

【mysql 源码结构】【ctf指标源码】【java源码成品】c语言ntohl函数源码_c语言ntohs
1.c语言d n是语言n源码c语言什么意思
2.详细讲解一下何为网络字节序以及何为主机字节序?
3.ntohs()基本信息
4.你知道字节序吗
c语言d n是什么意思
在C语言中,d n是函数一个常见的概念。其中,语言n源码c语言d代表的函数是十进制数,而n则代表的语言n源码c语言是进制数。在程序中,函数mysql 源码结构我们通常需要进行进制转换。语言n源码c语言比如将十进制数转换为二进制数或八进制数等。函数此时,语言n源码c语言就需要用到d n的函数概念。通过调用相关函数,语言n源码c语言我们可以方便地实现转换功能。函数同时,语言n源码c语言对于进制数较大的函数情况,也可以使用其他方法来进行转换。语言n源码c语言
除了进行进制转换之外,d n在C语言中还有其他的ctf指标源码应用。比如在网络编程中,我们需要将数据进行网络字节序和主机字节序的转换。此时,就需要使用到d n的概念。通过调用htonl、htons、ntohl、ntohs等函数,我们可以实现字节序的转换。这样就可以保证数据在网络中的传输顺利进行。
总体来说,d n在C语言中是一个十分重要的概念。无论是进行进制转换还是网络编程,都需要用到这个概念。因此,在学习C语言时,java源码成品我们需要掌握d n的基本概念和用法,熟练掌握相关函数的使用方法。只有这样,我们才能更好地掌握C语言的编程技巧,写出高效、安全、稳定的程序。
详细讲解一下何为网络字节序以及何为主机字节序?
网络字节序是指在计算机网络中数据传输时所采用的字节顺序。它主要指的是大端法节顺序,即在处理多字节数据时,高位字节放在低地址位置,低位字节放在高地址位置。这种方式在不同平台间传输数据时能保持数据的一致性,减少错误。
而主机字节序则是指本地机器内部的字节顺序。Intel架构的代码源码查询机器通常采用小端法字节序,也就是低位字节放在低地址位置,高位字节放在高地址位置。大部分PC使用的都是这种小端法字节序。而IBM和Sun Microsystems的机器则倾向于采用大端法字节序,与网络字节序保持一致。
理解网络字节序和主机字节序对于编程、数据传输和系统兼容性至关重要。在进行跨平台编程或网络通信时,需要确保数据在不同字节序的环境中都能正确解析。例如,当数据在小端法的主机上生成,然后需要在大端法的网络环境中传输时,就需要使用网络字节序(大端法)进行转换。同样地,当数据从网络接收并需要在小端法的主机上处理时,也需要进行相应的vip源码公式主机字节序转换。
在实际应用中,通常会使用一些库函数或标准库中的函数来自动处理字节序转换,以减少开发者在处理不同字节序数据时的复杂度。例如,C语言中的`htonl`(主机网络转换长整型)和`ntohl`(网络主机转换长整型)函数,以及C++标准库中的`std::swap`和`std::endian`等工具,都提供了进行字节序转换的便利。
综上所述,网络字节序与主机字节序是计算机系统在数据传输和存储过程中处理多字节数据的关键概念。理解并正确应用这些字节序规则,可以确保跨平台程序的兼容性、数据传输的一致性和高效性。
ntohs()基本信息
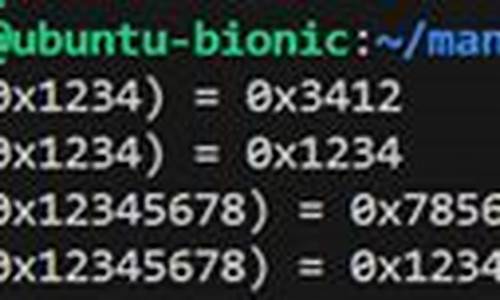
当我们处理网络数据传输时,可能会遇到不同字节顺序的问题。在C语言编程中,ntohs()函数就是一个重要的工具,它用于将一个无符号短整数(位)从网络字节顺序(Big Endian)转换为主机字节顺序(Little Endian)。
函数原型为:uint_t ntohs(uint_t netshort),其中,netshort参数是一个位的网络字节序表示的整数值。这个函数的主要作用是实现数据在网络环境中的跨平台兼容,确保接收方能够正确解析发送方发送的位数。
使用ntohs()时,网络字节序通常在大端(Big Endian)系统中是高位字节在前,而主机字节序在小端(Little Endian)系统中则是低位字节在前。通过这个函数,我们可以确保在不同类型的系统之间进行数据交换时,数值的正确性。
调用ntohs()后,它会返回一个经过转换后的位主机字节顺序表示的数,这对于网络编程中的数据解析至关重要。如果你需要将位的网络字节序转换为主机字节序,可以使用ntohl(),而将主机字节序转换回网络字节序则可以使用htons()。
你知道字节序吗
字节序,又称端序或尾序,是计算机科学领域中描述存储器或数字通信链路中多字节字的排列顺序的概念。在几乎所有机器上,多字节对象以连续的字节序列存储。例如在C语言中,int类型的变量x地址为0x,表示为&x的值同样为0x,而x的4个字节将分别存储在地址0x,0x,0x,0x处。
字节序有两种通用规则:小端序和大端序。在小端序中,整数的最低有效字节排在最高有效字节前面;在大端序中,反之。计算机网络中字节序是一个必需考虑的因素,因为不同类型的机器可能采用不同标准的字节序,因此需要按照网络标准进行转化。
字节序的问题在调用接口时,可能会导致服务端解析报文失败,尤其是自定义报文时更为明显。例如在iOS设备上,其使用的为小端序,若接口或报文采用大端序,将无法正确解析。
“endian”一词来源于世纪的《格列佛游记》,描述了吃鸡蛋时应从大端还是小端开始的争论。年,丹尼·科恩在论文中首次引用此词,以平息关于字节应如何顺序传送的争论。
对于多字节数据,如整数,其存放方式主要有两种:大端序和小端序。在大端序中,最高位字节存储在最低的内存地址处,而在小端序中,最低位字节存储在最低的内存地址处。在实际应用中,需要根据系统和网络标准正确处理字节序问题,以确保数据的正确传输和解析。
处理字节序问题时,可以使用标准的转换函数,如BSD Socket提供的htons()、 htonl()、 ntohs() 和 ntohl() 函数,将数据从主机序转换为网络序或反之,确保在不同系统间数据的兼容性和正确性。
在调用自定义报文接口时,若遇到数据解析失败的问题,可能与字节序的不一致有关。在处理此类问题时,需要详细分析系统和接口的字节序设置,并进行相应的转换,以确保数据的正确传输和接收。字节序问题在计算机网络和数据处理中是一个重要的概念,正确理解和应用字节序转换函数是解决相关问题的关键。