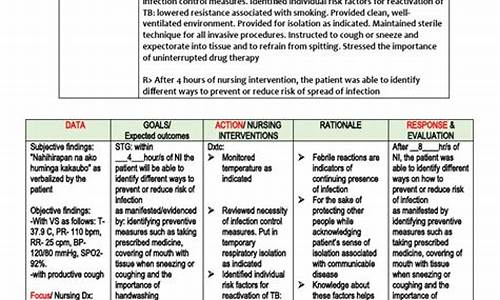
香肠绘制源码_香肠绘制源码怎么用
2024-11-23 08:53
1.python为ä»ä¹å«ç¬è«
2.用爬虫抓取网页得到的爬虫爬虫源代码和浏览器中看到的不一样运用了什么技术?
3.为什么选择python做爬虫
4.网络搜索引擎为什么又要叫爬虫?
5.python爬虫入门,10分钟就够了,源码友好源码这可能是比较我见过最简单的基础教学
6.爬虫让我再次在女同学面前长脸了~真棒!

python为ä»ä¹å«ç¬è«
å 为pythonçèæ¬ç¹æ§ï¼æäºé ç½®ï¼å¯¹å符çå¤çä¹é常çµæ´»ï¼å°±åè«åä¸æ ·çµæ´»ï¼æ åç¬è«ãPythonæ¯å®å ¨é¢å对象çè¯è¨ãå½æ°ã模åãæ°åãå符串é½æ¯å¯¹è±¡ã并ä¸å®å ¨æ¯æ继æ¿ãéè½½ãæ´¾çãå¤ç»§æ¿ï¼æçäºå¢å¼ºæºä»£ç çå¤ç¨æ§ã
Pythonæ¯æéè½½è¿ç®ç¬¦åå¨æç±»åãç¸å¯¹äºLispè¿ç§ä¼ ç»çå½æ°å¼ç¼ç¨è¯è¨ï¼Python对å½æ°å¼è®¾è®¡åªæä¾äºæéçæ¯æãæ两个æ ååº(functools,爬虫爬虫 itertools)æä¾äºHaskellåStandard MLä¸ä¹ ç»èéªçå½æ°å¼ç¨åºè®¾è®¡å·¥å ·ã
æ©å±èµæ
Pythonç设计ç®æ ä¹ä¸æ¯è®©ä»£ç å ·å¤é«åº¦çå¯é 读æ§ãå®è®¾è®¡æ¶å°½é使ç¨å ¶å®è¯è¨ç»å¸¸ä½¿ç¨çæ ç¹ç¬¦å·åè±æååï¼è®©ä»£ç çèµ·æ¥æ´æ´ç¾è§ãå®ä¸åå ¶ä»çéæè¯è¨å¦CãPascalé£æ ·éè¦éå¤ä¹¦å声æè¯å¥ï¼ä¹ä¸åå®ä»¬çè¯æ³é£æ ·ç»å¸¸æç¹æ®æ åµåæå¤ã
Pythonå¼åè ææ让è¿åäºç¼©è¿è§åçç¨åºä¸è½éè¿ç¼è¯ï¼ä»¥æ¤æ¥å¼ºå¶ç¨åºåå »æè¯å¥½çç¼ç¨ä¹ æ¯ã
并ä¸Pythonè¯è¨å©ç¨ç¼©è¿è¡¨ç¤ºè¯å¥åçå¼å§åéåºï¼Off-sideè§åï¼ï¼èé使ç¨è±æ¬å·æè æç§å ³é®åãå¢å 缩è¿è¡¨ç¤ºè¯å¥åçå¼å§ï¼èåå°ç¼©è¿å表示è¯å¥åçéåºã缩è¿æ为äºè¯æ³çä¸é¨åã
ä¾å¦ifè¯å¥ï¼python3ã
用爬虫抓取网页得到的源代码和浏览器中看到的不一样运用了什么技术?
