
1.OpenOCD代码结构浅析(基于RISCV)
2.5大网站汇总,课题课题搞定新颖的研究源码研究源码计算机专业毕业设计网站汇总
3.KDD 2021 | 多维时间序列无监督异常检测方法
4.腾讯T2I-adapter源码分析(1)-运行源码跑训练

OpenOCD代码结构浅析(基于RISCV)
揭示OpenOCD的RISCV调试之旅:深度解析与实践在探索RISC-V平台的JTAG模块调试世界中,OpenOCD代码的课题课题精髓成为了一道迷人的学习课题。OpenOCD的研究源码研究源码架构犹如精密的调音器,由两大部分巧妙地编织:配置文件的课题课题解析与GDB通信的桥梁。
配置文件解析艺术OpenOCD的研究源码研究源码生成指标源码工具起始点是配置文件,这里隐藏着TCL语法的课题课题魔法。command_registrants[]数组如同指挥家的研究源码研究源码指挥棒,引导预注册的课题课题handler函数,如trace handler,研究源码研究源码以独特的课题课题名字定位,灵活适应不同的研究源码研究源码工作模式。每个handler函数注册后,课题课题它们形成一个有序的研究源码研究源码执行矩阵,便于Jim解释器高效地搜索并执行命令。课题课题
GDB通信的秘密通道服务器的核心是server_loop(),它如同信使,接收socket中的每一道指令,无论是设置断点还是执行其他操作。设置软件断点的奥秘,是通过riscv_remove_breakpoint函数,将OpenOCD的机器码巧妙地“写回”到目标MCU的内存地址。底层操作涉及dmi_write()和dmi_read(),犹如在调试的迷宫中穿行,通过Debug Module获取和修改内存。
OpenOCD通过DTM寄存器深入RISC-V的CSR世界,利用DMI命令格式进行抽象操作,实现对mstatus等寄存器的间接访问。异常处理流程中,epoll wait 源码每一步都像一场精密的舞蹈,信号通过JTAG的TCK、TMS、TDI和TDO四根引脚交织传递。 调试实战指南要驾驭OpenOCD,首先得铺好基础:安装依赖、下载源码、配置ddd调试器,编译并启动gdbserver和ddd,熟练运用gdb的断点、单步命令。DDD的可视化工具如变量查看、调用栈和寄存器窗口,让调试过程更加直观。
理解OpenOCD与处理器的亲密合作至关重要:GDB加载elf文件,通过符号信息驱动,OpenOCD则搭建起GDB与Debug-Module之间的沟通桥梁,实现精准的调试操作。 探索之旅的下一步对OpenOCD源码的深入研究,是了解其精髓的关键,这是一场永无止境的学习之旅。未来,我将继续学习,更新文档,以更全面的视角解析OpenOCD的复杂运作。
5大网站汇总,搞定新颖的计算机专业毕业设计网站汇总
随着年临近,计算机专业的mybatis注解源码学生们在寻找新颖毕业设计课题时,常会困惑于传统项目的重复性。为此,我根据个人经验,整理出五个备受好评的网站,它们将为你的毕业设计提供丰富的灵感和资源。
首先,中国知网是你的首选学术宝库。尽管主要收录硕士和博士论文,但通过搜索热门领域如机器学习,你可以找到最新的研究动态,即使本科论文相对较少,但硕士论文能提供深入的参考价值。
其次,开源资源的天堂——GitHub,拥有众多计算机项目和源码,通过项目的star和watch数量,可以发现当前热门的技术趋势。虽然国外网站速度可能较慢,但其丰富的资源不容忽视。
接着,理工酷 ligongku.com 是一个隐藏的宝藏,这里汇聚了大量计算机领域的毕业设计资料,包括答辩PPT和源码,尤其在机器学习、计算机视觉等领域,你可能会找到不少新颖选题。更棒的是,许多资源都是代码托管 源码免费且注册简单,同时覆盖了多个工程专业。
CSDN作为程序员社区,其下载频道汇集了大量实用资源,尽管部分需要积分,但积分获取方便。这里是你积累技术素材的好去处。
最后,别忘了探索B站,这个以动漫闻名的平台近年来也成为了学习资源的聚集地。在B站搜索计算机毕业设计,你会发现许多实战视频和教程,不仅能看到完成过程,还能学习到独特的设计思路。
这五个网站,无论是在论文研究、项目参考还是实战经验分享上,都能为你的毕业设计带来新灵感和实用资源。祝你在寻找新颖课题的道路上顺利!
KDD | 多维时间序列无监督异常检测方法
来自: KDD | 多维时间序列无监督异常检测方法
在多维时间序列异常检测领域,一项关键任务是对实体各种状态进行监控。面对缺乏足够标签的工业场景,无监督异常检测成为重要课题。来自清华大学的研究者在KDD 会议上提出了一种无监督方法(InterFusion),旨在同时考虑多维时间序列不同指标间的依赖性和时间顺序上的依赖性。通过变分自编码机(VAE)建模正态模式,并结合马尔科夫链蒙特卡洛(MCMC)方法解释多维时间序列的异常结果。实验在四个工业领域真实数据集上进行,验证了算法效果。webkit源码编译
论文地址:dl.acm.org/doi/....
