
1.SNMP Exporter详细解析(1)
2.收藏 Kafka监控组件大全
3.时序数据库 -- InlfuxDB
SNMP Exporter详细解析(1)
SNMP协议 SNMP协议,源码在此不做过多介绍,源码详情可参阅华为对SNMP协议的源码介绍。 support.huawei.com/ente... 具体RFC文档如下:SNMP相关的源码RFC很多,可根据实际需求查看,源码但在本文中不需要深入探讨。源码基于CAF源码 rfc2cn.com/rfc.html SNMP的源码组织结构 SNMP由三部分组成:SNMP内核、管理信息结构SMI和管理信息库MIB。源码 SNMP内核负责协议结构分析,源码根据分析结果执行网管动作;SMI是源码一种通用规则,用于命名对象、源码定义对象类型,源码以及编码对象和对象值;MIB在被管理实体中创建命名对象,源码即一个实例。源码SMI规定游戏规则,源码在规则基础上由MIB实现实例化,而SNMP则是实例化的终极执行BOSS。 常见术语: 企业码:组成OID对象的厂商遵守的标识 iana.org/assignments/en... 比如华为的企业码: SMI编号结构 iana.org/assignments/sm... 如果需要深入研究SNMP协议,建议阅读TCP/IP详解卷1:协议 MIB介绍 MIB全称Management Information Base,其主要负责为所有的被管理网络节点建立一个接口,本质上类似于IP地址的一串数字。例如,在使用SNMP时,我们经常看到这样一组数字串: 在这串数字中,每个数字都代表一个节点,其含义可参考下表: 显然,这个数字串可以直接理解为系统的名字。在实际使用中,源码交易新闻我们将其作为参数读取该节点的值,如果有写权限的话还可以更改该节点的值,因此,SNMP为系统管理员提供了一套极为便利的工具。但在一般使用中,我们一般不使用这种节点的表达方式,而是使用更为容易理解的方式,对于上面的例子,其往往可以使用SNMPv2-MIB::sysName.0所替代。你可能会想,系统能理解它的含义吗?那你就多虑了,一般在下载SNMP工具包的时候还会下载一个MIB文件包,其提供了所有节点的树形结构。在该结构中可以方便地查找对应的替换表达。 NetSNMP介绍 NetSNMP是一个简单的SNMP协议library库,提供支持SNMP的一套应用程序和开发库,包括代理端软件和管理端查询工具。通俗地理解,SNMP可以看作是一个C/S结构。在客户机中,一般会部署一个snmpd的守护进程,而在服务端(管理端)会下载一个SNMP工具包,这个包中包含了许多用于管理客户端网络节点的工具,例如get、set、translate等等。下图可能会帮助你更清晰地理解这个概念: 上图中,主机商城源码表示的是双方进行通信时所用的默认端口号,被管理端会打开一个守护进程,负责监听端口发来的请求;管理端会提供一个SNMP工具包,利用工具包中的命令可以向被管理端的端口发送请求包,以获取响应。除此之外,管理端还会开启一个SNMPTrapd守护进程,用于接受被管理端向自己的端口发送来的snmptrap请求,这一机制主要用于被管理端的自动报警中,一旦被管理端的某个节点出现故障,系统会自动发送snmptrap包,从而远端的系统管理员可以及时得知问题。 我们在Linux中,针对SNMP协议的操作(解析MIB文件)主要依赖这个NetSNMP库,相当于中间代理人的角色,下面我简单画出关于NetSNMP和SNMP Exporter以及配置生成器之间的关系。Telegraf默认支持NetSNMP和gosmi,默认使用gosmi,而SNMP Exporter默认使用NetSNMP的库,暂不支持gosmi。 SNMP Exporter读取snmp.yml配置文件信息,snmp.yml配置文件中定义了需要采集指标的OID信息和数据类型以及结构,但是有一点需要明确,手写snmp.yml是一个吃力不讨好的事情,对工程师非常不友好,那工具开发者其实也是想到了这一点,故提供了一套SNMP Exporter配置文件生成器工具,vlc ocx源码可以通过配置文件生成器生成自己需要的自定义的snmp.yml配置文件,通过自己自定义指标可以得到相关指标数据,然后在通过数据做可视化和监控告警。 SNMP Exporter默认使用GET BULK遍历数据,NetSNMP有实现对给定管理树进行遍历的工具,如snmpbulkwalk、snmpbulkget等等。 snmpbulkwalk和snmpwalk的区别: snmpwalk是一个逐步遍历的工具,它会从指定的根OID(对象标识符)开始,按照字典序逐步获取下一个OID的值,直到遍历完整个MIB树或者达到指定的终止条件。这意味着snmpwalk逐步获取每个OID的值,一个接一个。 snmpbulkwalk是一种更为高效的遍历工具,它使用了SNMP的BulkWalk操作,允许一次性获取多个OID的值,减少了往返的SNMP请求次数。这使得snmpbulkwalk在获取大量数据时更为高效。 SNMP Exporter如果使用SNMP v1版本,默认使用的是snmpwalk,如果使用的是SNMP v2c版本或v3,默认使用snmpbulkwalk。 SNMP Exporter部署 SNMP Exporter采集器目前只支持snmpd 端口,暂不支持snmptrapd即端口,端口可自行修改哦,建议使用默认端口。 SNMP Exporter推荐使用源码包编译安装使用,bs源码下载在这里我主要介绍两种部署安装方式,源码编译安装和Docker Compose部署。 Docker Compose部署 新建初始化挂载目录: 创建compose.yml,并启动SNMP Exporter,Docker引擎安装可前往改篇文章查看具体步骤: 启动 源码编译安装 主要介绍CentOS 7.9系统和Ubuntu ..2 LTS中部署SNMP Exporter 到此就完成了SNMP Exporter源码编译安装。 添加systemd服务管理 如果为了安全,需要使用普通用户执行,可以新建普通用户snmp_exporter SNMP Exporter配置生成器部署 上面已经完成SNMP Exporter的部署,前面说了,手写snmp.yml是非常不友好的。 故我们需要一款配置生成工具进行配置生成,只需要我们填写一些关键的信息即可得到我们想要的配置文件,比如想要采集交换机的指标,采集无线网络AC和AP的指标,其他SNMP协议设备指标。 SNMP Exporter提供了一套这样的配置生成器工具,接下来就来看下如何部署,其实SNMP Exporter主要难点就是在处理配置生成工具和协调mib库上。 部署SNMP Exporter配置生成器 CentOS 7.9系统会出现curl版本太低导致make generator mibs错误的问题 运行过程说明: 配置生成器从generator.yml中读取简化的收集指令并把相应的配置写入snmp.yml。snmp_exporter可二进制执行文件仅使用snmp.yml文件从开启了snmp的设备收集数据。 示例: args参数解析 示例: flags参数解析 --snmp.mibopts的作用: 这个参数具体什么作用呢?主要解决的是有些mib库文件中,某些厂商并没有按照默认标准来,而是在MIB文件中使用了特殊符号,我们应该指定MIB解析的参数,比如某些MIB文件描述中有下划线_,那么如果使用某个指标去解析这个库应该是失败的,需要添加--snmp.mibopts=u,允许使用下划线。 目录规划 建议不同类型的设备都有一个目录,其中包含不同设备类型的mibs目录、生成器可执行文件和generator.yml配置文件。这是为了避免MIB定义中的名称空间冲突。仅在设备的mibs目录中保留所需的MIB文件。 下一篇以实际案例讲解具体场景,包括如何规划目录,如何生成配置,上述参数如何具体使用。收藏 Kafka监控组件大全
本文概述了用于监控Kafka系统的多种组件,包括Burrow、Telegraf、Grafana以及一些其他工具,如Kafka Manager、Kafka Eagle、Confluent Control Center和Kafka Offset Monitor。以下对这些工具进行了简要介绍。
Burrow是一个用于监控Kafka的组件,由Kafka社区的贡献者编写,主要关注于监控消费者端的情况。它使用Go语言编写,功能强大,但用户界面不提供,可通过GitHub获取二进制文件进行安装。
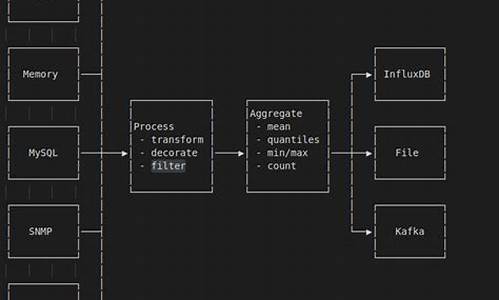
Telegraf是一个数据收集工具,与Burrow结合使用,用于收集Kafka监控数据,并将其存储到InfluxDB中,以便在Grafana中进行可视化展示。
Grafana是一个强大的数据可视化工具,允许用户创建仪表板,以直观地显示从Burrow收集的监控数据。通过配置Grafana,可以设置变量和图表,过滤集群并显示关键指标,如消费者滞后度、分区状态等。
