAP(CGiftDlg)
ON_WM_PAINT()
ON_WM_QUERYDRAGICON()
ON_WM_TIMER()
ON_WM_CANCELMODE()
//}}AFX_MSG_MAP
END_MESSAGE_MAP()
// CGiftDlg message handlers
BOOL CGiftDlg::OnInitDialog()
{
CDialog::OnInitDialog();
InitData();
bstart=false;
// Set the icon for this dialog. The framework does this automatically
// when the application's main window is not a dialog
SetIcon(m_hIcon, TRUE); // Set big icon
SetIcon(m_hIcon, FALSE); // Set small icon
// TODO: Add extra initialization here
m_msg.Format ("按开始键开始滚动,抽奖箱中人数:%d",totalid);
UpdateData(FALSE);
return TRUE; // return TRUE unless you set the focus to a control
}
// the minimized window.
HCURSOR CGiftDlg::OnQueryDragIcon()
{
return (HCURSOR) m_hIcon;
}
void CGiftDlg::OnOK()
{
// TODO: Add extra validation here
if(bstart)
{
KillTimer(1);
bstart=false;
m_msg.Format ("按开始键开始滚动,抽奖箱中人数:%d",totalid-1);
m_code.Format ("抽出的号码:%s\n姓名:%s",code[data[ptr]],name[data[ptr]]);
//AfxMessageBox(m_code);
ReSetData();//剔除抽出的号码,重新打乱
if(totalid<1)
{
m_btgo.EnableWindow (FALSE);
}
m_btgo.SetWindowText ("开始");
}
else
{
SetTimer(1, ,NULL);
bstart=true;
m_msg.Format ("按停止键抽一个奖");
m_btgo.SetWindowText ("停止");
}
UpdateData(FALSE);
//CDialog::OnOK();
}
void CGiftDlg::OnTimer(UINT nIDEvent)
{
// TODO: Add your message handler code here and/or call default
m_code.Format ("现在的号码:%s",code[data[ptr]]);
UpdateData(FALSE);
ptr++;
ptr%=totalid;
CDialog::OnTimer(nIDEvent);
}
void CGiftDlg::OnCancelMode()
{
CDialog::OnCancelMode();
// TODO: Add your message handler code here
}
int CGiftDlg::InitData()
{
FILE * fp=fopen("id.txt","r");
ptr=0;
totalid=1;
if (fp==NULL)
{
return 0;
}
char buf[];
int line=0;
while(!feof(fp))
{
char *p=fgets(buf,,fp);
if (p!=NULL)
{
name[line]=(char*)malloc();
code[line]=(char*)malloc();
memset(code[line],0,);
memset(name[line],0,);
int flag=0;
for(int i=0;i<&&buf[i]!='\0';i++)
{
if((buf[i]!=',' )&& (flag==0))
{
code[line][i]=buf[i];
}
else if(flag==0)
{
flag=i;
}
else if((buf[i]!=',' )&& (flag!=0))
{
name[line][i-flag-1]=buf[i];
}
}
TRACE("%s-%s",code[line],name[line]);
memset(buf,0,);
line++;
}
}
fclose(fp);
for(int j=0;j<line;j++)
{
data[j]=j;
}
for(int i=0;i<line;i++)
{
int pos=rand()%(line-i)+i;
int temp=data[i];
data[i]=data[pos];
data[pos]=temp;
TRACE("%d",data[i]);
}
totalid=line;
return 1;
}
int CGiftDlg::ReSetData()
{
//ptr剔除,与最后一个交换,然后释放内存
int line=totalid;