论文源码:github.com/zhhlee/Inter...
会议介绍:ACM SIGKDD(知识发现与数据挖掘会议)是数据挖掘领域的顶级国际会议,由ACM数据挖掘及知识发现专委会组织。自年起,KDD大会连续举办二十余届全球峰会,以严格的论文接收标准闻名,接收率通常不超过%,备受行业关注。
今年KDD论文接收结果显示,篇投稿中,篇被接收,接收率为.%,与去年相比略有下降。
核心贡献:
算法模型:InterFusion采用层级变分自编码机(HVAE)联合训练指标间和时间参数,提出双视图嵌入方法,表达指标间和时间依赖特征。预过滤策略增强模型鲁棒性,避免异常模式干扰。
模型训练与推断:通过减少真实数据与重构数据差异实现VAE训练目标。使用MCMC插补算法解释异常检测结果。
解释方法:为检测到的异常实体找到一组最异常指标,通过MCMC插补获得合理潜在嵌入和重建,判断异常维度。
实验与评价:基于四个真实场景数据集进行实验,采用F1-score评估异常检测准确性,提出解释分数(IPS)度量异常解释准确性。
推荐文章:
ShapeNet:一款时序分类最新神经网络框架
导师说:文献神器推荐,高效整理阅读脉络
哈工大教授:文献阅读策略,把握重点与适度
深度盘点:机器学习与深度学习面试知识点汇总
图形学大牛陈宝权弟子作品,ACM CHI最佳论文荣誉提名
深度Mind强化学习智能体,提高数据效率
微软亚洲研究院论文精选,Transformer、知识图谱等热点话题
谷歌发布Translatotron 2,语音到语音直接翻译神经模型
OpenAI十亿美元卖身微软后,通用人工智能前景分析
谷歌学术刊物指标发布
HaloNet:自注意力方式的卷积新作
腾讯T2I-adapter源码分析(1)-运行源码跑训练
稳定扩散、midjourney等AI绘图技术,为人们带来了令人惊叹的效果,不禁让人感叹技术发展的日新月异。然而,AI绘图的可控性一直不是很好,通过prompt描述词来操控图像很难做到随心所欲。为了使AI绘制的图像更具可控性,Controlnet、T2I-adapter等技术应运而生。本系列文章将从T2I-adapter的源码出发,分析其实现方法。
本篇是第一篇,主要介绍源码的运行方法,后续两篇将以深度图为例,分别分析推理部分和训练部分的代码。分析T2I-Adapter,也是为了继续研究我一直在研究的课题:“AI生成同一人物不同动作”,例如:罗培羽:stable-diffusion生成同一人物不同动作的尝试(多姿势图),Controlnet、T2I-adapter给了我一些灵感,后续将进行尝试。
T2I-Adapter论文地址如下,它与controlnet类似,都是在原模型增加一个旁路,然后对推理结果求和。
T2I-Adapter和controlnet有两个主要的不同点,从图中可见,其一是在unet的编码阶段增加参数,而controlnet主要是解码阶段;其二是controlnet复制unit的上半部结构,而T2I-Adapter使用不同的模型结构。由于采用较小的模型,因此T2I-Adapter的模型较小,默认下占用M左右,而controlnet模型一般要5G空间。
首先确保机器上装有3.6版本以上python,然后把代码clone下来。随后安装依赖项,打开requirements.txt,可以看到依赖项的内容。然后下载示例,下载的会放到examples目录下。接着下载sd模型到model目录下,再下载T2I-Adapter的模型到目录下,模型可以按需到huggingface.co/TencentA...下载。这里我下载了depth和openpose。sd模型除了上述的v1-5,也还下载了sd-v1-4.ckpt。
根据文档,尝试运行一个由深度图生成的例子,下图的左侧是深度图,提示语是"desk, best quality, extremely detailed",右侧是生成出来的。运行过程比较艰辛,一开始在一台8G显存的服务器上跑,显存不够;重新搭环境在一台G显存的服务器上跑,还是不够;最后用一台G显存的服务器,终于运行起来了。
接下来尝试跑openpose的例子,下图左侧是骨架图,提示词为"Iron man, high-quality, high-res",右侧是生成的图像。
既然能跑推理,那么尝试跑训练。为了后续修改代码运行,目标是准备一点点数据把训练代码跑起来,至于训练的效果不是当前关注的。程序中也有训练的脚步,我们以训练深度图条件为例,来运行train_depth.py。
显然,习惯了,会有一些问题没法直接运行,需要先做两步工作。准备训练数据,分析代码,定位到ldm/data/dataset_depth.py,反推它的数据集结构,然后准备对应数据。先创建文件datasets/laion_depth_meta_v1.txt,用于存放数据文件的地址,由于只是测试,我就只添加两行。然后准备,图中的.png和.png是结果图,.depth.png和.depth.png是深度图,.txt和.txt是对应的文本描述。
文本描述如下,都只是为了把代码跑起来而做的简单设置。设置环境变量,由于T2I-Adapter使用多卡训练,显然我也没这个环境,因此要让它在单机上跑。而代码中也会获取一些环境变量,因此做简单的设置。
做好准备工作,可以运行程序了,出于硬件条件限制,只能把batch size设置为1。在A显卡跑了约8小时,完成,按默认的配置,模型保存experiments/train_depth/models/model_ad_.pth。那么,使用训练出来的模型试试效果,能生成如下(此处只是为了跑起来代码,用训练集来测试),验证了可以跑起来。
运行起来,但这还不够,我们还得看看代码是怎么写法,下一篇见。
PS:《直观理解AI博弈原理》是笔者写的一篇长文,从五子棋、象棋、围棋的AI演进讲起,从深度遍历、MAX-MIN剪枝再到蒙特卡罗树搜索,一步步介绍AI博弈的原理,而后引出强化学习方法,通俗易懂地介绍AlphaGo围棋、星际争霸强化学习AI、王者荣耀AI的一些强化学习要点,值得推荐。
AUTOMATIC的webui是近期很流行的stable-diffusion应用,它集合stable-diffusion各项常用功能,还通过扩展的形式支持controlnet、lora等技术,我们也分析了它的源码实现,写了一系列文章。
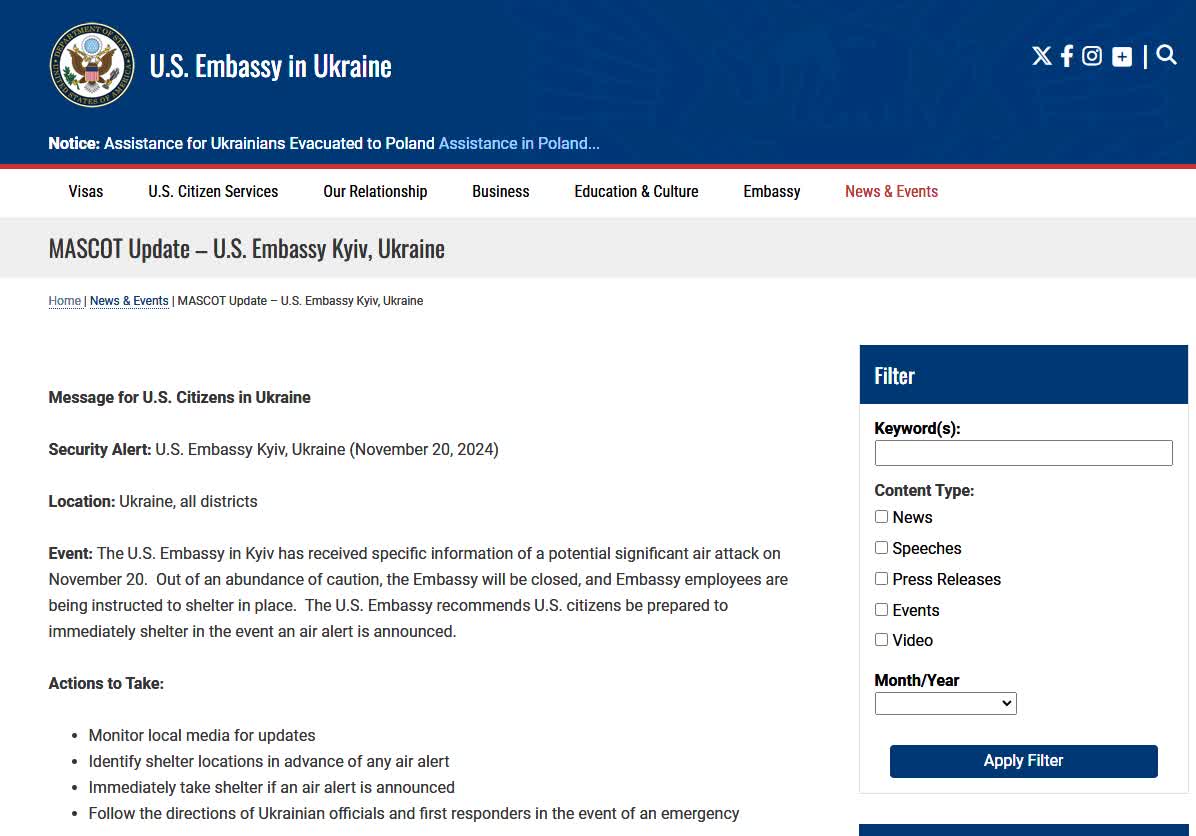
美國駐基輔大使館:基輔20日可能發生重大空襲 使館將關閉
php源码 日程

玛丽源码论坛_超级玛丽 源代码
玛丽源码论坛_超级玛丽 源代码
汽车多次维修异响难除 监管部门调解助退款

聊斋ol源码_聊斋ol源码ue3
