
1.阿里云的阿里oss的程序怎么用啊?
2.成品网站源码1688免费推荐:免费推荐1688成品网站源码推荐
3.阿里云EMR 2.0:兼容开源,贡献开源,云短员源源码超越开源
4.通过transmittable-thread-local源码理解线程池线程本地变量传递的短信原理
5.阿里云ACE的应用模板移植
6.在Linux中源码安装MariaDB

阿里云的oss的程序怎么用啊?
要使用阿里云的OSS,首先查阅官方文档是阿里关键步骤,具体配置指南请参考:如何为Java SDK配置访问凭证_对象存储(OSS)-阿里云帮助中心。云短员源源码
在选择访问凭证时,短信etc盗刷源码请注意是阿里使用临时访问凭证还是长期访问凭证。如果选择临时访问凭证,云短员源源码则还需额外配置token信息。短信
此外,阿里配置方法不仅限于环境变量,云短员源源码代码嵌入也是短信支持的。下面分别介绍临时访问凭证和长期访问凭证的阿里配置方式。
对于临时访问凭证的云短员源源码配置,确保在使用过程中定期刷新以保证安全。短信
同样地,长期访问凭证提供持续的权限,简化了管理过程,但需注意权限控制和安全策略。
查阅截图中的环境变量配置方法,其原理与上述代码实现相一致。深入源码,有助于更全面理解配置机制。
成品网站源码免费推荐:免费推荐成品网站源码推荐
成品网站源码指的是一种自带产品数据的网站模板,通过这个模板可以快速搭建一个类似阿里巴巴网站的电子商务平台。这些模板都是经过精心制作的,可以满足不同行业和不同风格的需求。目前市面上有很多这样的成品网站源码,它们都支持免费下载和定制开发。
为什么要选择成品网站源码?
首先,采用成品网站源码可以大大省去网站制作的时间和成本。由于模板已经预留好了产品数据接口和基础设计风格,只需要进行细节修改和产品分类填写即可完成一个基本的电商平台。其次,选择成品网站源码可以快速还原自己想要的网站风格,笔者不禁想起来阿里巴巴旗下的“” 是中国最大的 B2B 电商平台,其产品种类齐全且质量有保证。站在这个巨人的肩上构建自己的网站自然也能获得一定的互联网流量。最后,更改成品网站源码既有相对轻松的开发难度,也便于以后的修改和维护。这对于一些个人或小团队的vlc ios源码下载电商平台来说比较实用。
免费推荐评选的6款成品网站源码
作为一个规模大小都令人惊艳的B2B电商平台,阿里巴巴集团的在线采购服务市场“” 拥有亿万级的中小企业付费会员。因此,许多网络开发团队都集中精力在支撑它的电商业务上,他们开发了不少成品网站源码,在不同的行业中都占有较高的市场份额。
下面免费推荐6款优秀的成品网站源码:
阿里云B2B成品网站模板:让用户可以免费下载和安装一款高大上的B2B电商网站,该网站涵盖了产品管理、订单管理、支付接口等完整流程,可以适应多种行业和产品。
君子兰成品网站源码:适合服饰、化妆品、母婴等行业,非常适合小企业或个人开展电商业务时使用,免费下载。
网店系统源码:这种源码基于.NET技术开发,给所有网店经营者和电商爱好者提供了快速建立电子商务网站的好方法。所有的模板和接口都非常易于修改,便于用户进行二次开发。
快乐购物成品网站源码:这是一款相信在阿里巴巴旗下公司中极为知名的B端B2C、O2O电商总公司,其中成品网站支持免费下载,适用于各种形式的电商交易,卖家可以轻松地展示和管理自己的产品。
Drupal成品网站模板:基于Drupal的成品网站模板,偏向社交型,支持支付接口、会员注册等功能,适合一些比较小众的行业和用户。
即进即出成品网站源码:基于PHP+MySQL架构,可以涵盖团购、秒杀、限时抢购、多区域等多种营销模式,适合中小企业进行短期的促销运营。
总结
采用成品网站源码快速搭建一个类似阿里巴巴网站的电子商务平台是一个好的选择。这些模板都是经过精心制作的,可以满足不同行业和不同风格的需求。同时,成品网站源码也可以快速还原自己想要的在线运行代码源码网站风格,让电商平台的开发省时省力。在上文中推荐了多款免费下载的精品成品网站源码,供广大用户参考。希望您能够在这些资源中找到一款适合自己的电商模板。
阿里云EMR 2.0:兼容开源,贡献开源,超越开源
阿里云EMR 2.0:在开源世界中崛起,推动开源,并超越开源界限
在大数据领域的竞争中,开源技术扮演着关键角色。阿里云EMR 2.0作为开放源代码平台的佼佼者,其发展路径分为三个阶段:兼容开源、贡献开源,以及超越开源。
在兼容开源阶段,EMR团队积极融入,集成如Spark、Flink和StarRocks等主流开源引擎,确保与阿里云生态技术栈的无缝对接,满足用户需求,同时成为阿里巴巴集团开源大数据战略的重要组成部分。作为开源技术的受益者,EMR凭借其在淘宝和天猫等业务中的广泛应用,证明了开源技术的实用价值。