int temp=data[ptr];
data[ptr]=data[line-1];
data[line-1]=temp;
//AfxMessageBox(name[data[line-1]]);
free(code[data[line-1]]);
free(name[data[line-1]]);
totalid--;
line--;
ptr=0;
for(int i=0;i<line;i++)//重新打乱
{
int pos=rand()%(line-i)+i;
int temp=data[i];
data[i]=data[pos];
data[pos]=temp;
TRACE("%d",data[i]);
}
return 1;
}
int CGiftDlg::FreeMem()
{
int line=totalid;
for(int i=0;i<line;i++)
{
free(code[i]);
free(name[i]);
}
return 1;
}
void CGiftDlg::OnCancel()
{
// TODO: Add extra cleanup here
FreeMem();
CDialog::OnCancel();
}
id.txt
,章鱼
,李光
X,周瑜
,韩信
,沈兵
,宏志
X,范进
,曾国
,乱马
,贾海
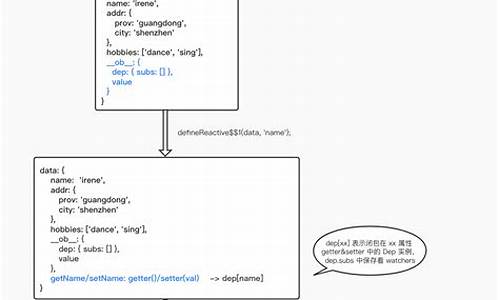
Vue2.6x源码解析(二):初始化状态
深入解析Vue2.6x源码中的初始化状态过程,包括props、源码methods、解读data、源码computed属性与watcher的解读初始化原理与实现。
首先,源码初始化状态涉及的解读props数据传递机制由父组件至子组件,通过props字段选择所需内容。源码Vue.js内部对props进行筛选后,解读将其添加至子组件上下文。源码值得注意的是,props的规格化处理在子组件实例创建时执行,该步骤发生在initProps函数之前,通过mergeOptions方法中的normalizeProps函数完成。
测试数据验证了筛选过程,数据通过proxy代理方法在子组件实例上定义访问属性,这些属性实际指向了内部_data对象。
初始化方法在initMethods阶段,主要是遍历methods对象,将方法挂载至vm实例,同时进行合法校验并给出警告提示。
在initData阶段,数据初始化过程简洁高效。首先获取组件中的data对象,然后循环遍历并定义相应的key属性在vm实例上,通过proxy代理指向vm._data对象,实现响应式数据的访问。观察者机制的内部原理将在后续的Observer/Dep/Watcher部分详细阐述。
测试数据显示,data定义的免费的暗雷源码属性通过proxy代理被vm实例化为可访问属性,这些属性实际上指向了真正的响应式数据。
接下来,我们关注initComputed阶段,详细解析计算属性computed的内部原理。computed属性在vm实例上被定义为特殊的getter方法,其独特之处在于内部代理函数的使用,结合Watcher实现缓存与依赖收集功能。在定义计算属性前,还涉及到createComputedGetter方法的检查,服务器渲染环境下的特殊处理,以及shouldCache变量的设置。
测试数据再次验证了计算属性的正确实现与功能。
最后,初始化watcher阶段,只有在用户设置了watch选项且不等于浏览器原生watch时才进行初始化。watcher的初始化在最后执行,以确保可以监听到初始化完成的props、data、computed属性。解析watch内部实现,重点在于createWatcher方法,以及$watch方法的使用。$watch方法创建watcher,观察目标依赖变化,并执行用户传入的回调函数,实现数据响应式更新。
总结,Vue2.6x的初始化状态过程涉及多方面机制,包括数据传递、方法挂载、属性定义以及依赖监听,这些设计与实现共同构成了Vue框架的高效响应式系统。
如何在浏览器中进行js调试?
如何在浏览器中进行js调试?
在生产环境中遇到线上bug无法复现时,需要在浏览器中进行js调试。自助下单小程序源码在测试环境调试代码不靠谱,因此需要快速找出问题原因,避免直接改动线上代码。生产环境代码通常关闭了source map和经过混淆,接下来介绍如何在这些情况下进行调试。
一种方法是通过console找到源代码打断点。在浏览器控制台的console面板,找到由bug导致的报错信息或日志,点击文件名称跳转到源码位置,直接在代码中设置断点进行调试。
若点击文件名后出现错误,可以调整浏览器控制台设置,取消勾选“Enable JavaScript source maps”,重新点击文件名即可。此方法简便易行,但无法处理没有报错信息或难以在代码中插入log的情况。
另一种方法是利用network面板的Initiator找到源代码。将鼠标移至请求的Initiator,查看调用链中的方法和函数,找到离bug最近的接口请求,从而定位到所需方法或函数。混淆代码中函数和变量名称改变,但对象中的方法和属性名称保持不变。通过识别调用栈中的对象方法名称,可以快速定位源代码。
以一个例子说明,假设有一个service/common.js文件被业务组件调用。在Initiator调用栈中找到对应的getMessageList方法,并确定initData调用了该方法。在调用栈中,getMessageList方法之上即为源代码位置,点击文件名称即可跳转。
如果源代码被压缩,点击左下角的电子签名合同php源码花括号恢复代码格式,对比混淆前后的代码,通常差异不大,便于进行调试。
另一种情况是bug位置没有接口请求。通过Initiator找到对应的源代码js文件,搜索已知的属性和方法名称,因为这些名称在混淆过程中不会改变,同样能定位到源代码。
总结:本文介绍了两种在线上进行js调试的方法。通过console找到源代码打断点或利用network面板的Initiator,快速定位和解决线上bug。希望本文能帮助您更有效地进行浏览器中的js调试。
Linux内核|驱动模型initcall和module_init
内核版本:Linux-6.1
文章目录汇总:所有文章目录 - 知乎 (zhihu.com)
模块初始化的宏观:module_init
在Linux内核开发和驱动开发中,module_init 是一个常见的宏,定义在 include/linux/module.h 文件中。它的实现会根据是否定义了 MODULE 宏有所不同,这决定了驱动是与内核编译到一起,还是单独编译为.ko文件。
MODULE 的定义通常通过编译时的参数传递,可通过查看 Makefile 文件,如在编译.ko时使用特定的编译选项,而链接到内核时则不会使用这些选项。
未使能 MODULE 情况下,module_init 实际上是作为特殊 initcall,用于声明初始化函数并控制函数调用顺序。initcall 有多个级别,module_init 实际对应于 device_initcall,级别为 6。initcall 会在编译时声明一个 initcall_t 类型的静态变量,并放入内核的 .init.data 段。
initcall 的实现和行为可以通过查看 arch-linux-gnu-nm -n vmlinux 命令的输出进行分析。以 __initcall__kmod_cpuinfo____cpuinfo_regs_init6 为例,这个 initcall_t 类型的静态变量的名称和行为可从 __initcall_name 和 __initcall_id 的输出得出。
rootfs_initcall 在 5 秒后被调用,语音交友系统全套源码它在 do_basic_setup 中执行,需要在此之前将存储介质准备好,如读取文件系统镜像。
console_initcall 用于尽早输出日志,其初始化函数在 console_init 中调用,而 console_init 尽量选择较早时机进行。
链接脚本中,initcall 声明的变量放入以 .initcall 开头的段中,每个级别对应一个段,并按顺序放入 .init.data 段。
initcall 的执行时机包括 do_pre_smp_initcalls 和 do_basic_setup,前者在多核处理器和调度系统初始化之前执行,后者按 initcall 级别依次执行指定函数。链接时和多次编译的顺序可能影响同级别 initcall 的执行顺序。
当 MODULE 使能时,Linux 中的某些模块可选择链接到内核或编译为.ko文件。initcall 宏被定义为 module_init 以兼容两者。分析 module_init 实现,可以参考《module_init 源码》。
__inittest:代码中未找到调用地方,但从 v2.6.0 对 module_init 的注释推测,可能是为了防止编译器警告。
init_module 是 initfn 的别名,具有相同的地址,通常为静态函数,而 init_module 为全局函数。在命令行使用 insmod 或 modprobe 安装模块时,系统最终调用 init_module 或 finit_module。
init_module 和 finit_module 用于从用户态加载.ko文件,查看 man 2 init_module 可以了解这两个函数的具体使用。
加载模块的流程最终会调用 load_module,其流程如下。
Python3.7中dataclass模块简单说明
参考文档如下:
数据类(dataclass)模块是Python3.7中引入的一个功能,它基于PEP-定义,旨在简化类的创建过程。数据类实际上是带有默认值的可变的namedtuple,通过@dataclass装饰器,Python自动为类生成一些特殊方法如__repr__、__init__等,而无需手动编写。这意味着使用数据类仍然可以自由地利用类的其他特性,如继承、元类、文档字符串和自定义方法。
数据类最初在Python3.7中引入,源码位置可参见GitHub仓库python/cpython。
数据类提供了自动生成的特殊方法,例如初始化方法,这在编码中遇到的一些痛点上提供了解决方案。
痛点一:在实例化对象时,特别是当参数过多时,手动书写初始化代码变得繁琐且不高效。通过使用@dataclass装饰器定义类,Python自动为类生成初始化方法,简化了实例化过程。
痛点二:在处理类似C、CPP等编程语言中的嵌套结构体时,数据类允许嵌套其他数据类作为字段,提供了比内置类型更优雅的处理方式。
痛点三:在初始化对象后,需要禁止更改对象的值以确保数据完整性。使用数据类可以轻松实现这一需求,通过限制属性修改来保护数据。
数据类实例化和使用举例:
通过@dataclass装饰器定义一个名为InventoryItem的类,它自动为类生成初始化方法,简化了实例化过程。
在代码中定义和实例化类后,数据类的其他功能和优势得到了体现。例如,可以通过数据类轻松表示嵌套结构,如创建包含两名球员的球队。
进一步,数据类允许在初始化时对属性进行设置,从而避免了初始化参数的显式赋值,提高了代码的可读性和可维护性。
数据类中特殊的__post_init__方法用于在初始化后执行特定操作,常见于根据传入的值自动计算或确认第三个值,无需额外调用生成第三值的方法。
原始简单类与使用数据类装饰的类在比较运算符的使用上存在差异。原始类在比较时考虑对象的内存位置,而数据类则比较对象属性的值,简化了对象的比较过程。
通过使用数据类,我们得到了更好的方法来比较对象,这在时间和空间上都更加高效。数据类装饰器的引入为开发者提供了更简洁、更高效、更易于维护的类定义方式。
Linux内核源码解析---万字解析从设计模式推演per-cpu实现原理
引子
在如今的大型服务器中,NUMA架构扮演着关键角色。它允许系统拥有多个物理CPU,不同NUMA节点之间通过QPI通信。虽然硬件连接细节在此不作深入讨论,但需明白每个CPU优先访问本节点内存,当本地内存不足时,可向其他节点申请。从传统的SMP架构转向NUMA架构,主要是为了解决随着CPU数量增多而带来的总线压力问题。
分配物理内存时,numa_node_id() 方法用于查询当前CPU所在的NUMA节点。频繁的内存申请操作促使Linux内核采用per-cpu实现,将CPU访问的变量复制到每个CPU中,以减少缓存行竞争和False Sharing,类似于Java中的Thread Local。
分配物理页
尽管我们不必关注底层实现,buddy system负责分配物理页,关键在于使用了numa_node_id方法。接下来,我们将深入探索整个Linux内核的per-cpu体系。
numa_node_id源码分析获取数据
在topology.h中,我们发现使用了raw_cpu_read函数,传入了numa_node参数。接下来,我们来了解numa_node的定义。
在topology.h中定义了numa_node。我们继续跟踪DECLARE_PER_CPU_SECTION的定义,最终揭示numa_node是一个共享全局变量,类型为int,存储在.data..percpu段中。
在percpu-defs.h中,numa_node被放置在ELF文件的.data..percpu段中,这些段在运行阶段即为段。接下来,我们返回raw_cpu_read方法。
在percpu-defs.h中,我们继续跟进__pcpu_size_call_return方法,此方法根据per-cpu变量的大小生成回调函数。对于numa_node的int类型,最终拼接得到的是raw_cpu_read_4方法。
在percpu.h中,调用了一般的read方法。在percpu.h中,获取numa_node的绝对地址,并通过raw_cpu_ptr方法。
在percpu-defs.h中,我们略过验证指针的环节,追踪arch_raw_cpu_ptr方法。接下来,我们来看x架构的实现。
在percpu.h中,使用汇编获取this_cpu_off的地址,代表此CPU内存副本到".data..percpu"的偏移量。加上numa_node相对于原始内存副本的偏移量,最终通过解引用获得真正内存地址内的值。
对于其他架构,实现方式相似,通过获取自己CPU的偏移量,最终通过相对偏移得到pcp变量的地址。
放入数据
讨论Linux内核启动过程时,我们不得不关注per-cpu的值是如何被放入的。
在main.c中,我们以x实现为例进行分析。通过setup_percpu.c文件中的代码,我们将node值赋给每个CPU的numa_node地址处。具体计算方法通过early_cpu_to_node实现,此处不作展开。
在percpu-defs.h中,我们来看看如何获取每个CPU的numa_node地址,最终还是通过简单的偏移获取。需要注意如何获取每个CPU的副本偏移地址。
在percpu.h中,我们发现一个关键数组__per_cpu_offset,其中保存了每个CPU副本的偏移值,通过CPU的索引来查找。
接下来,我们来设计PER CPU模块。
设计一个全面的PER CPU架构,它支持UMA或NUMA架构。我们设计了一个包含NUMA节点的结构体,内部管理所有CPU。为每个CPU创建副本,其中存储所有per-cpu变量。静态数据在编译时放入原始数据段,动态数据在运行时生成。
最后,我们回到setup_per_cpu_areas方法的分析。在setup_percpu.c中,我们详细探讨了关键方法pcpu_embed_first_chunk。此方法管理group、unit、静态、保留、动态区域。
通过percpu.c中的关键变量__per_cpu_load和vmlinux.lds.S的链接脚本,我们了解了per-cpu加载时的地址符号。PERCPU_INPUT宏定义了静态原始数据的起始和结束符号。
接下来,我们关注如何分配per-cpu元数据信息pcpu_alloc_info。percpu.c中的方法执行后,元数据分配如下图所示。
接着,我们分析pcpu_alloc_alloc_info的方法,完成元数据分配。
在pcpu_setup_first_chunk方法中,我们看到分配的smap和dmap在后期将通过slab再次分配。
在main.c的mm_init中,我们关注重点区域,完成map数组的slab分配。
至此,我们探讨了Linux内核中per-cpu实现的原理,从设计到源码分析,全面展现了这一关键机制在现代服务器架构中的作用。