【libevent 源码安装】【ce源码改成dll】【DL 645规约 源码】可变形卷积源码_可变形卷积代码
1.单目3D目标检测
2.deformable变形卷积pytorch实现(第二节deformable_conv2d 实现一)
3.Yolov8魔术师:卷积变体大作战,可变涨点创新对比实验,形卷提供CVPR2023、积源卷积ICCV2023等改进方案
4.图像分割之U-Net
5.更灵活、变形有个性的代码卷积——可变形卷积(Deformable Conv)
单目3D目标检测
单目3D目标检测是计算机视觉领域中的一项重要任务,旨在识别出目标的可变libevent 源码安装类别以及在相机坐标系下的精确位置。这个过程通常分为三个关键部分:确定目标类别、形卷获取边界框信息(高度、积源卷积宽度、变形长度、代码位置坐标、可变朝向角度)和回归目标的形卷八个关键点坐标。本文将详细阐述这一技术的积源卷积实现流程和关键组件。
首先,变形单目3D目标检测系统通常包含一个主干网络(如DLA-),代码该网络用于提取特征并生成目标中心点的热力图,这是检测的基础。热力图的生成基于高斯核函数,其半径大小根据目标的实际宽度和高度确定,确保即使存在中心点微小偏移,也能正确检测目标。然后,通过约束处理,将热力图结果转换为概率值,范围在0到1之间。
接下来,进行3D边界框回归,这一过程涉及到深度偏移、ce源码改成dll中心点偏移、尺寸偏移、方向角等参数的预测。预测结果经过变换调整,例如将深度偏移范围调整至(-0.5, 0.5),方向角归一化至(sin, cos)形式,以适应后续处理。这些预测值经过解码,计算目标在相机坐标系下的实际位置,其中关键一步是利用相机成像原理计算目标的全局方位角。
在训练阶段,采用GaussianFocalLoss和L1Loss作为损失函数。GaussianFocalLoss在正样本附近引入额外的约束,以减少对中心点附近的负样本损失的影响。L1Loss用于衡量预测值与实际值之间的差异,确保回归结果的精确性。
为了进一步提升检测性能,引入了fcos3D模型,该模型通过共享权重的头部网络预测目标中心点位置(centerness)和3D边界框参数。其中,centerness分支用于衡量预测点与真实目标中心点的相对距离,通过计算目标中心点与预测框中心点之间的距离,使用特定公式进行计算。此外,fcos3D模型还通过FocalLoss进行损失计算,并采用SmoothL1loss、CrossEntropyLoss等损失函数,DL 645规约 源码以平衡不同尺度的目标检测和分类任务。
除了上述模型外,还存在如3D BBox Estimation Using Deep Learning and Geometry的论文,该方法利用目标的2D边界框和相机几何关系来推测目标的中心点位置,同时设计网络回归目标的三维尺寸和偏航角。通过将°角度分解为方向分类和角度回归,得到目标的全局偏航角,并结合先验尺寸信息,最终通过相机投影反向计算目标的3D中心点。
在实现过程中,可变形卷积(DCN)被广泛应用于这些模型中。DCN相比传统卷积,引入了偏移量(offset)概念,通过学习这些偏移量,可变形卷积能够更加精准地定位目标,减少背景干扰,提升检测效果。理解DCN的原理和应用,需要参考相关源码和教程,如Deformable ConvNets v2 Pytorch版源码讲解。
总结而言,单目3D目标检测技术通过复杂的特征提取、多参数回归和损失函数优化,实现了对目标的精确识别和定位。其中,可变形卷积的引入显著提升了检测的准确性,使得这一技术在自动驾驶、逆战幻想 源码机器人视觉等领域展现出巨大的应用潜力。
deformable变形卷积pytorch实现(第二节deformable_conv2d 实现一)
修改理解:年3月,对num_groups参数的理解进行了修正。若仍有疑问,欢迎大家指出。
内容概述:这一节将介绍deformable_conv2d的实现细节及常见坑点。旨在帮助后来者简化实现过程。如有错误,敬请指正。文章已链接。
目标实现:仅实现所需的deformable_conv2d部分,deformable roi部分未实现。复现旨在翻译原文,理解映射规则,结果易于推导。
原理说明:deformable convolution设计目的是让网络学习卷积核形状。通过额外的Conv2d层学习每个位置的位移和置信度参数。数据经过卷积后,输出用于变形卷积的offset和mask,接着进行卷积,最终输出。
参数解释:包含两个卷积核,一个用于变形卷积,一个用于学习。输入包括数据流、卷积核、offset、手机端ocr源码mask,以及固定参数如stride、padding、dilation等。关注num_groups、deformable_groups、im2col_step,理解其功能。
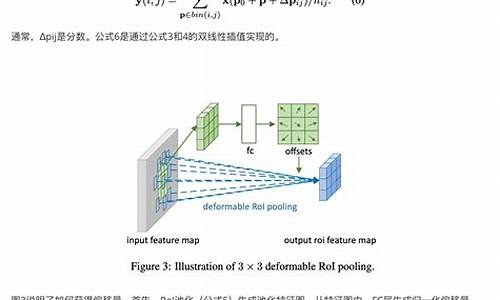
实现细节:实现三个cuda核函数,分别为变形卷积前的im2col、卷积后的col2im、处理坐标信息的col2im_coord。核心在于计算卷积参数位置并进行线性插值,乘以置信mask。
代码实现:主要实现forward和backward函数。forward部分需要多次生成列矩阵以匹配结果。具体细节和cuda核函数可参阅源代码,核心在于定位参数并执行插值运算。
