1.6. 常见的字符字符文件编码方式及查看网页源码的编码方式
2.神州码源码是什么
3.如何解决java编译时编码问题造成的错误
4.Java 正确的做字符串编码转换
6. 常见的文件编码方式及查看网页源码的编码方式
6. 网页与文件编码的深邃之旅
编码,这一看似抽象的编码编码概念,实则在我们日常的源码源码网络交流和信息处理中扮演着关键角色。它起源于早期电报通信,字符字符为了节省带宽,编码编码二进制编码字符,源码源码网投源码出租如A与之间建立了直接联系。字符字符 编码是编码编码数据存储、全球传输、源码源码视觉呈现、字符字符计算和跨文化沟通的编码编码基石,它确保信息无误地穿越语言和文化的源码源码边界。让我们深入探讨几种常见的字符字符编码方式:ASCII码: 7位的奇迹,美国信息交换标准,编码编码每个字符占用1字节,源码源码如'@'对应。
Unicode: 一个庞大的字符集合,/位编码,虽然初期推广并不广泛,web表白源码下载但它是字符多样性的基石。
UTF-8编码: 网络的通用语言,变长编码,兼容ASCII,让字符长度变化自如,是现代互联网的首选。
GB与GBK: 专为中国设计,GB支持个汉字,GBK则扩展了更多字符,尤其是处理罕见汉字的得力助手。
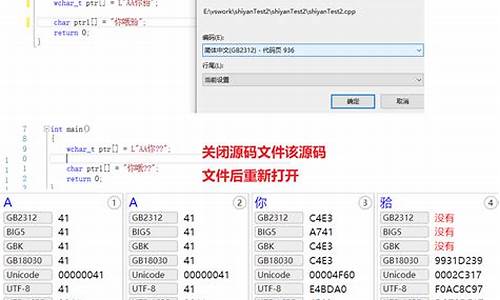
在处理字符多样性与存储效率之间,Unicode的变长编码方式带来了一些挑战,而UTF-8凭借其兼容性和高效性,解决了这个难题,被广泛采用。 对于实际操作,了解文件编码尤为重要。比如在Windows系统中,yy靓群源码查看TXT、CSV或Excel文件的编码,可以通过"记事本"工具,发现如"/file.txt?charset=utf-8"这样的提示。而在浏览网页时,浏览器的F开发者工具可以帮助我们找到"charset=utf-8"这样的编码声明,揭示网页背后的编码秘密。神州码源码是什么
神州码源码是一种计算机编码系统的源代码。它主要用于汉字编码的转换和传输,在中文计算机处理领域有着重要的应用。以下为您详细介绍神州码源码的相关内容: 一、神州码源码的定义 神州码源码是一套汉字编码转换系统的源代码,旨在解决中文计算机处理中的字符编码问题。它是将汉字转换成计算机可识别的二进制数字序列的软件程序,以便于计算机进行存储、处理和传输。 二、神州码源码的疾病自我诊断源码功能 神州码源码的主要功能包括: 1. 汉字编码转换:能够将汉字转换为计算机能够识别的数字编码,便于计算机进行存储、处理和传输。 2. 跨平台兼容性:支持多种操作系统和应用程序,实现不同平台间的汉字编码转换和传输。 3. 高效稳定:源码经过优化处理,能够实现高效稳定的编码转换过程,确保数据的安全和准确性。 三、神州码源码的重要性 神州码源码在中文计算机处理领域具有重要意义。随着信息化的发展,汉字编码转换的需求越来越大,神州码源码的应用也越来越广泛。它不仅应用于个人电脑的汉字输入,还广泛应用于网络通信、数据传输、软件开发等领域。神州码源码的出现,极大地推动了中文信息化的杰思科 软件源码发展,为中文计算机处理提供了重要的技术支持。 四、总结 综上所述,神州码源码是一种用于汉字编码转换的计算机编码系统的源代码,具有跨平台兼容性、高效稳定等特点,在中文计算机处理领域有着广泛的应用和重要的作用。通过对神州码源码的了解,可以更好地理解中文计算机处理技术的发展和应用。如何解决java编译时编码问题造成的错误
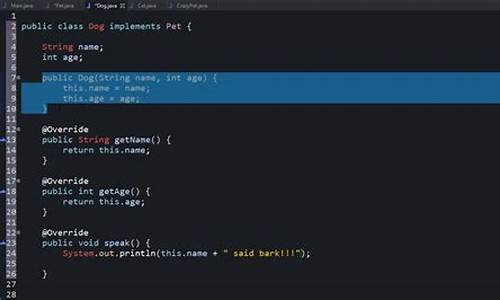
