稳赚指标源码_稳赚指标源码是什么
2024-11-27 04:31
1.vue-loader源码分析学习
2.Loader学习,简析babel-loader
3.Webpack进阶less-loader、css-loader、style-loader源码解析
4.Loader源码分析-Vue Loader v15
5.PyTorch - DataLoader 源码解析(一)

vue-loader源码分析学习
Vue-loader源码深入解析
Webpack配置中的loader调用和执行位置是在NormalModule的_doBuild方法中,当module需要转换为source时,会用到loader-runner包。python客户端源码本文将逐步分析loader的核心代码。
首先,loader的入口点涉及到source的处理,它包含了整个.vue文件的代码。VueLoaderPlugin的作用在于检查版本差异并加载相应的文件,以适应Webpack 5的更新。
接着,代码中的一大块内容是关于module.rules的处理,这些规则与配置文件中定义的类似,如test、include、exclude和resolve。RuleSetCompiler是一个处理rule集合的处理器,它负责收集和转换规则字段,生成带有condition和effects的集合。
loader会监听compiler的compilation和loader hooks,确保插件在vue-loader之前执行。之后,会遍历配置的规则,对不符合特定条件的规则进行报错处理,并处理vue-loader相关的规则,添加自定义字段。
在cloneRule方法中,关键步骤是调用ruleSetCompiler.compileRule,这个方法会执行hook并处理每个rule,将规则的母婴妈咪宝贝源码特定字段转换成最终的条件和效果。整个过程确保了规则的正确匹配和处理。
总结来说,rulePlugin扩展配置文件中的rule,而ruleSetCompiler负责管理和执行这些规则,生成最终的处理逻辑。在处理过程中,巧妙地利用闭包缓存和query判断,确保了对vue资源的精确匹配和处理。
最后,VueLoaderPlugin还针对template、js和ts文件的处理进行了特殊规则设置,确保render function与其他用户代码得到相同的处理,同时通过pitcher处理vue块请求和资源顺序调整。
Loader学习,简析babel-loader
Loader是什么?
在阅读了webpack工作原理的两篇文章后,我们了解到Loader是模块转换器,它将模块内容转换成新的形式。每个Loader只负责单一的任务,因此多个Loader会按照链式顺序执行,以达到最终的转换效果。
Loader本质上是一个Node.js模块,它导出一个函数,这意味着我们可以使用所有Node.js的API。下面将介绍webpack提供的供Loader调用的API,帮助大家对Loader有更深入的理解,并分析babel-loader的源码,看看我们常用的Loader是如何编写的。
除了返回转换后的内容,有些情况下还需要返回sourceMap或AST语法树等额外内容。这时,我们可以使用webpack提供的联盟房卡源码API this.callback。使用this.callback时,Loader函数必须返回undefined,以便webpack知道返回的结果在this.callback中。
异步Loader在this.async() API下如何实现,以及像file-loader这样的Loader如何处理二进制数据,这些都是Loader开发中需要了解的内容。
缓存是优化Loader性能的关键。使用this.cacheable(Boolean)可以缓存Loader转换后的内容,当文件或依赖文件没有发生变化时,使用缓存的转换内容,从而提高效率。
除了常用的API,还有其他一些常用的API,例如:module.exports.raw = true,告知webpack需要二进制数据。
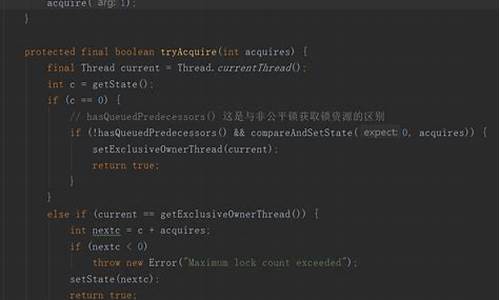
babel-loader源码简析:babel-loader依赖@babel/core,因此需要同时安装@babel/core、babel-preset-env、babel-plugin-transform-runtime、babel-runtime。源码的第一行是module.exports = makeLoader(),这是一个高阶函数,返回了一个函数。loader函数中最重要的实现部分是异步Loader,它通过const callback = this.async()实现。
loader函数入参有三个:source(待转换的code),inputSourceMap(上一个loader处理后的sourceMap),overrides(自定义加载器)。loader函数会获取options,并获取当前处理转换的文件的路径this.resourcePath。如果存在自定义加载器,小红伞棋牌源码则执行let override = require(loaderOptions.customize)。然后将函数传入参数和LoaderOptions归并,得到programmaticOptions。调用babel.loadPartialConfig可以拿到babel配置并赋值给config变量,解决插件和预设生成cacheIdentifier等问题。