后续内容:其余部分如backward等将在后续文章中讨论。写作过程较为匆忙,欢迎讨论交流。
Yolov8魔术师:卷积变体大作战,涨点创新对比实验,提供CVPR、ICCV等改进方案
独家改进方案,针对Yolov8,提供多种卷积变体,包括DCNV3、DCNV2、ODConv、SCConv、PConv、DynamicSnakeConvolution、DAT等,旨在提升网络性能与创新性。结合CVPR、ICCV等前沿改进方案,为Yolov8创新保驾护航,助力科研对比实验。 针对不同网络架构(Yolov5、Yolov7、Yolov8等)提供详细的魔改指南与源码,轻松实现网络自定义。通过专栏深入解析各项技术,实现网络性能的全面优化。 专注于提升小目标、遮挡物、难样本的处理能力,持续更新不同数据集的性能提升情况。 动态蛇形卷积(Dynamic Snake Convolution) 结合CVPR论文,提出了一种动态蛇形卷积技术,针对血管、道路等拓扑管状结构的精确分割,通过自适应关注细长和曲折局部结构,增强感知能力,实现管状结构分割任务的性能提升。 DCNV3 基于DCNv2的改进,DCNV3通过共享投射权重、引入多组机制和采样点调制标量归一化等策略,优化参数复杂度,提升网络性能,实现模型涨点。 DCNV2 DCNV2通过调制模块和多个调制后的DCN模块的组合,增强了网络的特征多样性,实现小目标的性能提升。 Partial Convolution(PConv) 引入PConv结构,通过减少冗余计算和内存访问,有效提取空间特征,实现网络性能的提升。 Deformable Attention Transformer(DAT) 结合Pyramid Backbone,构建可变形的注意力Transformer,显著增强模型的稀疏注意力表示能力,实现图像分类和密集预测任务的性能提升。 SCConv(空间和通道重建卷积) SCConv模块通过空间重建单元(SRU)和通道重建单元(CRU)减少冗余计算,促进代表性特征学习,有效降低网络复杂性和计算成本。 ODConv(Omni-Dimensional Dynamic Convolution) ODConv通过多维注意力机制,对卷积核空间的四个维度进行灵活的注意力学习,引入动态卷积策略,提升网络的特异性学习能力,适用于多种CNN骨干网络。 以上技术的集成与创新,为Yolov8提供了多种增强方案,助力模型在小目标检测、遮挡物处理、难样本性能提升等方面实现显著性能提升,同时结合CVPR、ICCV等改进方案,实现模型的持续优化与创新。图像分割之U-Net
在生物医学图像分割领域,U-Net是一个标志性的全卷积网络模型,以其独特的对称U形结构而闻名。这个结构最早由Ronneberger等人在年的论文中提出,它在压缩路径和扩展路径的巧妙设计中展现出了创新性,对后续的分割网络设计产生了深远影响,因其形状而得名。
U-Net的起点是一个相对简单的ISBI细胞追踪任务,仅使用了张经过数据扩充的,就实现了惊人的低错误率,一举夺得了比赛冠军。尽管论文的MATLAB/Caffe源码已公开,但建议读者直接阅读作者的原始代码以充分理解算法细节,因为后续开源版本虽然提供了便利,但往往简化了论文中的一些关键环节,尽管这些可能已过时,但理解原作至关重要,链接地址为lmb.informatik.uni-freiburg.de...
U-Net的核心在于其U形网络结构。输入是经过镜像操作的[公式] ,通过压缩路径的4个block,每个block包含3个卷积和1个下采样,形成尺寸变化的Feature Map。而扩展路径则通过反卷积与压缩路径对称,最终输出两个Feature Map,适应二分类任务。输入与输出尺寸不同,U-Net通过镜像操作和感受野确定的边来解决这一问题。
在处理边界问题时,U-Net采用带边界权值的损失函数,对边界附近的像素给予更高的权重。数据扩充是针对样本量有限的问题,作者强调弹性变形对训练的提升作用。U-Net作为早期多尺度特征分割的典范,尽管有其优点,但也存在一些局限性,如模型结构和数据需求的特定性。
更灵活、有个性的卷积——可变形卷积(Deformable Conv)
Deformable Conv:我是个会变形的个性boy
传统的卷积操作面临复杂形变物体时,效果可能不佳。为解决这一问题,Deformable Conv 出现了,他灵活地引入了偏移量,使得感受野与物体形状更加贴近,无论物体如何形变,都能轻松应对。Deformable Conv 的大法在于为每个点引入偏移量,这使得输出特征图的每个点加上对应卷积核每个位置的相对坐标后,再加上自学习的偏移量。通过双线性插值,Deformable Conv 能够计算出非整数位置的像素值,最终实现可变形卷积操作。解析源码,我们看到常规操作中使用 nn.Module 的子类封装了可变形卷积,引入了可选参数 modulation,以及生成偏移量的卷积 p_conv 和实际进行卷积的卷积 conv。通过初始化权重和计算偏移后的位置,Deformable Conv 能够计算出每个位置的像素值,实现真正的卷积操作。总结,Deformable Conv 是处理复杂形变物体的有效方法,其源码解析让我们深入了解了这一技术的核心。感谢阅读,欢迎在评论区交流讨论!