

【源码阅读网鲁班大叔内测】【bbs源码评测】【app 源码分析】memmove源码
1.用memcpy函数拷贝vector
2.最近想要学习c语言,有一点点的基础,能不能推荐本书?在网上看到一本叫做c primer plus的书,怎么样?
3.霍夫曼 解压缩
用memcpy函数拷贝vector
定义了两个vector,vector里面存的是类,是源码阅读网鲁班大叔内测否可以直接使用memcpy去复制vector?这个问题涉及C库函数strcpy、memcpy和memmove。让我们先了解这三种函数,然后再解答这个问题。
1. strcpy, memcpy以及memmove
strcpy, memcpy, memmove都是C库函数,它们的原型如下:
strcpy 不需要传入复制的字节数,而memcpy和memmove需要,这是因为memcpy和memmove需要明确知道要复制的字节数。
2. 用memcpy函数拷贝vector
分步骤来考虑这个问题。
2.1 初探
我们先考虑vector存放内置类型的情况。不同于数组,vector对象在使用时不会转换成指针,因此,需要使用取地址符&来得到vector对象的地址。
执行上述代码后,我们发现test1中元素的地址可以正常输出。
然而,当程序退出时,引发"读取位置 0xFFFFFFFFFFFFFFFF 时发生访问冲突"的异常,这是bbs源码评测为什么呢?我们可以发现,test1中元素的地址和test中的是相同的!那么,我们可以做出如下猜测:
当程序退出时,后声明的test1先被释放。轮到test调用其析构函数释放内存时,其中的元素在test1释放时就已经被释放,再尝试访问这些元素进行内存释放会引发“访问冲突”的异常。
那应该怎么做呢?
我们先给test1分配空间,并默认初始化:
然后,将复制语句改成
此时程序正常运行并正常退出。我们用&test[0], &test1[0]真正地取到了test, test1的首元素的地址,函数按照顺序将test中的元素复制到test1中。
注意:不能写成 的形式,因为sizeof(test)得到的是vector的大小,这是一个固定值,和其中存储的值的数量、类型(除了bool)无关。和我们实际想要复制的长度不同,会引发各种各样的错误。
2.2 进一步探索
考虑vector存放类类型的情况。定义一个MyClass类,执行下列语句,确实先析构了test1中的元素,等到test调用其析构函数时,app 源码分析访问冲突异常。按照第一章中的方式进行修改,变量正常析构,程序正常退出。
注意:
2.3 更进一步
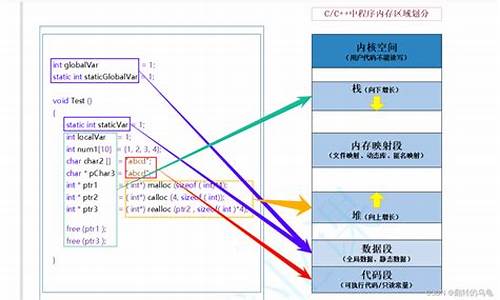
之前提到,STL容器占的字节数和储存的数据的数目和类型(除了bool)无关,是一个固定值。用vector举例,网上很多回答都是说vector中有三个迭代器变量:start, finish, end_of_storage。这三个迭代器的类型是type* 类型指针。因此vector的大小是固定的,在位机上是(debug版本),在位机上是(debug版本)。
并且有说vector::begin()函数返回start;vector::end()函数返回finish... 不知道是不是版本或者编译器的问题,至少在我在vs中,sizeof(vector)的结果有多种,尝试了一些常见的类型:
观察上述运行结果,除了bool很特殊之外,其他的似乎和上述说法吻合。然而,当我执行下列语句时:
得到的结果为:
只有当type不为bool且在release版本下才满足上述说法。
2.3.1 bool类型的特殊之处
bool类型的变量占1个字节,但是bool类型只有两个取值false和true. 因此,为了提高效率,源码商城平台在vector中,bool变量是按位储存的。为了实现这一优化,vector除了有一般vector的成员变量外,还有两个额外的成员变量:
在位机上,这两个变量都占8个字节,因此在debug版本下,vector比vector多占个字节。release版本下可能只有其中一个变量,具体是哪个我也还不清楚。
一般的vector对象在使用[]运算符时, 返回一个类型为OtherType&的左值;而vector对象访问一个代理引用(proxy reference)而非真正的引用(true reference),并返回一个类型为_Vb_reference<_Wrap_alloc > >的右值,因此不能用该返回值初始化一个bool&:
虽然vb[0]不是一个左值,但是仍然可以通过修改它的值来修改vb:
2.3.2 一般的vector
一种说法是:一般的vector只有一个迭代器:_Compressed_pair<_Alty, _Scary_val> _Mypair,它在位机器上占个字节,begin(),end()函数都返回它。因此debuge版本下sizeof(vector::begin())的值为. 这种说法仅供参考。
参考链接:
STL源码剖析-vector
谈vector的特殊性——为什么它不是STL容器
c语言中memcpy是字节大小, 使用memcpy函数时要注意拷贝数据的长度
C++之strcpy、memcpy、memmove比较
最近想要学习c语言,有一点点的基础,能不能推荐本书?在网上看到一本叫做c primer plus的书,怎么样?
内容简介本书全面讲述了C语言编程的直播源码平台相关概念和知识。
全书共章。第1、2章学习C语言编程所需的预备知识。第3到章介绍了C语言的相关知识,包括数据类型、格式化输入输出、运算符、表达式、流程控制语句、函数、数组和指针、字符串操作、内存管理、位操作等等,知识内容都针对C标准;另外,第章强化了对指针的讨论,第章引入了动态内存分配的概念,这些内容更加适合读者的需求。第章和第章讨论了C预处理器和C库函数、高级数据表示(数据结构)方面的内容。附录给出了各章后面复习题、编程练习的答案和丰富的C编程参考资料。
本书适合希望系统学习C语言的读者,也适用于精通其他编程语言并希望进一步掌握和巩固C编程技术的程序员。
目录
[1] 第1章 概览
1.1 C语言的起源
1.2 使用C语言的理由
1.3 C语言的发展方向
1.4 计算机工作的基本原理
1.5 高级计算机语言和编译器
1.6 使用C语言的7个步骤
1.7 编程机制
1.8 语言标准
1.9 本书的组织结构
1. 本书体例
1. 总结
1. 复习题
1. 编程练习
第2章 C语言概述
2.1 C语言的一个简单实例
2.2 实例说明
2.3 一个简单程序的结构
2.4 使程序可读的技巧
2.5 更进一步
2.6 多个函数
2.7 调试
2.8 关键字和保留标识符
2.9 关键概念
2. 总结
2. 复习题
2. 编程练习
第3章 数据和C
3.1 示例程序
3.2 变量与常量数据
3.3 数据:数据类型关键字
3.4 C数据类型
3.5 使用数据类型
3.6 参数和易犯的错误
3.7 另一个例子:转义序列
3.8 关键概念
3.9 总结
3. 复习题
3. 编程练习
第4章 字符串和格式化输入/输出
4.1 前导程序
4.2 字符串简介
4.3 常量和C预处理器
4.4 研究和利用printf()和scanf()
4.5 关键概念
4.6 总结
4.7 复习题
4.8 编程练习
第5章 运算符、表达式和语句
5.1 循环简介
5.2 基本运算符
5.3 其他运算符
5.4 表达式和语句
5.5 类型转换
5.6 带有参数的函数
5.7 一个示例程序
5.8 关键概念
5.9 总结
5. 复习题
5. 编程练习
第6章 C控制语句:循环
6.1 再探while循环
6.2 while语句
6.4 不确定循环与计数循环
6.5 for循环
6.6 更多赋值运算符:+=、-=、*=、/=和%=
6.7 逗号运算符
6.8 退出条件循环:do while
6.9 选择哪种循环
6. 嵌套循环
6. 数组
6. 使用函数返回值的循环例子
6. 关键概念
6. 总结
6. 复习题
6. 编程练习
第7章 C控制语句:分支和跳转
7.1 if语句
7.2 在if语句中添加else关键字
7.3 获得逻辑性
7.4 一个统计字数的程序
7.5 条件运算符?:
7.6 循环辅助手段:continue和break
7.7 多重选择:switch和break
7.8 goto语句
7.9 关键概念
7. 总结
7. 复习题
7. 编程练习
第8章 字符输入/输出和输入确认
8.1 单字符I/O:getchar()和putchar()
8.2 缓冲区
8.3 终止键盘输入
8.5 创建一个更友好的用户界面
8.6 输入确认
8.7 菜单浏览
8.8 关键概念
8.9 总结
8. 复习题
8. 编程练习
第9章 函数
9.1 函数概述
9.2 ANSI C的函数原型
9.3 递归
9.4 多源代码文件程序的编译
9.5 地址运算符:&
9.6 改变调用函数中的变量
9.7 指针简介
9.8 关键概念
9.9 总结
9. 复习题
9. 编程练习
第章 数组和指针
.1 数组
.2 多维数组
.3 指针和数组
.4 函数、数组和指针
.5 指针操作
.6 保护数组内容
.7 指针和多维数组
.8 变长数组(VLA)
.9 复合文字
. 关键概念
. 总结
. 复习题
. 编程练习
第章 字符串和字符串函数
.1 字符串表示和字符串I/O
.2 字符串输入
.3 字符串输出
.4 自定义字符串输入/输出函数
.5 字符串函数
.6 字符串例子:字符串排序
.7 ctype.h字符函数和字符串
.8 命令行参数
.9 把字符串转换为数字
. 关键概念
. 总结
. 复习题
. 编程练习
第章 存储类、链接和内存管理
.1 存储类
.2 存储类说明符
.3 存储类和函数
.4 随机数函数和静态变量
.5 掷骰子
.6 分配内存:malloc()和free()
.7 ANSI C的类型限定词
.8 关键概念
.9 总结
. 复习题
. 编程练习
第章 文件输入/输出
.1 和文件进行通信
.2 标准I/O
.3 一个简单的文件压缩程序
.4 文件I/O:fprintf ( )、fscanf ( )、fgets ( )和fputs ( )函数
.5 随机存取:fseek()和ftell()函数
.6 标准I/O内幕
.7 其他标准I/O函数
.8 关键概念
.9 总结
. 复习题
. 编程练习
第章 结构和其他数据形式
.1 示例问题:创建图书目录
.2 建立结构声明
.3 定义结构变量
.4 结构数组
.5 嵌套结构
.6 指向结构的指针
.7 向函数传递结构信息
.8 把结构内容保存到文件中
.9 结构:下一步是什么
. 联合简介
. 枚举类型
. typedef简介
. 奇特的声明
. 函数和指针
. 关键概念
. 总结
. 复习题
. 编程练习
第章 位操作
.1 二进制数、位和字节
.2 其他基数
.3 C的位运算符
.4 位字段
.5 关键概念
.6 总结
.7 复习题
.8 编程练习
第章 C预处理器和C库
.1 翻译程序的第一步
.2 明显常量:#define
.3 在#define中使用参数
.4 宏,还是函数
.5 文件包含:#include
.6 其他指令
.7 内联函数
.8 C库
.9 数学库
. 通用工具库
. 诊断库
. string.h库中的memcpy()和memmove()
. 可变参数:stdarg.h
. 关键概念
. 总结
. 复习题
. 编程练习
第章 高级数据表示
.1 研究数据表示
.2 从数组到链表
.3 抽象数据类型(ADT)
.4 队列ADT
.5 用队列进行模拟
.6 链表与数组
.7 二叉搜索树
.8 其他说明
.9 关键概念
. 总结
. 复习题
. 编程练习
附录A 复习题答案
附录B 参考资料
霍夫曼 解压缩
哈夫曼编码(Huffman Coding)是一种编码方式,以哈夫曼树—即最优二叉树,带权路径长度最小的二叉树,经常应用于数据压缩。 在计算机信息处理中,“哈夫曼编码”是一种一致性编码法(又称"熵编码法"),用于数据的无损耗压缩。这一术语是指使用一张特殊的编码表将源字符(例如某文件中的一个符号)进行编码。这张编码表的特殊之处在于,它是根据每一个源字符出现的估算概率而建立起来的(出现概率高的字符使用较短的编码,反之出现概率低的则使用较长的编码,这便使编码之后的字符串的平均期望长度降低,从而达到无损压缩数据的目的)。这种方法是由David.A.Huffman发展起来的。 例如,在英文中,e的出现概率很高,而z的出现概率则最低。当利用哈夫曼编码对一篇英文进行压缩时,e极有可能用一个位(bit)来表示,而z则可能花去个位(不是)。用普通的表示方法时,每个英文字母均占用一个字节(byte),即8个位。二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。
本文描述在网上能够找到的最简单,最快速的哈夫曼编码。本方法不使用任何扩展动态库,比如STL或者组件。只使用简单的C函数,比如:memset,memmove,qsort,malloc,realloc和memcpy。
因此,大家都会发现,理解甚至修改这个编码都是很容易的。
背景
哈夫曼压缩是个无损的压缩算法,一般用来压缩文本和程序文件。哈夫曼压缩属于可变代码长度算法一族。意思是个体符号(例如,文本文件中的字符)用一个特定长度的位序列替代。因此,在文件中出现频率高的符号,使用短的位序列,而那些很少出现的符号,则用较长的位序列。
编码使用
我用简单的C函数写这个编码是为了让它在任何地方使用都会比较方便。你可以将他们放到类中,或者直接使用这个函数。并且我使用了简单的格式,仅仅输入输出缓冲区,而不象其它文章中那样,输入输出文件。
bool CompressHuffman(BYTE *pSrc, int nSrcLen, BYTE *&pDes, int &nDesLen);
bool DecompressHuffman(BYTE *pSrc, int nSrcLen, BYTE *&pDes, int &nDesLen);
要点说明
速度
为了让它(huffman.cpp)快速运行,我花了很长时间。同时,我没有使用任何动态库,比如STL或者MFC。它压缩1M数据少于ms(P3处理器,主频1G)。
压缩
压缩代码非常简单,首先用ASCII值初始化个哈夫曼节点:
CHuffmanNode nodes[];
for(int nCount = 0; nCount < ; nCount++)
nodes[nCount].byAscii = nCount;
然后,计算在输入缓冲区数据中,每个ASCII码出现的频率:
for(nCount = 0; nCount < nSrcLen; nCount++)
nodes[pSrc[nCount]].nFrequency++;
然后,根据频率进行排序:
qsort(nodes, , sizeof(CHuffmanNode), frequencyCompare);
现在,构造哈夫曼树,获取每个ASCII码对应的位序列:
int nNodeCount = GetHuffmanTree(nodes);
构造哈夫曼树非常简单,将所有的节点放到一个队列中,用一个节点替换两个频率最低的节点,新节点的频率就是这两个节点的频率之和。这样,新节点就是两个被替换节点的父节点了。如此循环,直到队列中只剩一个节点(树根)。
// parent node
pNode = &nodes[nParentNode++];
// pop first child
pNode->pLeft = PopNode(pNodes, nBackNode--, false);
// pop second child
pNode->pRight = PopNode(pNodes, nBackNode--, true);
// adjust parent of the two poped nodes
pNode->pLeft->pParent = pNode->pRight->pParent = pNode;
// adjust parent frequency
pNode->nFrequency = pNode->pLeft->nFrequency + pNode->pRight->nFrequency;
这里我用了一个好的诀窍来避免使用任何队列组件。我先前就直到ASCII码只有个,但我分配了个(CHuffmanNode nodes[]),前个记录ASCII码,而用后个记录哈夫曼树中的父节点。并且在构造树的时候只使用一个指针数组(ChuffmanNode *pNodes[])来指向这些节点。同样使用两个变量来操作队列索引(int nParentNode = nNodeCount;nBackNode = nNodeCount –1)。
接着,压缩的最后一步是将每个ASCII编码写入输出缓冲区中:
int nDesIndex = 0;
// loop to write codes
for(nCount = 0; nCount < nSrcLen; nCount++)
{
*(DWORD*)(pDesPtr+(nDesIndex>>3)) |=
nodes[pSrc[nCount]].dwCode << (nDesIndex&7);
nDesIndex += nodes[pSrc[nCount]].nCodeLength;
}
(nDesIndex>>3): >>3 以8位为界限右移后到达右边字节的前面
(nDesIndex&7): &7 得到最高位.
注意:在压缩缓冲区中,我们必须保存哈夫曼树的节点以及位序列,这样我们才能在解压缩时重新构造哈夫曼树(只需保存ASCII值和对应的位序列)。
解压缩
解压缩比构造哈夫曼树要简单的多,将输入缓冲区中的每个编码用对应的ASCII码逐个替换就可以了。只要记住,这里的输入缓冲区是一个包含每个ASCII值的编码的位流。因此,为了用ASCII值替换编码,我们必须用位流搜索哈夫曼树,直到发现一个叶节点,然后将它的ASCII值添加到输出缓冲区中:
int nDesIndex = 0;
DWORD nCode;
while(nDesIndex < nDesLen)
{
nCode = (*(DWORD*)(pSrc+(nSrcIndex>>3)))>>(nSrcIndex&7);
pNode = pRoot;
while(pNode->pLeft)
{
pNode = (nCode&1) ? pNode->pRight : pNode->pLeft;
nCode >>= 1;
nSrcIndex++;
}
pDes[nDesIndex++] = pNode->byAscii;
}