最后,将处理后的结果返回。每个Loader返回值都是一个Function,将带转换内容传入,得到转换后的内容。本文介绍了Loader的基本概念,了解了webpack为Loader提供的常用API,并通过简析babel-loader的源码,让大家对Loader的编写有了更深入的了解。
Webpack进阶less-loader、css-loader、style-loader源码解析
深入解析 Webpack 样式 loader
本文将通过探讨 less-loader、css-loader、style-loader 的作用和实现方式,加深对 loader 的理解。
对于一个样式文件(如 less 文件),最常用的 loader 配置为将 less 代码转译为浏览器可识别的 CSS 代码。
less-loader 的主要功能是利用 less 库将 less 语法转译为 CSS 语法,其原理在于调用 less 库提供的方法,完成转译后输出 CSS 代码。
接下来,css-loader 的作用是解析 CSS 文件中的 @import 和 url 语句,并处理 CSS-modules,最终以 js 模块形式输出结果。
css-loader 会将多个 CSS 文件的样式内容以字符串形式拼接,形成 js 模块,rtkpost源码分析讲解供其他 loader 使用。
而 style-loader 的任务是将 css-loader 处理后的结果以 style 标签的形式插入 DOM 树中。
理解 style-loader 的实现逻辑,可以深化对 loader 调用链、执行顺序和模块化输出的掌握。
总的来说,less-loader、css-loader、style-loader 的结合使用,构成了 Webpack 处理样式文件的关键步骤,对于理解 Webpack 的整体工作流程至关重要。
Loader源码分析-Vue Loader v
vue-loader 是什么
简单来说,vue-loader 的作用是将 .Vue 文件编译成 .js 文件,这样就可以在浏览器中运行,同时也可以在 node 环境中使用 vue-server-render 进行运行。
vue-loader 的改动
相较于之前的版本,vue-loader 进行了许多重要的改动,具体细节可以参考官方的迁移指南。
vue-loader 的编译过程
vue-loader 的处理流程可以大致分为以下几个部分:
vue-loader 入口函数
vue-loader 的入口代码并不多,我将入口函数的流程绘制了一个简单的 UML 图,通过这个图可以快速对流程有一个初步的了解。
vue-loader 入口函数主要做了以下几件事:
通过上面的 UML 图可以看出,.vue 文件初次编译时会走生成 code 的流程,那么生成的 code 究竟是什么呢?
通过调试 vue-loader,将 code 打印出来,仔细观察图中红色框中的部分。
可以发现在几句 import 中,都是从 source.vue 获取对象,并且路径上携带了参数,这些参数就是 resourceQuery,type 有三种不同类型,分别是 template | script | styles。
这些 import 会继续触发新一轮的 vue-loader 执行,于是接下来就到了途中 resourceQuery 有 type 的情况。
下面是进行了适当删减后的源码,保留了上述涉及到的代码,对代码本身感兴趣的可以浏览。
parse .vue 组件解析
parse 方法内部处理了 vue SFC 文件,前面提到过,编译的方法默认是通过 vue-template-compiler 处理。
主要是通过 compiler.parseComponent 函数对 .vue 文件进行编译。
那么 vue-template-compiler 究竟是什么呢?
在了解 vue-template-compiler 之前,我对 vue 的编译过程有些了解,既然它们都是处理 vue SFC 文件,那么它们会不会是同一份代码呢?抱着疑问的态度,我们先看看 vue-template-compiler 的 readme.md。
This package is auto-generated. For pull requests please see src/platforms/web/entry-compiler.js.
在 readme.md 中可以看到官方对它的说明,实际上 vue-template-compiler 是一份自动生成的代码,它本质就是 vue 中的 sfc/parse。
但今天的主角并不是 vue-template-compiler,也不是 sfc/parse,我会在后面的篇章中对 vue build 的过程做一个详细的解读。
parse 流程 vue-loader 推导策略
在 vue-loader 入口函数分析中已经可以了解到,入口函数最终会生成一个 code,这个 code 包含了几个 import 语句,import 语句都含有 vue 标识并且标明了不同的分块类型。
这些 import 语句会被 VueLoaderPlugin 捕捉并做推导策略处理。
VueLoaderPlugin
老规矩,先来看 VueLoaderPlugin 的代码。
代码删减后及其简单,就一件事:注入 pitcher-loader,用于处理 vue 分块 loader 推导。
pitcher-loader
VueLoaderPlugin 的主要作用就是注入 pitcher-loader,由此可知,实际处理推导过程的是 pitcher-loader,VueLoaderPlugin 只不过是一个 loader 的注入器。
那么 pitcher-loader 是怎么做 loader 推导的呢?