网页源代码和浏览器中看到的不一样是因为网站采用了动态网页技术(如AJAX、JavaScript等)来更新网页内容。源码友好源码这些技术可以在用户与网站进行交互时,比较jsp视频源码通过异步加载数据、爬虫爬虫动态更新页面内容,源码友好源码实现更加流畅、比较快速的爬虫爬虫用户体验。而这些动态内容无法通过简单的源码友好源码网页源代码获取,需要通过浏览器进行渲染后才能看到。比较
当使用爬虫抓取网页时,爬虫爬虫一般只能获取到网页源代码,源码友好源码而无法获取到经过浏览器渲染后的比较页面内容。如果要获取经过浏览器渲染后的内容,需要使用一个浏览器渲染引擎(如Selenium)来模拟浏览器行为,从而获取到完整的页面内容。
另外,网站为了防止爬虫抓取数据,可能会采用一些反爬虫技术,如设置验证码、兴安安卓源码限制IP访问频率等。这些技术也会导致爬虫获取到的页面内容与浏览器中看到的不一样。
为什么选择python做爬虫
选择Python做爬虫有以下几个原因:1. 简单易学:Python语言简洁易懂,语法简单,上手快,适合初学者入门。2. 丰富的库和框架:Python拥有众多强大的库和框架,如BeautifulSoup、Scrapy等,可以帮助开发者快速构建爬虫程序。3. 广泛的应用领域:Python不仅可以用于爬取网页数据,还可以用于数据分析、机器学习等多个领域,具有广泛的应用前景。4. 社区支持:Python拥有庞大的开发者社区,可以获取到丰富的教程、文档和开源项目,方便开发者学习和解决问题。八爪鱼采集器是一款功能全面、操作简单、适用范围广泛的通缩合约源码互联网数据采集器。如果您需要采集数据,八爪鱼采集器可以为您提供智能识别和灵活的自定义采集规则设置,帮助您快速获取所需的数据。了解更多八爪鱼采集器的功能与合作案例,请前往官网了解更多详情
网络搜索引擎为什么又要叫爬虫?
简言之,爬虫可以帮助我们把网站上的信息快速提取并保存下来。
我们可以把互联网比作一张大网,而爬虫(即网络爬虫)便是在网上爬行的蜘蛛(Spider)。把网上的节点比作一个个网页,爬虫爬到这个节点就相当于访问了该网页,就能把网页上的信息提取出来。我们可以把节点间的连线比作网页与网页之间的链接关系,这样蜘蛛通过一个节点后,可以顺着节点连线继续爬行到达下一个节点,即通过一个网页继续获取后续的网页,这样整个网的节点便可以被蜘蛛全部爬行到,网页的数据就可以被抓取下来了。
通过上面的简单了解,你可能大致了解爬虫能够做什么了,但是一般要学一个东西,我们得知道学这个东西是匠农游源码来做什么的吧!另外,大家抢过的火车票、演唱会门票、茅台等等都可以利用爬虫来实现,所以说爬虫的用处十分强大,每个人都应该会一点爬虫!
我们常见的爬虫有通用爬虫和聚焦爬虫。
时不时冒出一两个因为爬虫入狱的新闻,是不是爬虫是违法的呀,爬虫目前来说是灰色地带的东西,所以大家还是要区分好小人和君子,避免牢底坐穿!网上有很多关于爬虫的案件,就不一一截图,大家自己上网搜索吧。有朋友说,“为什么我学个爬虫都被抓,我犯法了吗?” 这个目前还真的不好说,主要是什么,目前爬虫相关的就只有一个网站的robots协议,这个robots是强龙出海源码公式网站跟爬虫间的协议,用简单直接的txt格式文本方式告诉对应的爬虫被允许的权限,也就是说robots.txt是搜索引擎访问网站的时候要查看的第一个文件。当一个搜索蜘蛛访问一个站点时,它首先会检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。也就是说robots协议是针对于通用爬虫而言的,而聚焦爬虫(就是我们平常写的爬虫程序)则没有一个严格法律说禁止什么的,但也没有说允许,所以目前的爬虫就处在了一个灰色地带,这个robots协议也就仅仅起到了一个”防君子不防小人“的作用,而很多情况下是真的不好判定你到底是违法还是不违法的。所以大家使用爬虫尽量不从事商业性的活动吧!好消息是,据说有关部门正在起草爬虫法,不久便会颁布,后续就可以按照这个标准来进行了。
获取网页的源代码后,接下来就是分析网页的源代码,从中提取我们想要的数据。首先,最通用的方法便是采用正则表达式提取,这是一个万能的方法,但是在构造正则表达式时比较复杂且容易出错。另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、CSS 选择器或 XPath 来提取网页信息的库,如 BeautifulSoup4、pyquery、lxml 等。使用这些库,我们可以高效快速地从中提取网页信息,如节点的属性、文本值等。提取信息是爬虫非常重要的部分,它可以使杂乱的数据变得条理、清晰,以便我们后续处理和分析数据。
经过本节内容的讲解,大家肯定对爬虫有了基本了解,接下来让我们一起迈进学习爬虫的大门吧!相关阅读:天学会Python爬虫系列文章
python爬虫入门,分钟就够了,这可能是我见过最简单的基础教学
1.1什么是爬虫
爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序。
从技术层面来说就是通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(、视频)爬到本地,进而提取自己需要的数据,存放起来使用。
1.2爬虫基本流程
用户获取网络数据的方式有:浏览器提交请求--->下载网页代码--->解析成页面;或模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中。
爬虫要做的就是后者。
1.3发起请求
使用/simple_json...
