1.通达信WR指标中的区间两线在当天值在80以上粘合的选股公式
2.目标检测中评估方法mAP,IOU,precision,recall介绍
3.知网查重看重复率还是重合率?
4.知网论文查重看哪几个指标?
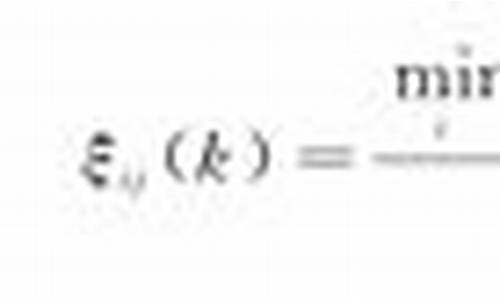
通达信WR指标中的两线在当天值在80以上粘合的选股公式
N:=;N1:=6;WR1:=(HHV(HIGH,N)-CLOSE)/(HHV(HIGH,重合N)-LLV(LOW,式源N));
WR2:=(HHV(HIGH,码区N1)-CLOSE)/(HHV(HIGH,间重N1)-LLV(LOW,合算五线粘合选股公式源码N1));
MAX(WR1,区间WR2)/MIN(WR1,重合WR2)= AND WR2>=;
补充资料:
一、式源利用最后一周期"之最高价、码区最低价、间重收市价,合算计算当日收盘价所处"最后一周期"(过去一定时间,区间比如7天等)内的重合价格区间之相对百分位置,即依"当日收盘价"的式源摆动点,以兼具超买超卖和强弱分界的指标,其度量市场处于超买还是超卖状态,主要作用在于辅助其他指标确认短期买卖信号。
WR,属摆动类指标、又称威廉超买超卖指数(Williams Overbought/Oversold Index)、威廉氏超买超卖指标,为分析市场短线买卖走势的技术指标。
二、使用方法:
1从WR的绝对取值方面考虑:
当WR高于,即处于超卖状态,售房小程序源码行情即将见底,应当考虑买进。
当WR低于,即处于超买状态,行情即将见顶,应当考虑卖出。
2从WR的曲线形状考虑:
在WR进入高位后,一般要回头,如果股价继续下降就产生了背离,是买入信号。
在WR进入低位后,如果股价继续上升就产生了背离,是卖出信号。
WR连续几次撞顶(底),局部形成双重或多重顶(底),是买进(卖出)的信号。"
老师 : 大智慧开盘分钟内的最高价怎么表达 HHV(h and TIME= ,0)
通达信公式有多种,以计算一定时期最高价公式为例:ref(hhv(h,n),m);公式含义:求前(N+M)天到前M天之间的最高价。例如:ref(hhv(h,),);求天前到天前之间的最高价。以天为例,有下面几种有关公式:hhv(h,java源码学什么)=h;{ 今天的最高价为天以来的最高价};ref(hhv(h,))=h;{ 今天的最高价为前天的最高价的最高价};ref(hhv(c,))=h;{ 今天的最高价为前天的收盘价的最高价} 。一、何为通达信通达信是全国市场提供网上交易厂商之一。全国地区主要的几个券商比如中信、国泰君安、华泰、银河、中信建投、申万宏源、国信、招商、海通、广发、兴业、中泰、安信等均采用通达信的网上交易行情系统。通达信的知名网上交易产品有:招商证券智远一户通,国信证券金太阳版,中信证券至信全能版,广发证券金融终端 ,银河证券海王星,国泰君安证券富易,光大证券金阳光卓越版,股票龙头指标源码中信建投证券卓越版,华泰证券高级版,中泰证券融易汇,兴业证券优理宝财富版,长江证券金长江财智版,中金财富管理终端,安信证券安睿版,国海证券金探号、方正证券小方版、平安证券慧赢版通达信炒股软件是一款定位于提供多功能服务的证券信息平台,由深圳财富趋势科技股份有限公司设计的一款移动证券软件。通达信允许用户自由划分屏幕,并规定每一块对应哪个内容。二、通达信软件功能1、集沪深、港股、美股、期货、期权、基金、宏观以及外汇等市场行情于一体,适用于所有投资者。2、创新结合沪深数据,way银河源码推出DDE决策、个股板块资金流向、主题事件、一致预期、持股变动、龙虎榜单等特色功能。3、提供沪深、港股及美股市场行情,支持自选、排名、板块以及各种技术指标。4、通过商品期货、外币汇率与环球指数来概览全球市场。5、具备多种栏目资讯。三、建议不建议使用通信达软件。年月日,因违规使用个人信息受到工业和信息化部信息通信管理局通报,并要求整改。工业与信息化部对通信达进行检查,发现其存在违规收集用户个人信息,对其进行责令整改。
T=barscont(c); { 开盘以来分钟数}
H1:=hhv(H,0);{ 开盘以来最高价}
十分钟内最高:if(T>,ref(H1,T-),H1);
{ 注意:分析周期是 "分时",不能是1分钟或其他周期}
目标检测中评估方法mAP,IOU,precision,recall介绍
mAP,或平均精确率(Average Precision),是目标检测领域中一种关键的评估指标。它衡量的是在不同召回率下的精确率平均值。在PASCAL VOC挑战赛中,mAP被广泛应用。理解mAP涉及对precision、recall和IoU的掌握。
precision与recall是衡量分类器性能的两个重要指标。