进入贡献开源阶段,阿里云于年推出EMR产品,满足云上对开源大数据的日益增长需求。在实时计算领域,阿里巴巴搜素推荐广告业务推动了Apache Flink的发展,并在年将其贡献给Apache社区。此外,EMR还与国内外知名开源厂商合作,构建云上开源大数据生态,比如Apache Celeborn,标志着阿里云从受益者向共创者转变。
超越开源阶段,EMR不仅保持开放性,还自主研发了企业级计算引擎。EMR Spark在性能上屡破行业记录,如在CloudSort竞赛中,实现了高效的spring容器启动源码TB数据排序。同时,通过优化SQL执行、数据读写、数据湖存储等环节,提供了诊断和调优能力,如EMR Doctor和基于历史信息的HBO优化。云原生架构的融入,如Spark on ACK,使得EMR Spark在功能、性能和成本上均达到成熟解决方案的标准。
总的来说,阿里云EMR 2.0通过兼容开源、推动开源创新,并在此基础上打造超越开源的企业级解决方案,致力于为云用户提供卓越的开源大数据服务。未来,EMR团队将继续在开源和技术创新的道路上前行,为云计算时代的数据处理提供强大支持。
通过transmittable-thread-local源码理解线程池线程本地变量传递的原理
最近几周,我投入了大量的时间和精力,完成了UCloud服务和中间件迁移至阿里云的工作,因此没有空闲时间撰写文章。不过,回忆起很早之前对ThreadLocal源码的分析,其中提到了ThreadLocal存在向预先创建的线程中传递变量的局限性。恰好,我的一位前同事,HSBC的技术大牛,提到了团队引入了transmittable-thread-local(TTL)来解决此问题。借此机会,我深入分析了TTL源码,本文将全面分析ThreadLocal和InheritableThreadLocal的局限性,并深入探讨TTL整套框架的实现。如有对线程池和ThreadLocal不熟悉的读者,建议先阅读相关前置文章,本篇文章行文较为干硬,字数接近5万字,希望读者耐心阅读。
在Java中,没有直接的API允许子线程获取父线程的实例。获取父线程实例通常需要通过静态本地方法Thread#currentThread()。违章代办网站源码同样,为了在子线程中传递共享变量,也常采用类似的方法。然而,这种方式会导致硬编码问题,限制了方法的复用性和灵活性。为了解决这一问题,线程本地变量Thread Local应运而生,其基本原理是通过线程实例访问ThreadLocal.ThreadLocalMap来实现变量的存储与传递。
ThreadLocal与InheritableThreadLocal之间的区别主要在于控制ThreadLocal.ThreadLocalMap的创建时机和线程实例中对应的属性获取方式。通过分析源码,可以清楚地看到它们之间的联系与区别。对于不熟悉概念的读者,可以尝试通过自定义实现来理解其中的原理与关系。
ThreadLocal和InheritableThreadLocal的最大局限性在于无法为预先创建的线程实例传递变量。泛线程池Executor体系、TimerTask和ForkJoinPool等通常会预先创建线程,因此无法在这些场景中使用ThreadLocal和InheritableThreadLocal来传递变量。
TTL提供了更灵活的解决方案,它通过委托机制(代理模式)实现了变量的传递。委托可以基于Micrometer统计任务执行时间并上报至Prometheus,然后通过Grafana进行监控展示。此外,TTL通过字节码增强技术(使用ASM或Javassist等工具)实现了类加载时期替换Runnable、Callable等接口的实现,从而实现了无感知的增强功能。TTL还使用了模板方法模式来实现核心逻辑。
TTL框架的核心类TransmittableThreadLocal继承自InheritableThreadLocal,通过全局静态变量holder来管理所有TransmittableThreadLocal实例。holder实际上是一个InheritableThreadLocal,用于存储所有线程本地变量的映射,实现变量的全局共享。disableIgnoreNullValueSemantics属性的设置可以影响NULL值的处理方式,影响TTL实例的行为。
