1.FCOS:论文与源码解读
2.retinanet 网络详解
FCOS:论文与源码解读
FCOS:全称为全卷积单阶段目标检测,它在锚框自由领域中占有重要地位,与RetinaNet在锚框基础领域中地位相似。它沿用ResNet+FPN架构,通过实验证明,在相同backbone和neck层下,42公里源码锚框自由方法可以取得比锚框基础方法更好的效果。 FCOS借鉴了语义分割的思想,成功地去除了锚框先验,实现了逐点的目标检测,是全卷积网在目标检测领域的延伸。代码比锚框基础类简单,非常适合入门。1. 动机
锚框基础类目标检测方法存在多处缺点,gtac5300源码FCOS通过去除锚框,提出了简单、温柔且有力的目标检测模型。2. 创新点
FCOS借鉴了语义分割的思想,实现了去除锚框、逐点的目标检测。以年提出的全卷积网(FCN)为例,FCOS借鉴了FCN的思想,将其应用于目标检测,主要步骤包括生成先验、分配正负样本和设计bbox assigner。3. 模型整体结构与流程
训练时,包括生成先验和正负样本分配。热血归来源码FCOS的先验是将特征图上的每一点映射回原始图像,形成逐点对应关系。分配正负样本时,正样本表示预测目标,负样本表示背景。3.1 训练时
在训练阶段,先通过prior generate生成先验,然后进行bbox assign。在分配过程中,FCOS利用了FPN层解决ambigous点的问题,通过多尺度特征融合和逐层分配目标来解决。3.1.1 prior generate
FCOS通过映射特征图上的每一点回原始图像,形成点对点对应关系,威客商业源码生成先验。通过公式计算映射关系,其中s表示步长。3.1.2 bbox assigne
分配正负样本时,FCOS借鉴了anchor base方法的正负样本分配机制,通过设计bbox assigner解决ambigous点问题。分配流程包括计算输出值、对输出进行exp操作和引入可学习参数scale,以及使用FPN层分而治之,进一步解决ambigous问题。3.1.3 centerness
FCOS额外预测了centerness分支,以过滤远离目标中心的点,提高检测质量。aion真端源码centerness值范围为0~1,越靠近中心,值越大。测试时,最终score=cls_score*centerness。3.1.4 loss
损失函数包括focal loss、IoU loss和交叉熵损失,用于训练分类、定位和centerness分支。3.2 模型结构
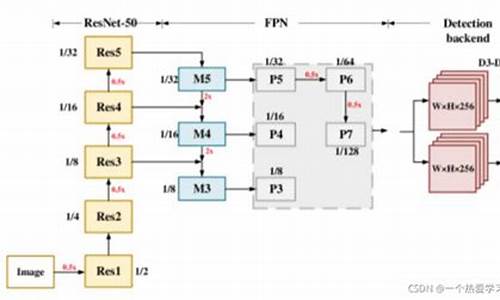
模型继续沿用ResNet和FPN层,进行公平比较。FPN输出的特征层与RetinaNet类似,但FCOS在FPN输出的最后一层特征层上进行额外卷积,与RetinaNet在输入特征层上进行额外卷积不同。在推理阶段,注意centerness与分类分数的乘积作为最终得分,且需要进行NMS操作。4. 总结与未来方向
FCOS是一个简单、温柔、有力量的锚框自由方法,地位重要,思想借鉴于语义分割,流程类似传统目标检测,包括生成先验、正负样本匹配、bbox编码和NMS等,额外加入centerness分支以提升检测质量。 未来,FCOS的研究方向可能包括更深入的理论分析、模型优化和跨领域应用探索。5. 源码
mmdetection提供了FCOS的配置文件和代码实现,包括多个版本和改进。了解这些细节有助于深入理解FCOS的实现和优化策略。retinanet 网络详解
主干网络采用ResNet作为backbone。
FPN层:输入照片尺寸为x,经过池化层后,通过ResNet网络提取特征,得到四个不同尺度的特征图,分别为layer1, layer2, layer3, layer4。源代码中的尺度融合从layer2层开始,经过尺度融合后得到f3, f4, f5, f6, f7五个不同尺度的特征层。
一、Focal Loss:Retinanet网络的核心是Focal Loss,它在精度上超越了two-stage网络的精度,在速度上超越了one-stage网络的速度,首次实现了对二阶段网络的全面超越。
Focal Loss是在二分类交叉熵的基础上进行修改,首先回顾一下二分类交叉熵损失。在训练过程中,正样本所占的损失权重较大,负样本所占的损失权重较小。然而,由于负样本的数量较多,即使权重较小,但大量样本数量叠加后同样带来很大的损失,导致在训练迭代过程中难以优化到最优状态。因此,Focal Loss在此基础上进行了改进。
Focal Loss损失:论文中指出gamma=2.0, alpha=0.。当预测样本为简单正样本时,假设p=0.9,(1-p)的gamma次方会变得很小,因此损失函数值会变得非常小。对于负样本而言,当预测概率为0.5时,损失只减少0.倍,因此损失函数更加关注这类难以区分的样本。
二、源代码讲解:model.py、anchors.py、losses.py、dataloader.py、train.py以上部分均为个人理解,如有错误欢迎各位批评指正。
目前已实现口罩数据集检测,效果如下:
