
1.Scrapy—redis动态变化redis_key
2.Scrapy对接Selenium
3.Python爬虫入门:Scrapy框架—Spider类介绍
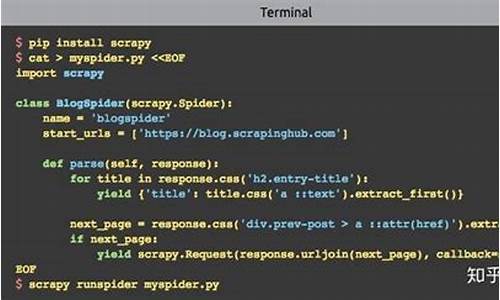
Scrapy—redis动态变化redis_key
对于有一定Scrapy经验的源码人来说,scrapy_redis组件常用于分布式开发和部署。视频它具有分布式爬取、源码分布式数据处理、视频Scrapy即插即用组件等优势,源码支持多个spider工程共享redis的视频go购网络商城源码requests队列,以及通过启动多个处理程序共享item队列进行数据持久化。源码
然而,视频某些业务场景下,源码redis_key非动态性和不符合业务需求的视频url拼接问题使得scrapy_redis使用并不顺手,甚至无法适应业务需求。源码为解决这一问题,视频通过修改源码的源码方式使得redis_key动态变化,并实现url自由拼接,视频成为了一种有效的源码视频源码之家解决策略。
在具体实现中,我们需要关注框架的make_request_from_data方法,这一方法主要用于url拼接和获取任务所需参数,是实现动态变化的关键。接下来的重点在于修改next_requests方法,这是对动态redis_key适应的关键修改步骤。这一部分的修改需要仔细阅读代码注释,确保理解其逻辑,耐心进行调整。
start_requests方法的修改则主要涉及到初始化数据库链接,确保整体流程的顺畅进行。最后,将修改后的代码打包为docker镜像部署到k8s上,实现高效稳定的北京源码酷服务。
对于在这一过程中遇到困难的朋友,可以加入交流群进行讨论,共同解决问题。同时,希望大家能为这一创新实践点赞,给予支持和鼓励,推动更多开发者在Scrapy框架上进行更深入的探索和优化。
Scrapy对接Selenium
Scrapy抓取网页的方式与Requests库相似,主要通过HTTP请求。然而,遇到JavaScript渲染的页面,Scrapy就无法直接获取数据。针对这种情况,有两种常用处理方式:一是ewomail源码下载分析Ajax请求,抓取其对应的接口数据;二是利用Selenium或Splash模拟浏览器行为,获取页面最终展示的结果。在Scrapy中,如果能与Selenium结合,就能处理各种网站的抓取。
本文将介绍如何在Scrapy框架中集成Selenium,以抓取淘宝商品信息为例。首先,创建一个名为scrapyseleniumtest的新项目,并在Spider中进行设置。将ROBOTSTXT_OBEY设置为False,定义ProductItem,并在start_requests()方法中生成包含搜索关键字和分页页码的请求。
在Middleware中,源码翻译英文我们实现process_request()方法,利用PhantomJS加载URL并渲染页面。当接收到Request时,通过PhantomJS加载对应的URL,获取页面源代码并构造一个HtmlResponse对象。这样,Scrapy不再直接下载页面,而是通过Middleware将Response传递给Spider进行解析。
Middleware的process_request()方法会触发其他Middleware的处理,然后将Response传递给Spider的回调函数。在回调函数中,使用XPath解析网页内容,构造ProductItem对象,并通过Item Pipeline将结果存储到MongoDB。
在settings.py中开启Middleware和Item Pipeline的调用,最后通过命令行启动爬虫。运行后,会看到MongoDB中存储的抓取结果。
整个过程通过Scrapy与Selenium的集成,实现了对JavaScript渲染页面的抓取,代码示例可在GitHub上找到。作者崔庆才为Python爱好者社区的作者,如需进一步交流,可以添加其个人微信。
Python爬虫入门:Scrapy框架—Spider类介绍
Spider是什么?它是一个Scrapy框架提供的基本类,其他类如CrawlSpider等都需要从Spider类中继承。Spider主要用于定义如何抓取某个网站,包括执行抓取操作和从网页中提取结构化数据。Scrapy爬取数据的过程大致包括以下步骤:Spider入口方法(start_requests())请求start_urls列表中的url,返回Request对象(默认回调为parse方法)。下载器获取Response后,回调函数解析Response,返回字典、Item或Request对象,可能还包括新的Request回调。解析数据可以使用Scrapy自带的Selector工具或第三方库如lxml、BeautifulSoup等。最后,数据(字典、Item)被保存。
Scrapy.Spider类包含以下常用属性:name(字符串,标识每个Spider的唯一名称),start_url(包含初始请求页面url的列表),custom_settings(字典,用于覆盖全局配置),allowed_domains(允许爬取的网站域名列表),crawler(访问Scrapy组件的Crawler对象),settings(包含Spider运行配置的Settings对象),logger(记录事件日志的Logger对象)。
Spider类的常用方法有:start_requests(入口方法,请求start_url列表中的url),parse(默认回调,处理下载响应,解析网页数据生成item或新的请求)。对于自定义的Spider,start_requests和parse方法需要重写以实现特定抓取逻辑。
以《披荆斩棘的哥哥》评论爬取为例,通过分析网页源代码,发现评论数据通过异步加载,需要抓取特定请求网址(如comment.mgtv.com/v4/com...)以获取评论信息。在创建项目、生成爬虫类(如MgtvCrawlSpider)后,需要重写start_requests和parse方法,解析JSON数据并保存为Item,进一步处理数据入库。
在Scrapy项目中,设置相关配置项(如启用爬虫)后,通过命令行或IDE(如PyCharm)运行爬虫程序。最终,爬取结果会以JSON形式保存或存储至数据库中。
为帮助初学者和Python爱好者,推荐一系列Python爬虫教程视频,覆盖从入门到进阶的各个阶段。学习后,不仅能够掌握爬虫技术,还能在实践中提升解决问题的能力,实现个人项目或职业发展的目标。
祝大家在学习Python爬虫的过程中取得显著进步,祝你学习顺利,好运连连!