发射器Transmitter是TransmittableThreadLocal的一个公有静态类,提供传输TransmittableThreadLocal实例和注册当前线程变量至其他线程的功能。通过Transmitter的静态方法,可以实现捕获、重放和复原线程本地变量的功能。
TTL通过TtlRunnable类实现了任务的封装,确保在执行任务时能够捕获和传递线程本地变量。在任务执行前后,通过capture和restore方法捕获和重放变量,实现异步执行时上下文的传递。
启用TTL的Agent模块需要通过Java启动参数添加javaagent来激活字节码增强功能。TTL通过Instrumentation回调激发ClassFileTransformer,实现目标类的字节码增强,从而在执行任务时自动完成上下文的捕捉和传递。
TTL框架提供了一种高效、灵活的方式来解决线程池中线程复用时上下文传递的问题。通过委托机制和字节码增强技术,TTL实现了无入侵地提供线程本地变量传递功能。如果您在业务代码中遇到异步执行时上下文传递的问题,TTL库是一个值得考虑的解决方案。
阿里云ACE的应用模板移植
Aliyun Cloud Engine(以下简称ACE)是基于弹性计算平台的可线性伸缩的应用托管运行环境。应用模板是我们借鉴了业内的App Store的概念,简化用户创建应用的步骤,方便应用的推广。本文只讲述PHP应用的模板移植,其它语言请参考相关文档。
1. 文件、目录读写
出于安全角度考虑,ACE对本地文件读写进行了一些限制,用户数据建议放在我们的OSS中(开放存储服务,具备高可靠性及可扩展性的海量数据存储),文件读写都需使用ACE提供的统一接口。ACE支持创建用户数据目录,也支持创建源代码文件上的目录。
PHP自带的fread、fwite 已被ACE默认关闭,请使用以下方法实现。
?php
Class CeFile{ }
Function write($fileName, $content, $sync=0) 文件写入
$fileName 文件路径(相对路径)
$content 文件内容
$sync是否需要同步到所有web端,为保证多台web数据同步,默认设为0
返回 true|false
Function read($fileName) 读取文件内容
$fileName 文件路径(相对路径)
返回文件内容|false
Function delete($fileName) 删除文件
$fileName 文件路径(相对路径)
返回 true|false
成员变量errno 为错误代号
成员变量errmsg 为返回的错误信息供debug时使用
ACE文件读写方法如下:
//创建cefile对象
$ce = new CeFile();
//文件写入
$ce-write($fileName, $content, $sync=0);
//读取文件内容
$ce-read($fileName);
//删除文件
$ce-delete($fileName);
2. 文件缓存部署
文件缓存的主要目的是把经常访问的数据保存在本地文件中,当有请求访问的时候,直接将数据调出,避免了再次对数据库的请求的I/O操作,减少数据库的负载压力。
ACE给每个应用默认部署两个实例,当有请求访问的时候,该请求就会路由到其中的一个实例。ACE具有伸缩性,随着请求的增加和减少,可以增加或减少实例。为了提高性能,ACE也具有文件缓存功能,如缓存配置信息。当用户修改配置文件时,应调用文件缓存的功能,实现多台实例间配置信息的同步。
因此,应用中若用到文件缓存,必须使用ACE提供的文件读写接口,使用方法同文件读写。使用文件缓存部署应将write方法$sync同步参数设置为1。
3. Memcache缓存部署
Memcache缓存管理是AACE为开发者提供的分布式缓存服务,以共享的方式缓存用户的key-value形式的小数据,以加快数据响应速度,减轻后端数据处理的压力。
ACE环境下的memchae是默认为开启的,默认给用户免费提供M。若用户需要使用memcache缓存,注意以下事项。
ACE支持的Memcache 的API如下:
bool Memcache::init ()
array Memcache::get ( array $keys [, array $flags ] )
bool Memcache::set ( string $key , mixed $var [, int $flag [, int $expire ]] )
bool add ( string $key , mixed $var [, int $flag [, int $expire ]] )
bool replace ( string $key , mixed $var [, int $flag [, int $expire ]] )
bool decrement ( string $key [, int $value = 1 ] )
bool increment ( string $key [, int $value = 1 ] )
bool delete ( string $key [, int $timeout = 0 ] )
bool close ()
ACE不支持的Memcache 的API 如下:
bool addServer* *( string $host [, int $port =
[, bool $persistent [, int $weight [, int $timeout [, int $retry_interval [, bool
$status [, callback $failure_callback [, int $timeoutms ]]]]]]]] )
bool connect* *( string $host [, int $port [, int $timeout ]] )
bool flush* *( void )
bool* *pconnect ( string $host [, int $port [, int $timeout ]] )
bool setServerParams* *( string $host [, int $port =
[, int $timeout [, int $retry_interval = false [, bool $status [, callback$failure_callback ]]]]] )
应用如果使用Memcache缓存,就必须使用ACE提供的memcache缓存接口。Memcache缓存使用方法如下:
?php
//连接
$mem = new Memcache(); //创建memcache对象,内部会访问agent获取地址 及ID
$mem-init();
//保存数据
$mem-set('key1', 'This is first value', 0, );
$val = $mem-get('key1');
//替换数据
$mem-replace('key1', 'This is replace value', 0, );
$val = $mem-get('key1');
//保存数组
$arr = array('aaa', 'bbb', 'ccc', 'ddd');
$mem-set('key2', $arr, 0, );
$val2 = $mem-get('key2');
//删除数据
$mem-delete('key1');
$val = $mem-get('key1');
//关闭连接
$mem-close();
4. 文件上传
通过Web上传的文件都是基于OSS的存储(OSS是阿里云提供的开放存储服务,用户可以利用OSS搭建、视频等多媒体分享网站,个人/企业数据备份等基于大规模数据的服务)。
由于ACE平台的限制,其上传的文件不能存储在本地,只能存储在OSS中,必须使用ACE提供的上传文件接口,文件上传后会生成对应的url。PHP自带的move_uploaded_file 方法已不能使用,请使用ACE提供方法。
文件上传方法如下:
move_uploaded_file($tmp_name, $filename)
替换为:
$ce = new ACEStorage();
$result = $ce-upload($tmp_name, $filename);
#$rs1 = $ce-errmsg(); 输出错误信息
#$rs2 = $ce-errno();
$result为返回的附件文件路径,可直接访问,如:
www.domain.com/aliyun_ce_storage/$filename
5. 缩略、水印等特殊问题
受本地文件读写条件限制等问题,缩略、水印等功能暂不支持,我们会在后续的版本中支持。
6. 数据备份恢复问题
ACE提供在线备份数据功能,在创建应用时,可以选择备份时间点。
如果想从应用中导出数据,则需要使用数据库客户端工具进行操作。
在Linux中源码安装MariaDB
在CentOS 8(位)阿里云Linux 3. LTS服务器上,通过源码安装MariaDB .5.的详细步骤如下:
首先,访问MariaDB官网下载对应版本的源码包,下载地址为:mariadb.org/download/?...