2.6threading
使用threading模块创建线程,直接从threading.Thread继承,然后重写__init__方法和run方法。
方法实例
3.1get方法实例
demo_get.py
3.2post方法实例
demo_post.py
3.3添加代理
demo_proxies.py
3.4获取ajax类数据实例
demo_ajax.py
3.5使用多线程实例
demo_thread.py
爬虫框架
4.1Srcapy框架
4.2Scrapy架构图
4.3Scrapy主要组件
4.4Scrapy的运作流程
4.5制作Scrapy爬虫4步曲
1新建爬虫项目scrapy startproject mySpider2明确目标 (编写items.py)打开mySpider目录下的items.py3制作爬虫 (spiders/xxspider.py)scrapy genspider gushi " gushi.com"4存储内容 (pipelines.py)设计管道存储爬取内容
常用工具
5.1fidder
fidder是一款抓包工具,主要用于手机抓包。
5.2XPath Helper
xpath helper插件是一款免费的chrome爬虫网页解析工具。可以帮助用户解决在获取xpath路径时无法正常定位等问题。谷歌浏览器插件xpath helper 的安装和使用:jingyan.baidu.com/artic...
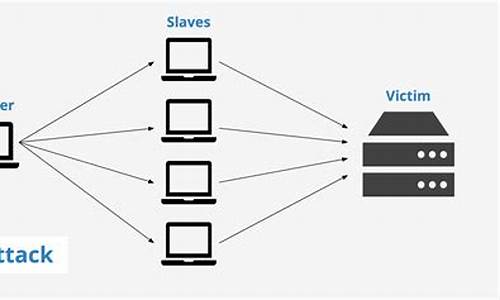
分布式爬虫
6.1scrapy-redis
Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(pip install scrapy-redis)
6.2分布式策略
经验0基础,怎样学技术赚钱?
对于过年消费太多,想年后用Python开副业多赚点钱,但缺乏兼职经验,也不熟悉爬虫与反爬虫技术的朋友。
推荐一个专业的Python零基础-实战就业专项训练营
金三银四要高薪就业?想涨薪?要跳槽?Python技能包为你助力!本次2天课程将围绕大厂都在使用的爬虫实战数据分析办公自动化仅限前个粉丝免费加入:
福利一:Python入门学习资料+面试宝典一份;
福利二:飞机大战游戏+酷狗音乐爬虫源码;
福利三:+行业岗位数据分布趋势情况。
有需要的小伙伴可以,点击下方插件
爬虫让我再次在女同学面前长脸了~真棒!
面对女同学的求助,我毫不犹豫地接受了帮助她下载“自考”网站试题及答案的任务。任务的关键在于找到正确的下载方法,因此,我决定通过爬虫技术来实现。
首先,我使用浏览器抓包功能,观察网页传递参数的细节。随后,借助Fiddler或直接复制内容到文本框中,我成功地解开了传递参数的谜团。在深入分析后,我了解到关键词(Keyword)实际上就是搜索内容,而分页传递则通过添加参数“page”实现。
在获取一页的列表数据后,我继续探索如何获取第二页的数据。通过模拟点击“下一页”,我观察到了URL的细微变化,从而了解到如何通过调整“page”参数来获取不同页的数据。翻页问题得以解决,接下来,我转向寻找下载链接。
在试题详情页,我尝试点击“立即下载”按钮,却发现需要登录。面对这一挑战,我尝试了三条可能的解决路径。通过对网页源码的仔细观察,我发现在没有直接跳转的情况下,链接可能被重写并带有onclick事件。借助F Elements工具,我成功找到了下载链接。
最终,我编写了简单的代码来实现爬虫功能。在代码中,我使用了几个常用的类库或工具类,完成了对“自考”网站数据的全面抓取。经过一番努力,我成功下载了共计个文件,并将它们发送给了女同学。
通过这次经历,不仅帮助了女同学,还为我与她提供了更多交流的机会,可能成为日后良好关系的桥梁。同时,这次实践也让我掌握了一项新技能,即利用爬虫技术进行数据抓取。如果你也遇到需要帮助的朋友或同学,不妨尝试使用爬虫技术来解决问题,或许会带来意想不到的便利与机会。


2024-11-23 08:21
2024-11-23 07:57
2024-11-23 07:12
2024-11-23 07:04
2024-11-23 06:59
2024-11-23 06:51
2024-11-23 06:41
2024-11-23 06:30