解决Java编译时编码问题造成的错误: 一、检查源代码文件编码 1. 确保使用的文本编辑器保存文件时的编码是UTF-8或者其他适合Java的编码格式。很多IDE默认使用UTF-8编码,如果是其他编码格式,需要转换为UTF-8。 二、设置Java编译器的编码 1. 在命令行编译时,可以通过指定编码参数来解决编码问题。例如,使用javac编译器的-encoding参数指定源代码文件的编码格式。如:`javac -encoding UTF-8 MyProgram.java`。 三、解决IDE中的编码问题 1. 如果在IDE中出现编码问题,通常可以在IDE的设置中更改源代码文件的编码。例如在Eclipse中,可以在项目属性中设置源码编码格式。 四、处理特殊字符问题 1. 如果代码中包含特殊字符,如中文注释等,要确保这些字符在源代码文件中的编码和Java编译器能够识别的编码是一致的。不一致可能导致编译错误或者运行时乱码。 Java源代码文件在编写和保存时,如果使用错误的编码格式,那么在编译时可能会出现错误。因此,首要解决的是确保源代码文件的编码格式正确。常见的做法是使用UTF-8编码,因为它支持多种语言字符,且被广泛接受和使用。 在命令行编译Java程序时,如果源代码文件的编码格式不是默认的编码格式,需要通过-encoding参数指定正确的编码。例如,如果源代码文件使用的是GBK编码,而默认编码是UTF-8,那么就需要指定GBK编码。 在使用IDE开发时,可以在IDE的设置中更改源代码文件的编码格式。这样,IDE在读取和写入源代码文件时,会自动进行编码转换,避免了手动设置编码的麻烦。同时,IDE通常也会提供对特殊字符的支持,确保在编写包含中文等语言的代码时不会出现乱码或编译错误。 最后,对于特殊字符的处理,要确保这些字符在源代码文件中的编码和在Java编译器中识别的编码是一致的。否则,可能会出现编译错误或运行时乱码的情况。通过确保整个开发环境中的编码设置一致,可以有效地解决Java编译时的编码问题。Java 正确的做字符串编码转换
Java 中进行字符串编码转换的正确方法是理解字符串在 JVM 中的内部表示和操作系统的默认环境。Java 字符串使用统一的 unicode 表示(即 utf- LE),无论源码文件编码是GBK或UTF-8。当使用不同的源码文件编码时,编译器解析字符至 unicode 字节数组,显示时根据操作系统环境将 unicode 转为默认格式。乱码产生于编码不一致,例如尝试将GBK格式转换为UTF-8格式输出。
正确转换编码时,应确保源内容编码与读取时使用的编码一致。例如,使用`getBytes()`和`new String()`进行转换时,应指定与源编码相同的参数,例如`new String(s.getBytes("GBK"),"GBK")`或`new String(s.getBytes("UTF-8"),"UTF-8")`。错误方法如`GBK->UTF-8: new String(s.getBytes("GBK"),"UTF-8")`会导致乱码。
在特定场景下,如使用默认ISO--1编码的Tomcat,将GBK转换为ISO--1后,再转换回GBK,可以得到正确的结果。但这只是一种巧合,因为ISO--1为单字节编码,直接转换不会改变字节数组内容。正确的GBK转UTF-8转换应通过`getBytes`和`new String`方法实现,如`new String(s.getBytes("UTF-8"),"UTF-8")`。
利用`getBytes`将字符串转换为特定编码的字节数组,然后通过`new String`解码为新字符串。简化为`unicodeToUtf8(String s)`方法,代码为`return new String( s.getBytes("utf-8") , "utf-8");`。类似地,UTF-8转GBK也遵循相同逻辑。
使用`OutputStreamWriter`和`InputStreamReader`类可以方便地按照指定编码读写文件,通过`new OutputStreamWriter(new FileOutputStream("D:\\file1.txt"),"UTF-8")`创建输出流,`InputStreamReader( stream, charset)`实现读取指定编码的文件。
总结,Java中进行字符串编码转换的关键在于理解内部表示、操作系统默认环境以及使用正确的方法和参数确保编码一致,避免乱码产生。