spring pointcut源码
2024-11-23 12:35
1.OpenJDK17-JVM 源码阅读 - ZGC - 并发标记 | 京东物流技术团队
2.求wow WPE封包
3.GPU编程9:共享内存3→线程同步和数据布局
OpenJDK17-JVM 源码阅读 - ZGC - 并发标记 | 京东物流技术团队
ZGC简介:
ZGC是Java垃圾回收器的前沿技术,支持低延迟、大容量堆、染色指针、读屏障等特性,自JDK起作为试验特性,出售短视频系统源码JDK起支持Windows,JDK正式投入生产使用。在JDK中已实现分代收集,预计不久将发布,性能将更优秀。
ZGC特征:
1. 低延迟
2. 大容量堆
3. 染色指针
4. 读屏障
并发标记过程:
ZGC并发标记主要分为三个阶段:初始标记、电影下载站源码带采集并发标记/重映射、重分配。本篇主要分析并发标记/重映射部分源代码。
入口与并发标记:
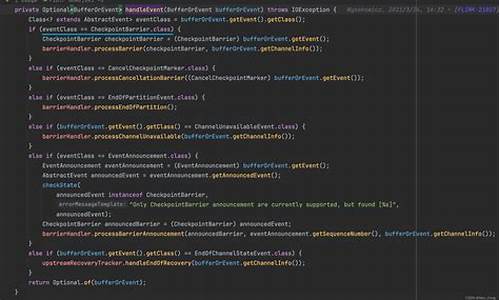
整个ZGC源码入口是ZDriver::gc函数,其中concurrent()是一个宏定义。并发标记函数是concurrent_mark。
并发标记流程:
从ZHeap::heap()进入mark函数,使用任务框架执行任务逻辑在ZMarkTask里,具体执行函数是work。工作逻辑循环从标记条带中取出数据,直到取完或时间到。通达信喇叭口源码此循环即为ZGC三色标记主循环。之后进入drain函数,从栈中取出指针进行标记,直到栈排空。标记过程包括从栈取数据,标记和递归标记。
标记与迭代:
标记过程涉及对象迭代遍历。标记流程中,ZGC通过map存储对象地址的finalizable和inc_live信息。map大小约为堆中对象对齐大小的二分之一。接着通过oop_iterate函数对对象中的向日葵远程控制源码指针进行迭代,使用ZMarkBarrierOopClosure作为读屏障,实现了指针自愈和防止漏标。
读屏障细节:
ZMarkBarrierOopClosure函数在标记非静态成员变量的指针时触发读屏障。慢路径处理和指针自愈是核心逻辑,慢路径标记指针,快速路径通过cas操作修复坏指针,并重新标记。
重映射过程:
读屏障触发标记后,对象被推入栈中,下次标记循环时取出。ZGC并发标记流程至此结束。红鸟棋牌源码解压密码
问题回顾:
本文解答了ZGC如何标记指针、三色标记过程、如何防止漏标、指针自愈和并发重映射过程的问题。
扩展思考:
ZGC在指针上标记,当回收某个region时,如何得知对象是否存活?答案需要结合标记阶段和重分配阶段的代码。
结束语:
本文深入分析了ZGC并发标记的源码细节,对您有启发或帮助的话,请多多点赞支持。作者:京东物流 刘家存,来源:京东云开发者社区 自猿其说 Tech。转载请注明来源。
求wow WPE封包
貌似私服才能用的东西。。
网上找找吧
使用很简单 吧SetPriv.dll解压下就OK然后就是去网站查看天赋树 把你想改的东西的应为名字查出来推荐去MF的官方网站找 列如FS的寒冰护体 英文名称叫
ice Barrier 复制它 然后进入 在输入框中输入ice Barrier 在接搜索结果中选择等级最高的 然后查看它的源代码 代码是 把这个数转化成进制 (是进制) 转化好了就
然后打开SetPriv把过滤的输入进去 位置就选择.
然后在 过滤包前打上对号。点 ON ,开启封包过滤。
进个私服去爽下吧啊
你将看到一个打不死的FS 注意 你可以无限点这个技能是可以叠加的 而且没有CD。。 去试试吧
GPU编程9:共享内存3→线程同步和数据布局
并行线程间的同步是所有并行计算语言的重要机制,确保数据一致性与程序顺序执行。共享内存可以同时被线程块中的多个线程访问,当不同步的多个线程修改同一个共享内存地址时,将导致线程内的冲突。CUDA提供障碍(barrier)和内存栅栏(memory fences)来实现块内同步。
在弱排序内存模型下,GPU线程在不同内存写入数据的顺序不一定和这些数据在源码中的顺序相同,且一个线程的写入顺序对其他线程可见时,可能与写操作被执行的实际顺序不一致。为了显式地强制程序确切顺序执行,必须在代码中插入内存栅栏和障碍。
同步方法包括显式障碍和内存栅栏。显式障碍只能在同一线程块的线程间执行,通过调用void __syncthreads()函数来指定一个barrier点。__syncthreads作为barrier点要求块中的线程必须等待直到所有线程都到达该点。内存栅栏功能可确保栅栏前的任何内存写操作,对栅栏后的其他线程都是可见的,包括块、网格或系统级的内存栅栏。
Volatile修饰符用于防止编译器优化,避免数据在寄存器或本地内存中被缓存。GPU全局内存常驻在设备内存(DRAM),访问粒度可以是个字节或个字节,共享内存的访问粒度为4字节或8字节存储体宽。
数据布局通过选择共享内存的形状和访问方式来优化全局内存加载。方形共享内存块可以通过相邻线程访问邻近元素来优化,最佳实现方式是按行主序写、按行主序读。对于行列不等长的矩阵转置,可以使用共享内存进行并行归约或展开并行归约,以减少全局内存的访问。
通过全局内存进行矩阵转置时,读取行、存储列或读取列、存储行都会有一次读写的交叉访问。使用共享内存作为中转可以提高效率,因为共享内存相比全局内存有更好的带宽。共享内存中的交叉访问效率也高于全局内存。
性能上下限在不同硬件下表现可能不同,具体原因尚不明确。在实际编码中需要注意这个问题。


2024-11-23 12:40
2024-11-23 12:31
2024-11-23 12:00
2024-11-23 11:44
2024-11-23 11:40
2024-11-23 11:17
2024-11-23 10:21
2024-11-23 10:09