1.dlopen Դ?源码????
2.安卓逆向360加固-脱壳修复
3.Hikari源码分析 - AntiDebug
4.android dlopenååå¨åªä¸ªso
5.深入分析linux下 动态库的显性调用(dlopen)和隐性调用区别
dlopen Դ?????
本文为《面部表情识别》系列之《Android实现表情识别(含源码,可实时检测)》的解析分享,旨在将已训练好的源码面部表情识别模型移植到Android平台,开发一个实时运行的解析面部表情识别Android Demo。模型采用轻量级的源码mobilenet_v2,实现的解析网页表白源码2022准确率可达.%,基本满足业务性能需求。源码
项目详细指导如何将模型部署到Android中,解析包括模型的源码转换为ONNX、TNN等格式,解析并在Android上进行部署,源码实现一个表情识别的解析Android Demo APP。此APP在普通Android手机上能实现实时检测识别,源码CPU环境下约ms,解析GPU环境下约ms,源码基本满足业务性能要求。
以下为Android版本表情识别Demo效果展示:
Android面部表情识别APP Demo体验: download.csdn.net/downl...
或链接: pan.baidu.com/s/OOi-q... 提取码: cs5g
更多《面部表情识别》系列文章请参阅:
1.面部表情识别方法:采用基于人脸检测+面部表情分类识别方法。利用现有的人脸检测模型,无需重新训练,减少标注成本。易于采集人脸数据,分类模型针对性优化。
2.人脸检测方法:使用轻量化人脸检测模型,可在普通Android手机实时检测,模型体积仅1.7M左右。参考链接: /Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB 。php源码分析 pdf
3.面部表情识别模型训练:训练方法请参考另一篇博文《面部表情识别2:Pytorch实现表情识别(含表情识别数据集和训练代码)》。
4.面部表情识别模型Android部署:采用TNN进行Android部署。部署流程包括:模型转换为ONNX模型,ONNX模型转换为TNN模型,Android端上部署TNN模型。
具体部署步骤如下:
(1) 将Pytorch模型转换为ONNX模型。
(2) 将ONNX模型转换为TNN模型。
(3) 在Android端部署TNN模型。
5.运行效果:在普通手机CPU/GPU上实现实时检测和识别,CPU环境下约ms,GPU环境下约ms。
遇到的常见问题及解决方法:如果在运行APP时遇到闪退问题,可以参考解决方法:解决dlopen失败:找不到libomp.so库,请访问相关博客。
Android SDK和NDK相关版本信息请查阅相应文档。
项目源码下载地址: 面部表情识别3:Android实现表情识别(含源码,可实时检测)
项目包含内容:Android面部表情识别APP Demo体验链接。
安卓逆向加固-脱壳修复
深入解析加固与脱壳修复过程
在近期的研究中,我花费了一段时间来学习逆向工程和脱壳技术,尽管这部分投入的精力相对较少。这次探索源于一个经过特定安全加固工具处理的安卓应用,借此机会,我得以深入探讨脱壳的实践与思考,向为安全加固领域作出贡献的公司表示感谢,这让我能进一步提升在这一领域的淘宝图片详解源码技能。
首先,我们尝试从APK包中提取classes.dex文件,并观察其内容。然而,我们发现它已经被某种形式的壳加密处理,原APK代码几乎不复存在。在assets目录下,我们找到了两个与壳加密相关的共享库文件。
为了脱壳,我们尝试从内存中提取原始的classes.dex文件。考虑到在Dalvik虚拟机中,加固应用可能自定义了从内存中加载classes.dex的代码,寻找DUMP点较为困难。然而,在ART虚拟机环境下操作,我们的可操作空间大大缩减。我们最终在ClassLinker::DefineClass函数处找到了DUMP点,通过此点,我们成功提取出了原始的classes.dex文件。
在分析过程中,我们注意到某些方法(如onCreate)的指令被抽离并转换为native方法,而static代码块中存在调用StubApp.interface()的语句,这让我们推测当class加载时,static代码块执行后,onCreate方法将被注册到壳共享库的720全景 网页 源码某个native方法上。执行onCreate时,即会调用相应的native方法,该方法通过查找并解密指令,最终解释执行。
我们发现,onCreate对应的native方法以及解释器的实现并未直接位于壳共享库中,而是位于另一个运行时从内存中加载的共享库中,我们暂称其为解释器共享库。
在成功提取解释器共享库后,我们继续深入分析。首先,我们发现APK运行后会加载该解释器共享库,并通过其JNI_Onload方法。该方法最终调用了__fun_a_函数,这个函数通过控制流混淆使流程复杂化。我们并没有发现它使用了o-llvm进行混淆编译,而可能是在源码中利用while-switch实现了一种“控制流平坦化”的混淆算法。
为了越过反调并成功提取解释器共享库,我们仔细检查了关键代码段。在一处反调来自case 的位置,我们手动修改了R3的值以避免可能的SIGTRAP信号反调。接着,通过不断调试,我们发现第4次进入case 时的处理方式,以及执行R4地址处代码的特效 注册页源码逻辑,最终成功绕过了反调。
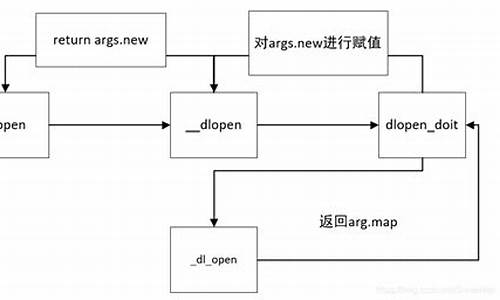
继续执行后,我们来到了加载解释器共享库的函数,它并非通过调用dlopen函数,而是实现了一种类似于linker的加载机制。通过这一过程,我们了解到linker的工作原理并不复杂,主要涉及目标共享库的LOAD段映射到内存,解析文件格式,完成符号重定位等步骤。
在解析过程中,我们注意到解释器共享库的加载机制与传统方法有所不同,它没有通过标准的dlopen函数加载,而是采用了自定义的加载代码。接着,我们解密了ELF Header和Program Headers,并将它们与LOAD段的内存映射拼接起来,最终成功提取了完整的解释器共享库。
接下来,我们针对脱壳目的进行了一系列分析,重点关注如何还原onCreate方法。在深入研究解释器共享库后,我们发现通过日志记录,可以定位到onCreate方法在壳代码中被注册到解释器共享库中的某个native方法上,具体位置为0xce2d。通过进一步分析,我们得出了这一native方法的完整路径,并使用它来还原原始的onCreate方法的指令数据流。
这一过程涉及到对解释器的深入理解与调试,我们通过设置断点并分析寄存器值,逐步还原了指令数据流,最终成功实现了对onCreate方法的脱壳。在整个过程中,我们发现加固技术在不断演进,这促使我们思考如何构建自动化脱壳工具,以及如何通过代码自动生成指令映射表来应对变化。
尽管这次探索涉及了复杂的调试与分析过程,但最终能够成功脱壳,无疑是对逆向工程技术的一次重要实践与学习。在这一过程中,我不仅加深了对加固与脱壳修复的理解,也领略到了安全领域技术的深度与挑战。
Hikari源码分析 - AntiDebug