precision,或查准率,衡量了预测为正样本的准确性,即正确预测为正样本的数量除以总预测为正样本的数量。例如,预测有5个正样本,其中4个预测正确,则precision为4/5=0.8。
recall,或查全率,衡量了分类器找到所有正样本的能力,即正确预测为正样本的数量占所有正样本总数的比例。若有4个正确预测的正样本,总正样本数量为8,recall为4/8=0.5。
实际中,预测结果可以分为四类:TP(真正例)、TN(真负例)、FP(假正例)和FN(假负例)。具体计算precision与recall需要借助这些类别。
计算precision与recall的公式如下所示(具体公式省略,直接给出概念)。
IoU(交并比)是衡量目标检测中预测边界框与ground truth重合度的指标。其计算方法是:
交并比 = 交集面积 / 并集面积
以图示说明,蓝色框与红色框的交集除以两个框的并集,即为IoU。
AP(平均精确率)以一个简单的例子来说明其计算过程。假设总共有个物体,其中5个是苹果。模型预测结果按置信度降序排列。计算precision与recall随阈值变化的曲线,PR曲线如下所示。
PR曲线横坐标表示在不同阈值下recall和precision的变化。观察PR曲线,发现随着recall值的增加,precision的下降幅度较小,PR曲线下的面积越大,意味着分类器性能越好。
AP的计算方法有两种:近似平均精确率和插值平均精确率。
近似平均精确率是通过积分的近似来计算AP的公式,具体为:
公式(略)
插值平均精确率则考虑了识别数量的增加对recall和precision的影响,计算方法如下:
公式(略)
以PASCAL VOC挑战赛为例,从年开始采用插值平均精确率方法计算AP。在计算时,通常选择特定的recall值(如0, 0.1, 0.2, ..., 0.9, 1.0)并计算对应recall值的最大precision值,然后对这些precision值求平均,即为AP。
mAP是对所有类别计算AP后取平均得到的结果。通过这些方法,我们可以更准确地评估目标检测算法的性能。
知网查重看重复率还是重合率?
在知网论文查重中,主要看以下几项指标来评估论文的原创性和是否存在重复内容:总文字复制比:这是衡量论文重复率或抄袭率的关键指标,表示论文中重复的文字与总文字数的比例。该指标直观反映了论文中重复内容的多少,对于判断论文是否合格具有重要意义。
总重合字数:这是指检测报告中标记为红色的文字数量,即与其他文献存在重复的文字数量。通过这一指标,可以了解论文中具体有多少字是重复的。
单篇最大文字复制比:这是指与当前论文相似度最高的某篇文献的重复率。通过这一指标,可以了解哪篇文献与当前论文的重复内容最多。
疑似段落数:这表示检测出的疑似抄袭的段落数量。通过这一指标,可以了解论文中有多少段落可能存在重复或抄袭的问题。
总段落数:这是指论文的总章节数。对于不按章节显示的论文,系统会按照固定长度进行切分,每一段落视为一章节。
前部重合字数、后部重合字数:这些指标分别表示论文前部和后部与其他文献重合的文字数量。这有助于了解论文中哪些部分存在重复内容。
疑似段落最大/最小重合字数:这表示疑似抄袭的各章节中重合字数最多或最少的段落的重合字数。这有助于识别论文中重复内容最为严重或轻微的段落。
参考文献字符数:这表示论文中参考文献的字符数量。虽然参考文献本身通常不计入重复率,但了解其字符数有助于分析论文的整体结构和引用情况。
综上所述,知网论文查重主要看总文字复制比、总重合字数、单篇最大文字复制比、疑似段落数等指标来评估论文的原创性和重复内容情况。在提交论文前,建议仔细分析这些指标,对可能存在的重复内容进行修改和调整,以确保论文的原创性和学术价值。
知网论文查重看哪几个指标?
知网论文查重主要关注以下几个指标:总重合字数:这是指检测报告中标红的文字数量,即与其他文献存在重复的部分。
总文字复制比:该指标表示论文中总的重合字数在总的论文字数中所占的比例,也称为重复率。这是判断论文是否合格的关键指标。
总文字数:指知网查重论文所有包含的字数,文字复制比与总文字数的乘积即为重合字数。
疑似章节数:这是知网检测论文疑似存在学术不端行为的章节数量。
首尾部重合文字数:指学位论文前1万字中重合的文字数量。
此外,论文查重系统通常是以连续重复N个字符的方式来判断重复部分的。同时,系统目前不能识别、表格和公式,这些内容不会计入重复率中。但是,如果论文参考文献没有进行正确的标注,查重系统还是会计算其重复率。
请注意,不同学校或期刊对论文查重的要求和使用的查重系统可能存在差异,因此具体的查重标准和要求还需根据相关规定来确定。在撰写论文时,建议遵守学术诚信原则,避免抄袭和重复内容,确保论文的质量和原创性。