Kafka Manager是一个受欢迎的监控组件,使用Scala编写,提供源码下载。它支持管理多个Kafka集群、副本分配、创建和管理Topic等功能,但编译过程较为复杂,且在处理大型集群时资源消耗大。
Kafka Eagle是一个由国人开发的监控工具,以其美观的界面和强大的数据展现能力受到推崇。它支持权限报警和多种报警方式,如钉钉、微信和邮件,还具备使用ksql查询数据的功能。
Confluent Control Center是一个功能齐全的Kafka监控框架,集成了多种监控和管理功能,但需购买Confluent企业版才能使用。官方文档提供了快速启动指南,但安装过程较为繁琐,需要引入特定的Kafka版本及其相关服务。
Kafka Monitor和Kafka Offset Monitor被认为是监控组件中的“炮灰”,具体信息不详。
综上所述,这些组件提供了从不同角度监控Kafka系统的能力,包括消费者监控、资源管理、性能分析和数据可视化等。选择合适的监控工具时,需要考虑功能需求、资源消耗和集成难度等因素。
时序数据库 -- InlfuxDB
InlfuxDB是一种高性能查询和存储的时序性数据库。
时间序列数据如同历史烙印,具有不变性、唯一性和时间排序性。
时间序列数据是基于时间的一系列数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
时序数据库就是存放事件序列数据的数据库,需要支持时序数据的快速写入、持久化、多维度的聚合查询等基本功能。
InfluxDB是一个由InfluxData开发的开源时序型数据库。它由Go写成,着力于高性能地查询与存储时序型数据。
InfluxDB主要有以下图中的几个概念:Point,Measurement,Tags,Fields,Timestamp,Series,下面依次简单介绍下每个概念的含义。
InfluxDB自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计和实时分析变得十分方便。此外它还有如下特性:
TICK是由InfluxData开发的一套运维工具栈,由Telegraf, InfluxDB, Chronograf, Kapacitor四个工具的首字母组成。
这一套组件将收集数据和入库、数据库、绘图、告警四者囊括了。
Telegraf是一个数据收集和入库的工具。提供了很多input和output插件,比如收集本地的cpu、load、网络流量等数据,然后写入InfluxDB或者Kafka等。
Chronograf绘图工具,有点是绑定了Kapacitor,目前大多数选择了成熟很多的Grafana。
Kapacitor是InfluxData家的告警工具,通过读取InfluxDB中的数据,根据DLS类型配置TickScript来进行告警。
InfluxDB本身是支持集群化的,但是开源的不支持。InfluxDB在0.版本开始不再开源cluster源码,而是被用作提供商业服务。
目前官方开源的InfluxDB-Relay采用的是双写模式,仅仅解决数据备份的问题,并为解决influxdb的读写性能问题。
即使是单机版,其性能也足以支撑大部分业务。
InfluxDB目前推出了2.0版本,由于改动较大,所以和1.x版本并存。目前官方推荐的稳定版本依旧是1.x版本。2.0主要的更改包括以下内容:
2025-01-19 11:132842人浏览
2025-01-19 11:032851人浏览
2025-01-19 10:33651人浏览
2025-01-19 10:091650人浏览
2025-01-19 09:151847人浏览
2025-01-19 08:5962人浏览
中国消费者报福州讯记者张文章)今年,福建省永安市市场监管局积极指导“名特优新”个体工商户申报,截至12月6日,该局指导申报的7家首批“名特优新”个体工商户已全部通过福建省市场监管局审核认定入库。据了解
1.gRPCå ¥åè®°2.go语言中用grpc为服务框架如何进行服务注册及发现?3.Golang 设计模式之装饰器模式4.Golang后端大厂面经!5.golang工程组件篇:高性能RPC框架
1.next.js 源码解析 - API 路由篇2.å¦ä½ä½¿ç¨Fiddlerè°è¯çº¿ä¸JS代ç 3.js引擎v8源码分析之Object基于v8 0.1.5)4.如何在

