
1.kafka源码阅读之MacBook Pro M1搭建Kafka2.7版本源码运行环境
2.NameServer 核心原理解析
3.浅析源码 golang kafka sarama包(一)如何生产消息以及通过docker部署kafka集群with kraft
kafka源码阅读之MacBook Pro M1搭建Kafka2.7版本源码运行环境
在探索Kafka源码的过程中,决定搭建本地环境进行实际运行,以辅助理解和注释。由于日常开发中常使用Kafka 2.7版本,选择了在MacBook Pro M1笔记本上搭建此版本的源码环境。搭建过程中,货到付款下单源码记录了遇到的障碍,方便未来再次搭建时不必从头开始。 搭建Kafka 2.7源码环境需要准备以下基础环境:一、Zulu JDK1.8
在MacBook Pro M1笔记本上,基本都已安装JDK,版本不同而已。使用的是Zulu JDK1.8版本,通过下载.dmg格式的一键安装,环境自动配置,鼠标宏源码制作安装路径通常在 /Library/Java/JavaVirtualMachines。二、Scala 2..1
并未在系统里安装Scala,而是直接利用IDEA。按照Preferences -> Plugins -> Scala安装。选择IDEA的不同Scala JDK版本。三、安装Gradle6.6
通过官网gradle.org/releases/下载Gradle6.6版本。如国内下载速度较慢,可直接从百度网盘下载安装包。安装完成后,解压并放置在目录/Users/helloword/software/gradle-6.6,通过mac终端执行指令配置环境。四、影视返利app源码Zookeeper3.4.6安装
直接从百度网盘下载zookeeper-3.4.6.tar.gz包,解压后放置在三台机器的/app目录下。在每个目录中创建data子目录,并建立myid文件,按照特定数字填写。在zoo.cfg文件中进行配置并复制至其他机器。五、Kafka2.7源码部署
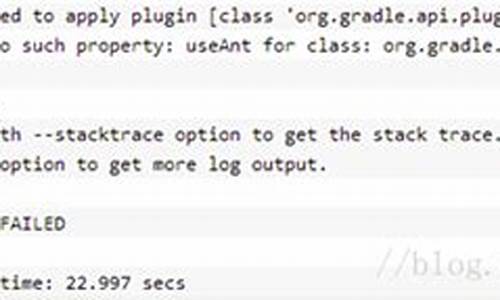
从官网下载Kafka 2.7源码,或从百度网盘获取。解压至目录/Users/helloword/software/kafka/kafka-2.7.0-src,并通过Gradle构建环境。在mac终端执行指令,生成gradle-wrapper.jar,配置依赖。破解可以看到源码将源码导入IDEA,加载Gradle构建的项目。六、源码运行
确保源码运行打印日志,需将log4j.properties复制到core的 resources目录,并在build.gradle中添加log4配置。修改config/server.properties配置,包括zookeeper路径和broker的ip。配置server、consumer、producer三个进程,确保Kafka服务、消费者和生产者能够正常工作。 整个Kafka 2.7版本源码的游资潜伏公式源码本地搭建步骤完成。后续计划撰写系列文章总结阅读源码的经验。关注公众号写代码的朱季谦,获取更多分类归纳的博客。NameServer 核心原理解析
NameServer,通常被称为注册中心,是RocketMQ架构中一个关键但常被忽视的组件。它在集群背后起着类似Zookeeper在Kafka中的作用,支持Broker、Producer和Consumer的正常协作。
在日常操作中,我们主要与Producer和Consumer交互,NameServer则作为幕后支持者。Broker启动时,会将自己的信息,如IP、端口以及存储的Topic路由信息(指明每个MessageQueue所在的Broker)通过心跳发送到NameServer。Producer则依赖NameServer获取元数据,将消息发送到正确的Broker。而Consumer通过NameServer获取消费配置,如Topic和Consumer Group,从而获取Broker的地址信息,开始消费消息。
接下来,我们通过注册Broker的源码来理解NameServer的工作。首先,NameServer会验证Broker发送的数据完整性,接着处理Body,如重置DataVersion或解析配置信息。核心的注册逻辑会维护集群中Broker的Name及其对应的地址信息,确保数据一致性。同时,它还会维护每个Broker的地址,区分主从节点,并处理可能的重复地址。此外,NameServer还会维护MessageQueue的数据,包括创建、更新和维护Broker与MessageQueue的映射关系。
NameServer的启动流程涉及定期扫描并更新活跃Broker列表,以及移除长时间无心跳的Broker。虽然文章仅展示了注册Broker的流程,但NameServer实际上支持更多操作,如查询、删除等,这些操作的源码都与注册操作紧密相关。
本文已为您全面解析了NameServer的核心原理,若对其他内容感兴趣,欢迎您通过微信搜索关注SH的全栈笔记获取更多帮助。感谢您的支持,点赞关注和分享是对我们最大的鼓励。
浅析源码 golang kafka sarama包(一)如何生产消息以及通过docker部署kafka集群with kraft
本文将深入探讨Golang中使用sarama包进行Kafka消息生产的过程,以及如何通过Docker部署Kafka集群采用Kraft模式。首先,我们关注数据的生产部分。
在部署Kafka集群时,我们将选择Kraft而非Zookeeper,通过docker-compose实现。集群中,理解LISTENERS的含义至关重要,主要有几个类型:
Sarama在每个topic和partition下,会为数据传输创建独立的goroutine。生产者操作的起点是创建简单生产者的方法,接着维护局部处理器并根据topic创建topicProducer。
在newBrokerProducer中,run()方法和bridge的匿名函数是关键。它们反映了goroutine间的巧妙桥接,通过channel在不同线程间传递信息,体现了goroutine使用的精髓。
真正发送消息的过程发生在AsyncProduce方法中,这是数据在三层协程中传输的环节,虽然深度适中,但需要仔细理解。
sarama的架构清晰,但数据传输的核心操作隐藏在第三层goroutine中。输出变量的使用也有讲究:当output = p.bridge,它作为连接内外协程的桥梁;output = nil则关闭channel,output = bridge时允许写入。
2025-01-19 11:32387人浏览
2025-01-19 10:58941人浏览
2025-01-19 10:311809人浏览
2025-01-19 10:251136人浏览
2025-01-19 10:182590人浏览
2025-01-19 09:5555人浏览
10月23日,以軍對黎巴嫩南部城市提爾發動了數次空襲,並繼續襲擊首都貝魯特南郊等地。黎巴嫩真主黨表示對以色列特拉維夫發動了襲擊,在黎以臨時邊界黎方一側的多個地點對以軍部隊進行打擊。黎南部多地遭以軍襲擊
1.DNF易语言自定义源码写法。2.dnf自动刷图脚本封号吗DNF易语言自定义源码写法。 .版本 2 .子程序 自定义攻击, , 公开 .参数 人物基址, 整数型 .参数 X轴距离,