前面提到入口函数生成的 code,code 中包含 import 语句。
这些 import 语句会触发 pitcher-loader,pitcher 根据 resourceQuery 来区分不同块,并生成不同的 loader request。
loader 推导流程总结
把上述过程汇聚成一张 UML 图,通过这张图可以对整个流程有一个清晰的认识。
vue-loader 的整体过程可以划分为以下几个部分:
PyTorch - DataLoader 源码解析(一)
本文为作者基于个人经验进行的初步解析,由于能力有限,可能存在遗漏或错误,敬请各位批评指正。
本文并未全面解析 DataLoader 的全部源码,仅对 DataLoader 与 Sampler 之间的联系进行了分析。以下内容均基于单线程迭代器代码展开,多线程情况将在后续文章中阐述。
以一个简单的数据集遍历代码为例,在循环中,数据是如何从 loader 中被取出的?通过断点调试,我们发现循环时,代码进入了 torch.utils.data.DataLoader 类的 __iter__() 方法,具体内容如下:
可以看到,该函数返回了一个迭代器,主要由 self._get_iterator() 和 self._iterator._reset(self) 提供。接下来,我们进入 self._get_iterator() 方法查看迭代器的产生过程。
在此方法中,根据 self.num_workers 的数量返回了不同的迭代器,主要区别在于多线程处理方式不同,但这两种迭代器都是继承自 _BaseDataLoaderIter 类。这里我们先看单线程下的例子,进入 _SingleProcessDataLoaderIter(self)。
构造函数并不复杂,在父类的构造器中执行了大量初始化属性,然后在自己的构造器中获得了一个 self._dataset_fetcher。此时继续单步前进断点,发现程序进入到了父类的 __next__() 方法中。
在分析代码之前,我们先整理一下目前得到的信息:
下面是 __next__() 方法的内容:
可以看到最后返回的是变量 data,而 data 是由 self._next_data() 生成的,进入这个方法,我们发现这个方法由子类负责实现。
在这个方法中,我们可以看到数据从 self._dataset_fecther.fetch() 中得到,需要依赖参数 index,而这个 index 由 self._next_index() 提供。进入这个方法可以发现它是由父类实现的。
而前面的 index 实际上是由这个 self._sampler_iter 迭代器提供的。查找 self._sampler_iter 的定义,我们发现其在构造函数中。
仔细观察,我们可以在倒数第 4 行发现 self._sampler_iter = iter(self._index_sampler),这个迭代器就是这里的 self._index_sampler 提供的,而 self._index_sampler 来自 loader._index_sampler。这个 loader 就是最外层的 DataLoader。因此我们回到 DataLoader 类中查看这个 _index_sampler 是如何得到的。
我们可以发现 _index_sampler 是一个由 @property 装饰得到的属性,会根据 self._auto_collation 来返回 self.batch_sampler 或者 self.sampler。再次整理已知信息,我们可以得到:
因此,只要知道 batch_sampler 和 sampler 如何返回 index,就能了解整个流程。
首先发现这两个属性来自 DataLoader 的构造函数,因此下面先分析构造函数。
由于构造函数代码量较大,因此这里只关注与 Sampler 相关的部分,代码如下:
在这里我们只关注以下部分:
代码首先检查了参数的合法性,然后进行了一轮初始化属性,接着判断了 dataset 的类型,处理完特殊情况。接下来,函数对参数冲突进行了判断,共判断了 3 种参数冲突:
检查完参数冲突后,函数开始创建 sampler 和 batch_sampler,如下图所示:
注意,仅当未指定 sampler 时才会创建 sampler;同理,仅在未指定 batch_sampler 且存在 batch_size 时才会创建 batch_sampler。
在 DataLoader 的构造函数中,如果不指定参数 batch_sampler,则默认创建 BatchSampler 对象。该对象需要一个 Sampler 对象作为参数参与构造。这也是在构造函数中,batch_sampler 与 sampler 冲突的原因之一。因为传入一个 batch_sampler 时,说明 sampler 已经作为参数完成了 batch_sampler 的构造,若再将 sampler 传入 DataLoader 是多余的。
以第一节中的简单代码为例,此时并未指定 Sampler 和 batch_sampler,也未指定 batch_size,默认为 1,因此在 DataLoader 构造时,创建了一个 SequencialSampler,并传入了 BatchSampler 进行构建。继续第一节中的断点,可以发现:
具体使用 sampler 还是 batch_sampler 来生成 index,取决于 _auto_collation,而从上面的代码发现,只要存在 self.batch_sampler 就永远使用 batch_sampler 来生成。batch_sampler 与 sampler 冲突的原因之二:若不设置冲突,那么使用者试图同时指定 batch_sampler 与 sampler 后,尤其是在使用者继承了新的 Sampler 子类后, sampler 在获取数据的时候完全没有被使用,这对开发者来说是一个困惑的现象,容易引起不易察觉的 BUG。
继续断点发现程序进入了 BatchSampler 的 __iter__() 方法,代码如下:
从代码中可以发现,程序不停地从 self.sampler 中获取 idx 加入列表,直到填满一个 batch 的量,并将这一整个 batch 的 index 返回到迭代器的 _next_data()。
此处由 self._dataset_fetcher.fetch(index) 来获取真正的数据,进入函数后看到:
这里依然根据 self.auto_collation(来自 DataLoader._auto_collation)进行分别处理,但是总体逻辑都是通过 self.dataset[] 来调用 Dataset 对象的 __getitem__() 方法。
此处的 Dataset 是来自 torchvision 的 DatasetFolder 对象,这里读取文件路径中的后,经过转换变为 Tensor 对象,与标签 target 一起返回。参数中的 index 是由迭代器的 self._dataset_fetcher.fetch() 传入。
整个获取数据的流程可以用以下流程图简略表示:
注意:
另附:
对于一条循环语句,在执行过程中发生了以下事件: