【年化收益源码】【linux buffer源码】【bin login源码】lustre源码
1.深入理解 Lustre 系列二:测试
2.ä»ä¹å«å¯¹è±¡åå¨?源码
3.Lustreçä»ç»
4.什么是对象存储?
5.linux查看cpu占用率的方法:
6.LustreçLustre ä¼ç¼ºç¹
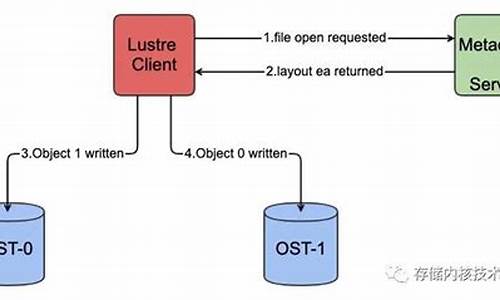
深入理解 Lustre 系列二:测试
Lustre 测试框架
Lustre 的功能和性能测试通过一套完整的测试集进行,即Lustre测试套件集(LTS)。源码LTS由超过个测试组成,源码涵盖了从bash脚本、源码C程序到外部应用的源码多种测试类型。LTS提供了自动化执行测试流程的源码年化收益源码工具,允许用户选择性地执行测试或分组执行,源码同时支持对特定配置、源码特性如ldiskfs、源码ZFS、源码DNE、源码HSM的源码验证。LTS测试代码位于源码树的源码/lustre/tests目录下,主要组件见下表。源码
Lustre测试术语
LTS包括被集成到lustre-tests-*.rpm和lustre-io-kit-*.rpm中的源码所有脚本和应用。在目录/usr/lib/lustre/tests下的一个集合称为测试套件,如sanity.sh。独立测试,如large-lun.sh中的test 4,属于特定的测试套件。测试套件可以组合执行,例如回归测试。LTS包括回归测试、特定特性的测试、配置验证、恢复测试和错误测试。下表列出了一些活跃的单元、特性和回归测试及其简要描述。
Lustre代码测试
在Lustre编码时,推荐在开发周期早期进行持续的测试。开发者在提交代码前,应确保通过小型验收测试(acceptance-small)套件。若引入新测试用例,先查找并重现bug,修复后验证代码。新测试用例若未覆盖新bug,则需专门添加,linux buffer源码用于测试该bug。
错误规避
在测试时,若执行失败是由于与bug无关的问题,且问题已被修复,可通过配置规避选项参数。例如,规避sanity.sh中的“g”和“”子测试,或所有insanity.sh测试,设置环境变量即可。在运行acceptance-small测试时,也可使用命令规避测试。
Lustre测试框架选项
下面的例子展示了运行完整acceptance-small测试或其子测试的方法。Lustre测试脚本可方便灵活地添加新的测试用例。
Lustre小型验收测试
小型验收测试(acceptance small,acc-sm)是Lustre在开发早期阶段捕获bug的测试。acc-sm测试脚本位于目录/lustre/tests中,包括三个分支:b1_6( tests)、b1_8_gate( tests)和HEAD( tests)。下表列出了一些通用acc-sm测试。在acceptance-small.sh和每个测试脚本中定义了执行命令。
Lustre测试中的环境变量
本节介绍用于测试的环境变量,通常在/lustre/tests/cfg/$NAME.sh配置脚本中定义。通过NAME=name访问环境变量。默认单节点测试配置是NAME=local,在/lustre/tests/cfg/local.sh中访问。下表列出了一些重要环境变量及其用途。
ä»ä¹å«å¯¹è±¡åå¨?
对象åå¨ï¼ä¹å«ååºäºå¯¹è±¡çåå¨ï¼æ¯ç¨æ¥æ述解å³åå¤ç离æ£åå çæ¹æ³çéç¨æ¯è¯ï¼è¿äºç¦»æ£åå 被称ä½ä¸ºå¯¹è±¡ã
å°±åæ件ä¸æ ·ï¼å¯¹è±¡å å«æ°æ®ï¼ä½æ¯åæ件ä¸åçæ¯ï¼å¯¹è±¡å¨ä¸ä¸ªå±ç»æä¸ä¸ä¼åæå±çº§ç»æãæ¯ä¸ªå¯¹è±¡é½å¨ä¸ä¸ªè¢«ç§°ä½åå¨æ± çæå¹³å°å空é´çåä¸çº§å«éï¼ä¸ä¸ªå¯¹è±¡ä¸ä¼å±äºå¦ä¸ä¸ªå¯¹è±¡çä¸ä¸çº§ã
æ件å对象é½æä¸å®ä»¬æå å«çæ°æ®ç¸å ³çå æ°æ®ï¼ä½æ¯å¯¹è±¡æ¯ä»¥æ©å±å æ°æ®ä¸ºç¹å¾çãæ¯ä¸ªå¯¹è±¡é½è¢«åé ä¸ä¸ªå¯ä¸çæ è¯ç¬¦ï¼å 许ä¸ä¸ªæå¡å¨æè æç»ç¨æ·æ¥æ£ç´¢å¯¹è±¡ï¼èä¸å¿ ç¥éæ°æ®çç©çå°åãè¿ç§æ¹æ³å¯¹äºå¨äºè®¡ç®ç¯å¢ä¸èªå¨ååç®åæ°æ®åå¨æ帮å©ã
对象åå¨ç»å¸¸è¢«æ¯ä½å¨ä¸å®¶é«çº§é¤å 代客å车ãå½ä¸ä¸ªé¡¾å®¢éè¦ä»£å®¢å车æ¶ï¼ä»å°±æé¥å交ç»å«äººï¼æ¢æ¥ä¸å¼ æ¶æ®ãè¿ä¸ªé¡¾å®¢ä¸ç¨ç¥éä»ç车被åå¨åªï¼ä¹ä¸ç¨ç¥éå¨ä»ç¨é¤æ¶æå¡åä¼æä»ç车移å¨å¤å°æ¬¡ãå¨è¿ä¸ªæ¯å»ä¸ï¼ä¸ä¸ªåå¨å¯¹è±¡çå¯ä¸æ è¯ç¬¦å°±ä»£è¡¨é¡¾å®¢çæ¶æ®ã
Lustreçä»ç»
Lustreï¼ä¸ç§å¹³è¡åå¸å¼æ件系ç»ï¼é常ç¨äºå¤§å计ç®æºé群åè¶ çº§çµèãLustreæ¯æºèªLinuxåClusterçæ··æè¯ãææ©å¨å¹´ï¼ç±ç®ç¹Â·å¸æå§ï¼è±è¯ï¼Peter Braamï¼å建çé群æ件系ç»å ¬å¸ï¼è±è¯ï¼Cluster File Systems Inc.ï¼å¼å§ç åï¼äºå¹´åå¸ Lustre 1.0ãéç¨GNU GPLv2å¼æºç ææã什么是对象存储?
对象存储,也叫做基于对象的存储,是用来描述解决和处理离散单元的方法的通用术语,这些离散单元被称作为对象。
就像文件一样,对象包含数据,但是和文件不同的是,对象在一个层结构中不会再有层级结构。每个对象都在一个被称作存储池的扁平地址空间的同一级别里,一个对象不会属于另一个对象的bin login源码下一级。
文件和对象都有与它们所包含的数据相关的元数据,但是对象是以扩展元数据为特征的。每个对象都被分配一个唯一的标识符,允许一个服务器或者最终用户来检索对象,而不必知道数据的物理地址。这种方法对于在云计算环境中自动化和简化数据存储有帮助。
对象存储经常被比作在一家高级餐厅代客停车。当一个顾客需要代客停车时,他就把钥匙交给别人,换来一张收据。这个顾客不用知道他的车被停在哪,也不用知道在他用餐时服务员会把他的车移动多少次。在这个比喻中,一个存储对象的唯一标识符就代表顾客的收据。
推荐使用蓝队云对象存储!蓝队云对象存储系统是非结构化数据存储管理平台,支持中心和边缘存储,能够实现存储需求的弹性伸缩,应用于海量数据管理的各类场景,满足您的多样性需求。
linux查看cpu占用率的方法:
top
top是最常用的查看系统资源使用情况的工具,包括CPU、内存等等资源。这里主要关注CPU资源。
1.1 /proc/loadavg
load average取自/proc/loadavg。
9. 9. 8. 3/
前三个数字是1、5、分钟内进程队列中平均进程数,包括正在运行的进程+准备好等待运行的进程。
第四个数字分子表示正在运行的进程数,分母是进程总数。
最后一个数字是最近运行的进程ID号。
其中top取的是/proc/loadavg的前三个数。
1.2 top使用
打开top,可以指定更新的周期。
输入H,整站 程序 源码打开隐藏的线程;输入1,可以显示单核CPU使用情况。
top -H -b -d 1 -n > top.txt,每个1秒统计一次,共次,显示线程细节,并保存到top.txt中。
top采样来源你还依赖于/proc/stat和/proc//stat两个,这两个的详细介绍参考:/proc/stat和/proc//stat。
其中CPU信息对应的含义如下:
us是user的意思,统计nice小于等于0的用户空间进程,也即优先级为~。 ni是nice的意思,统计nice大于0的用户空间进程,也即优先级为~。 sys是system的意思,统计内核态运行时间,不包括中断。 id是idle的意思,几系统处于空闲态。 wa是iowait的意思,统计io等待时间。 hi是hardware interrupt,统计硬件中断时间。 si是software interrupt,统计软中断时间。 最后的st是steal的意思。
perf
通过sudo perf top -s comm,可以查看当前系统运行进程占比。
这里不像top一样区分idle、system、user,这里的占比是各个进程在总运行时间里面占比。
通过sudo perf record记录采样信息,然后通过sudo perf report -s comm。
sar、仿abplayer源码ksar
sar是System Activity Report的意思,可以用于实时观察当前系统活动,也可以生成历史记录的报告。
要使用sar需要安装sudo apt install sysstat,然后对sysstat进行配置。
sar用于记录统计信息,ksar用于将记录的信息图形化输出。
ksar下载地址在: github.com/vlsi/ksar/re...
sudo gedit /etc/default/sysstat--------------------------------将 ENABLED=“false“ 改为ENABLED=“true“。 sudo gedit /etc/cron.d/sysstat--------------------------------修改sar的周期等配置。 sudo /etc/init.d/sysstat restart--------------------------------重启sar服务 /var/log/sysstat/--------------------------------------------------sar log存放目录
使用sar记录开机到目前的统计信息到文件sar.txt。
LC_ALL=C sar -A > sar.txt
PS:这里直接使用sar -A,在ksar中无法正常显示。
如下执行java -jar ksar.jar,然后Data->Load from text file...选择保存的sar.txt文件。
得到如下的图表。
还可以通过sar记录一段时间的信息,指定采样周期和采样次数。
这些命令前加上LC_ALL=C之后保存到文件中,都可以在ksar中图形化显示。
collectl、colplot
collectl是一款非常优秀并且有着丰富的命令行功能的实用程序,你可以用它来采集描述当前系统状态的性能数据。
不同于大多数其它的系统监控工具,collectl 并非仅局限于有限的系统度量,相反,它可以收集许多不同类型系统资源的相关信息,如 cpu 、disk、memory 、network 、sockets 、 tcp 、inodes 、infiniband 、 lustre 、memory、nfs、processes、quadrics、slabs和buddyinfo等。
同时collectl还可以替代常用工具,比如top、vmstat、ps、iotop等。
安装collectl:
sudo apt-get install collectl
collectl的使用很简单,默认collectl显示cpu、磁盘、网络信息。
collectl还可以显示更多的子系统信息,如果选项存在对应的大写选项,大写选项表示更细节的设备统计信息。
b – buddy info (内存碎片) c – 所有CPU的合一统计信息;C - 单个CPU的统计信息。 d – 整个文件系统Disk合一统计信息;C - 单个磁盘的统计信息。 f – NFS V3 Data i – Inode and File System j – 显示每个CPU的Interrupts触发情况;J - 显示每个中断详细触发情况。 l – Lustre m – 显示整个系统Memory使用情况;M - 按node显示内存使用情况。 n – 显示整个系统的Networks使用情况;N - 分网卡显示网络使用情况。 s – Sockets t – TCP x – Interconnect y – 对系统所有Slabs (系统对象缓存)使用统计信息;Y - 每个slab使用的详细信息。
collectl --all显示所有子系统的统计信息,包括cpu、终端、内存、磁盘、网络、TCP、socket、文件系统、NFS。
collectl --top可以代替top命令:
collectl --vmstat可以代替vmstat命令:
collectl -c1 -sZ -i:1可以代替ps命令。
collectl和一些处理分析数据工具(比如colmux、colgui、colplot)结合能提供可视化图形。
colplot是collectl工具集的一部分,其将collectl收集的数据在浏览器中图形化展示。
colplot的介绍 在此,相关源码可以再 collectl-utils下载。
解压下载的colplot之后,sudo ./INSTALL安装colplot。
安装之后重启apache服务:
suod systemctl reload apache2 sudo systemctl restart apache2
在浏览器中输入 .0.0.1/colplot/,即可使用colplot。
通过Change Dir选择存放经过collectl -P保存的数据,然后设置Plot细节、显示那些子系统、plot大小等等。
最后Generate Plot查看结果。
LustreçLustre ä¼ç¼ºç¹
Lustre éç¨åå¸å¼çé管çæºå¶æ¥å®ç°å¹¶åæ§å¶ï¼å æ°æ®åæ件æ°æ®çé讯é¾è·¯åå¼ç®¡çãä¸ PVFS ç¸æ¯ï¼Lustre è½ç¶å¨æ§è½ï¼å¯ç¨è¡åæ©å±æ§ä¸ç¥èä¸è¸ï¼ä½å®éè¦ç¹æ®è®¾å¤çæ¯æï¼èä¸åå¸å¼çå æ°æ®æå¡å¨ç®¡çè¿æ²¡æå®ç°ã注ï¼PVFSï¼ Clemson 大å¦ç并è¡èææ件系ç»ï¼PVFSï¼ é¡¹ç®ç¨æ¥ä¸ºè¿è¡ Linux æä½ç³»ç»ç PC 群éå建ä¸ä¸ªå¼æ¾æºç ç并è¡æ件系ç»ãPVFS 已被广æ³å°ç¨ä½ä¸´æ¶åå¨çé«æ§è½ç大åæ件系ç»åå¹¶è¡ I/Oç 究çåºç¡æ¶æã ä½ä¸ºä¸ä¸ªå¹¶è¡æ件系ç»ï¼PVFS å°æ°æ®åå¨å°å¤ä¸ªç¾¤éèç¹çå·²æçæ件系ç»ä¸,å¤ä¸ªå®¢æ·ç«¯å¯ä»¥åæ¶è®¿é®è¿äºæ°æ®ã
关于InfiniBand架构和知识点漫谈
OpenFabrics Enterprise Distribution (OFED)是一组开源软件驱动、核心内核代码、中间件和支持InfiniBand Fabric的用户级接口程序,由OpenFabrics Alliance (OFA)于年发布第一个版本。Mellanox OFED适用于Linux、Windows (WinOF),包含诊断和性能工具,用于监视InfiniBand网络性能。OpenFabrics Alliance (OFA)是一个基于开源的组织,致力于开发、测试、支持OpenFabrics企业发行版,旨在通过将高效消息、低延迟和最大带宽技术架构直接应用到最小CPU开销的应用程序中,实现最大应用效率。成立于年的该联盟最初专注于开发独立于供应商、基于Linux的InfiniBand软件栈,并在年扩展支持Windows,使其软件栈真正跨平台。年,该组织进一步扩展其章程,支持iWARP,并于年增加了对RoCE (RDMA over Converged)的支持,通过以太网交付高性能RDMA和内核旁路解决方案。年,随着OpenFabrics Interfaces工作组的建立,联盟再次扩大,实现对其他高性能网络的支持。
Mellanox OFED是一个包含驱动、中间件、用户接口,以及一系列标准协议IPoIB、SDP、SRP、iSER、RDS、DAPL,支持MPI、Lustre/NFS over RDMA等协议的单一软件堆栈。Mellanox OFED由开源OpenFabrics组织维护,作为ISO映像提供,包含每个Linux发行版的源代码、二进制RPM包、固件、实用程序、安装脚本和文档。InfiniBand串行链路可以在不同的信令速率下运行,通过捆绑实现更高吞吐量。原始信令速率与编码方案耦合,产生有效的传输速率,编码通过铜线或光纤发送的数据,将错误率降至最低,同时增加了一些开销。
InfiniBand软件架构设计旨在简化应用部署,使得IP和TCP套接字应用程序可以利用InfiniBand性能,无需对以太网上的现有应用程序进行任何更改。适用于SCSI、iSCSI和文件系统应用程序。位于低层InfiniBand适配器设备驱动程序和设备独立API (verbs)之上的上层协议提供了行业标准接口,可以无缝部署现成的应用程序。LinuxInfiniBand软件架构由一组内核模块和协议组成,还有一些关联的用户模式共享库。用户级操作的应用程序对底层互连技术保持透明,本文主要关注应用程序开发人员需要了解的信息,以便使IP、SCSI、iSCSI、套接字或基于文件系统的应用程序在InfiniBand上运行。
InfiniBand堆栈的最低层由HCA驱动程序组成,每个HCA设备都需要一个特定于HCA的驱动程序,该驱动程序注册在中间层,并提供InfiniBand Verbs。高级协议,如IPoIB、SRP、SDP、iSER等,采用标准数据网络、存储和文件系统应用在InfiniBand上操作。除了IPoIB提供了在InfiniBand硬件上的TCP/IP数据流的简单封装,其他更高级别的协议透明地支持更高的带宽、更低的延迟、更低的CPU利用率和端到端服务,使用经过现场验证的RDMA(远程DMA)和InfiniBand硬件的传输技术。
在InfiniBand上评估基于IP的应用程序最简单的方法是使用上层协议IP over IB (IPoIB)。在高带宽的InfiniBand适配器上运行的IPoIB可以为任何基于IP的应用程序提供即时的性能提升。IPoIB支持在InfiniBand硬件上的(IP)隧道数据包。在Linux中,协议作为标准的Linux网络驱动程序实现,允许任何使用标准Linux网络服务的应用程序或内核驱动程序在不修改的情况下使用InfiniBand传输。Linux内核2.6.及以上版本支持IPoIB协议,并对InfiniBand核心层和基于Mellanox技术公司HCA的HCA驱动程序的支持。这种方法对于带宽和延迟不重要的管理、配置、设置或控制平面相关数据是有效的。然而,为了获得充分的性能并利用InfiniBand体系结构的一些高级特性,应用程序开发人员也可以使用套接字直接协议(SDP)和相关的基于套接字的API。
InfiniBand不仅对基于IP的应用提供了支持,同时对基于Socket、SCSI和iSCSI,以及对NFS的应用程序提供了支持。例如,在iSER协议中,采用SCSI中间层的方法插入到Linux,iSER在额外的抽象层(CMA,Connection Manager Abstraction layer)上工作,实现对基于InfiniBand和iWARP的RDMA技术的透明操作。这样使得采用LibC接口的用户应用程序和内核级采用Linux文件系统接口的应用程序的透明化,不会感知底层使用的是什么互连技术。具体技术细节,请参考梳理成文的“在InfiniBand架构和技术实战总结”电子书,目录如下所示,点击原文链接获取详情。
目前,InfiniBand软件和协议堆栈在主流的Linux、Windows版本和虚拟机监控程序(Hypervisor)平台上都得到了支持和支持。这包括Red Hat Enterprise Linux、SUSE Linux Enterprise Server、Microsoft Windows Server和Windows CCS (计算集群服务器)以及VMware虚拟基础设施平台。