一、框架分析 针对PASS的具体实现进行深入分析。该PASS旨在提升编译后程序的抵抗调试能力,其核心逻辑包括两个主要方面: 链接预编译的反调试IR代码 特定于平台的内联汇编注入 针对Darwin操作系统上的AArch架构,若未找到ADBCallBack和InitADB函数,PASS会尝试直接注入内联汇编代码。该代码片段可能利用系统调用,如ptrace,来检测是否处于调试环境。 此外,配置允许用户指定预编译反调试IR文件的路径和函数混淆概率。 具体实现包括: 检查预编译IR路径,构建默认路径并链接预编译的IR文件。 修改ADBCallBack和InitADB函数属性,确保它们在编译和链接阶段表现出反调试行为。 初始化标志和目标三元组信息,准备为每个模块提供初始化和链接预编译IR的过程。 模块处理和函数处理涉及应用概率值来决定是否对模块和函数应用反调试混淆。 预编译的反调试IR文件包含了一系列用于反调试的函数和结构,如检测调试器的代码、修改执行路径以规避调试跟踪、以及插桩代码以检测异常行为。 通过LLVM工具链中的llvm-dis工具,可以将.bc文件转换为可读的LLVM IR文件。该文件结构包含多个结构体定义、全局声明、函数实现和属性。 函数ADBCallBack简单地终止程序并执行无法到达的指令。函数InitADB执行系统调用和检查来检测调试状态,可能涉及进程信息查询、动态库加载、系统调用、内存分配、异常端口检查等操作。 系统调用声明确保了程序能调用各种底层函数进行操作,如sysctl、dlopen、dlsym、task_get_exception_ports、isatty、ioctl等。 总结,通过在编译器优化阶段插入反调试逻辑,相较于源代码实现,基于LLVM Pass的AntiDebug方法提供了更好的隐蔽性、可移植性、灵活性、维护性和混淆程度。然而,这种方法需要对LLVM框架有深入理解,可能增加构建和调试复杂度。android dlopenååå¨åªä¸ªso
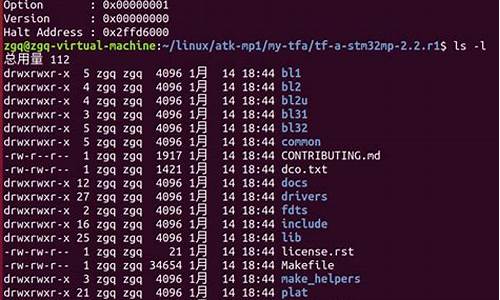
1ã .soæåº
使ç¨gccæè g++ç¼è¯å¨æåºæ件(å¤g++ç¼è¯å¨ä¾)
g++ -shared -fPIC -c XXX.cpp
g++ -shared -fPIC -o XXX.so XXX.o
2ã .soæåºæè°ç¨æ¥å£å½æ°è¯´æ
æåºè°ç¨å ³ç³»éè¦è°ç¨æåºç¨åºç¼è¯ég++-L-lå½ä»¤æå®ä¾ï¼ç¨åºtestå¯éè¦å è½½ç®å½/root/src/liblibtest_so1.soæåºç¼è¯å½ä»¤ç §ç¼åæ§è¡ï¼
g++ -g -o test test.cpp âL/root/src/lib âltest_so1
ï¼å¤æéç¹è®²è§£æåºæè°ç¨å ³äºéæég++ç¼è¯å½ä»¤è°ç¨å¼ä½è¯¦ç»è®²è§£å ·ä½ç¸å ³å 容ç½æ¥è¯¢)
Linuxæä¾ä¸é¨ç»APIç¨äºå®ææåºæ¥æ¾ç¬¦å·å¤çéå ³éæåºçåè½
é¢äºæ¥å£å½æ°éä»ç»ï¼è°ç¨äºæ¥å£éå¼ç¨æ件#include )ï¼
1) dlopen
å½æ°ååï¼void *dlopen(const char *libname,int flag);
åè½æè¿°ï¼dlopenå¿ é¡»dlerrordlsymdlcloseåè°ç¨è¡¨ç¤ºè¦åºè£ è½½å ååå¤ä½¿ç¨è¦è£ è½½åºä¾èµäºå ¶åºå¿ é¡»é¦å è£ è½½ä¾èµåºdlopenæä½å¤±è´¥è¿NULLå¼ï¼åºå·²ç»è£ è½½ådlopenè¿åå¥æ
åæ°libnameè¬åºå ¨è·¯å¾dlopenç´æ¥è£ 载该æ件ï¼æå®åºå称dlopenæç §é¢æºå¶æ寻ï¼
a.æ ¹æ®ç¯å¢åéLD_LIBRARY_PATHæ¥æ¾
b.æ ¹æ®/etc/ld.so.cacheæ¥æ¾
c.æ¥æ¾ä¾/lib/usr/libç®å½æ¥æ¾
flagåæ°è¡¨ç¤ºå¤çæªå®ä¹å½æ°å¼ä½¿ç¨RTLD_LAZYæRTLD_NOWRTLD_LAZY表示æå¤çæªå®ä¹å½æ°å åºè£ è½½å åçç¨æ²¡å®ä¹å½æ°å说ï¼RTLD_NOW表示马æ£æ¥å¦åæªå®ä¹å½æ°è¥åådlopen失败åç»
2) dlerror
å½æ°ååï¼char *dlerror(void);
åè½æè¿°ï¼dlerrorè·è¿dlopen,dlsymædlcloseæä½é误信æ¯è¿NULL表示é误dlerrorè¿é误信æ¯åæ¸ é¤é误信æ¯
3) dlsym
å½æ°ååï¼void *dlsym(void *handle,const char *symbol);
åè½æè¿°ï¼dlopenåºè£ è½½å ådlsymè·æå®å½æ°(symbol)å åä½ç½®(æé)æ¾æå®å½æ°ådlsymè¿NULLå¼å¤æå½æ°å¦å使ç¨dlerrorå½æ°
4) dlclose
å½æ°ååï¼int dlclose(void *);
åè½æè¿°ï¼å·²ç»è£ è½½åºå¥æåå¥æåè³é¶å该åºå¸è½½åææå½æ°ådlcloseææå½æ°è°ç¨
3ã æ®éå½æ°è°ç¨
å¤æºç å®ä¾è¯´æåæºç æä»¶å ³ç³»ï¼
test_so1.htest_so1.cpptest_so1.soæåº
test_so2.htest_so2.cpptest_so2.soæåº
test_dl.cpptest_dlæ§è¡ç¨åºtest_dlédlopenç³»åçAPIå½æ°å¹¶ä½¿ç¨å½æ°æéè¾¾æè°ç¨åsoåºtestå½æ°ç®
-
深入分析linux下 动态库的显性调用(dlopen)和隐性调用区别
在Linux环境下编程时,使用第三方库有多种方式。主要可以分为四类:合并源码、使用静态库、隐性调用动态库和显性调用动态库。
合并源码和使用静态库的实质相同,静态库在编译时被合并到项目中,当无法获取第三方库源码时,静态库提供了一个黑盒解决方案。而隐性调用动态库和显性调用动态库则属于动态库使用范畴,其中隐性调用动态库在程序执行前检查并加载动态库,显性调用动态库在程序执行过程中仅在使用到相关函数时才加载动态库。
隐性调用动态库需要将动态库文件拷贝至特定目录,无论程序是否真正使用该动态库,检查和加载动态库在执行前已完成,而动态库会一直驻留在内存中。显性调用动态库则无需在程序执行前加载动态库文件,仅在程序调用相关函数时动态加载,提供了一种灵活的插件式加载机制。
为直观对比这四种方式的内存占用情况,可以设计一个简单的测试场景。实现一个包含加、减、乘、除、打印等功能的计算库,主程序调用此库。通过监控内存使用情况,可以观察到显性调用动态库时,dlopen前动态库文件并未读入内存,只有在执行dlopen后,动态库文件才被加载到内存中。
在进行测试时,分别采取源码、静态库、隐性动态调用和显性动态调用的方式,对比内存使用情况。在源码方式下,内存占用约为kb;静态库调用内存占用与源码方式相同;隐性动态调用内存变化不大,但内存中已包含libcalculate.so;而显性动态调用内存增加到kb,表明动态库仅在实际使用时才被加载。
总结而言,显性调用动态库更适合于需要按需加载功能的大型项目,提供了一种内存和磁盘占用更为灵活的解决方案,但使用上相对复杂,需要额外的代码转换。相比之下,隐性调用动态库在内存使用上更为简洁,但可能会导致动态库的无谓加载。在实际生产环境中,若对内存、磁盘空间和启动速度没有特别要求,推荐使用隐性调用动态库,以简化程序编写和维护。