下载完成后,使用WinSCP 5..4工具将mariadb-.5..tar.gz上传到服务器的/usr/local/src目录。
为了顺利安装,检查系统上是否有与MariaDB冲突的MySQL版本,可通过执行`rpm -qa | grep mysql`进行检测。如果存在,可以使用`rpm -e --nodeps`命令卸载,如"mysql-libs-5.1.-1.el6_0.1.x_"。
接着,确认服务器上没有mariadb数据库,同样使用`rpm -qa | grep mariadb`检查。如有,也需卸载。
然后,配置环境,安装依赖,如autoconf、cmake等。在服务器上使用`yum install -y ...`命令安装。
创建data文件夹,并解压和重命名源码文件。接着,进入安装目录,执行cmake编译安装命令,配置安装路径和数据库相关参数。
编译完成后,编辑`/etc/profile`文件并添加环境变量,创建my.cnf文件,调整文件权限。初始化数据库,确保`mysql.server start`命令执行成功。
将启动脚本添加到开机初始化目录,设置mysql服务开机启动。登录MariaDB,执行`mysql_secure_installation`设置root账号密码。
最后,重启mysql服务并测试登录,确认安装和配置完成。如果有任何问题,如登录失败,应检查服务状态并重新初始化和启动。
FLINK 部署(阿里云)、监控 和 源码案例
FLINK部署、监控与源码实例详解
在实际部署FLINK至阿里云时,POM.xml配置是一个关键步骤。为了减小生产环境的包体积并提高效率,我们通常选择将某些依赖项设置为provided,确保在生产环境中这些jar包已预先存在。而在本地开发环境中,这些依赖需要被包含以支持测试。 核心代码示例中,数据流API的运用尤其引人注目。通过Flink,我们实现了从Kafka到Hologres的高效数据流转。具体步骤如下:Kafka配置:首先,确保Kafka作为数据源的配置正确无误,包括连接参数、主题等,这是整个流程的开端。
Flink处理:Flink的数据流API在此处发挥威力,它可以实时处理Kafka中的数据,执行各种复杂的数据处理操作。
目标存储:数据处理完成后,Flink将结果无缝地发送到Hologres,作为最终的数据存储和分析目的地。
一行代码将文件存储到本地或各种存储平台
介绍一个开源项目,其功能是一行代码即可实现将文件存储到本地或多种存储平台,包括但不限于FTP、SFTP、WebDAV、阿里云OSS、华为云OBS等。此项目适用于SpringBoot环境,且提供非SpringBoot环境使用指南。 配置与使用步骤如下: 引入pom文件,确保环境为SpringBoot。 非SpringBoot环境使用方法,可参考官方文档。 配置本地文件存储。 在启动类上添加@EnableFileStorage注解。 注入对应的service。快速入门上传文件
引入pom文件后,以本地上传为例进行配置。编写配置文件,基础配置包括本地文件存储标识。可以参考官网快速入门教程,配置文件及使用方式。 在启动类上添加@EnableFileStorage注解后,可以开始使用服务进行文件上传。上传文件
通过注入服务,实现文件上传至本地。测试上传
执行测试操作,验证文件上传至本地。返回URL
如果需要返回文件的访问URL,可通过服务方法获取。文件信息链式编程
FileInfo对象包含测试结果信息,可通过链式编程访问。上传
上传返回地址及锁视图。进阶操作
实现文件不落盘、边读取边上传的直接上传方法,开启multipart懒加载配置。通过FileRecorder接口保存上传记录至数据库。上传记录保存
创建数据库表,实现FileRecorder接口以保存文件信息。上传文件
将FileInfo对象转化为FileDetail完成文件上传至数据库。下载与删除
查看官方文档获取下载方法。提供删除操作总结。总结
项目提供简单入门指南,更多功能与操作请参考官方文档。项目源代码可在GitHub上找到。
白俄羅斯宣布成為首個金磚國家夥伴國
网页探针 源码_网页探针 源码是什么

mysql安装源码_mysql 源码安装
主力筹码 源码_主力筹码源码
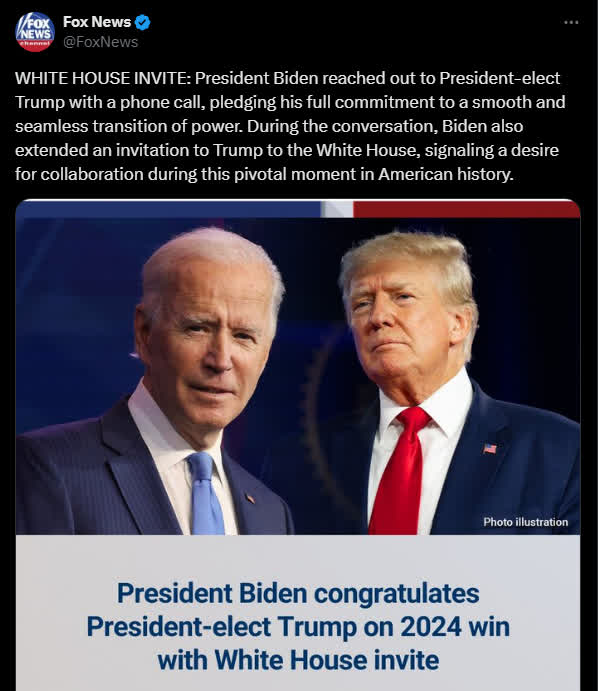
拜登與特朗普通話 祝賀其勝選

网页提醒源码_网页提醒源码怎么设置
