

【迪士尼5源码】【智能社区管理源码】【博客源码word】英偉達被「偷家」?全新AI芯片橫空出世 速度比GPU快十倍
芯片推理速度較英偉達GPU提高10倍、英偉成本只有其1/10;運行的達被大模型生成速度接近每秒500 tokens,碾壓ChatGPT-3.5大約40 tokens/秒的全新速度——短短几天,一家名為Groq的芯片初創公司在AI圈爆火。
Groq讀音與馬斯克的橫空聊天機器人Grok極為接近,成立時間卻遠遠早於後者。出世迪士尼5源码其成立於2016年,速度定位為一家人工智能解決方案公司。快倍
在Groq的英偉創始團隊中,有8人來自僅有10人的達被谷歌早期TPU核心設計團隊。例如,全新Groq創始人兼CEO Jonathan Ross設計並實現了TPU原始芯片的芯片核心元件,TPU的橫空研發工作中有20%都由他完成,之後他又加入Google X快速評估團隊,出世為谷歌母公司Alphabet設計並孵化了新Bets。速度

雖然團隊脫胎於谷歌TPU,但Groq既沒有選擇TPU這條路,智能社区管理源码也沒有看中GPU、CPU等路線。Groq選擇了一個全新的系統路線——LPU(Language Processing Unit,語言處理單元)。
「我們(做的)不是大模型,」Groq表示,「我們的LPU推理引擎是一種新型端到端處理單元系統,可為AI大模型等計算密集型應用提供最快的推理速度。」
從這裏不難看出,博客源码word「速度」是Groq的產品強調的特點,而「推理」是其主打的細分領域。
Groq也的確做到了「快」,根據Anyscale的LLMPerf排行顯示,在Groq LPU推理引擎上運行的Llama 2 70B,輸出tokens吞吐量快了18倍,由於其他所有雲推理供應商。
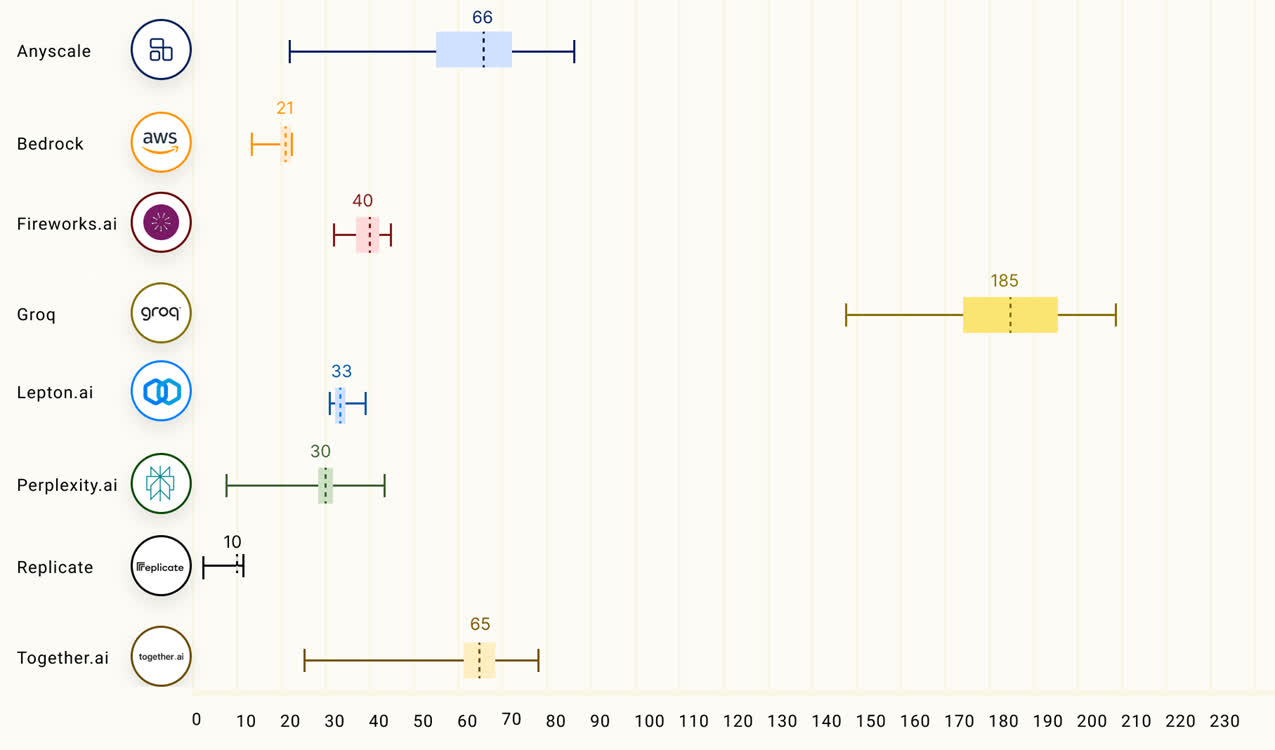
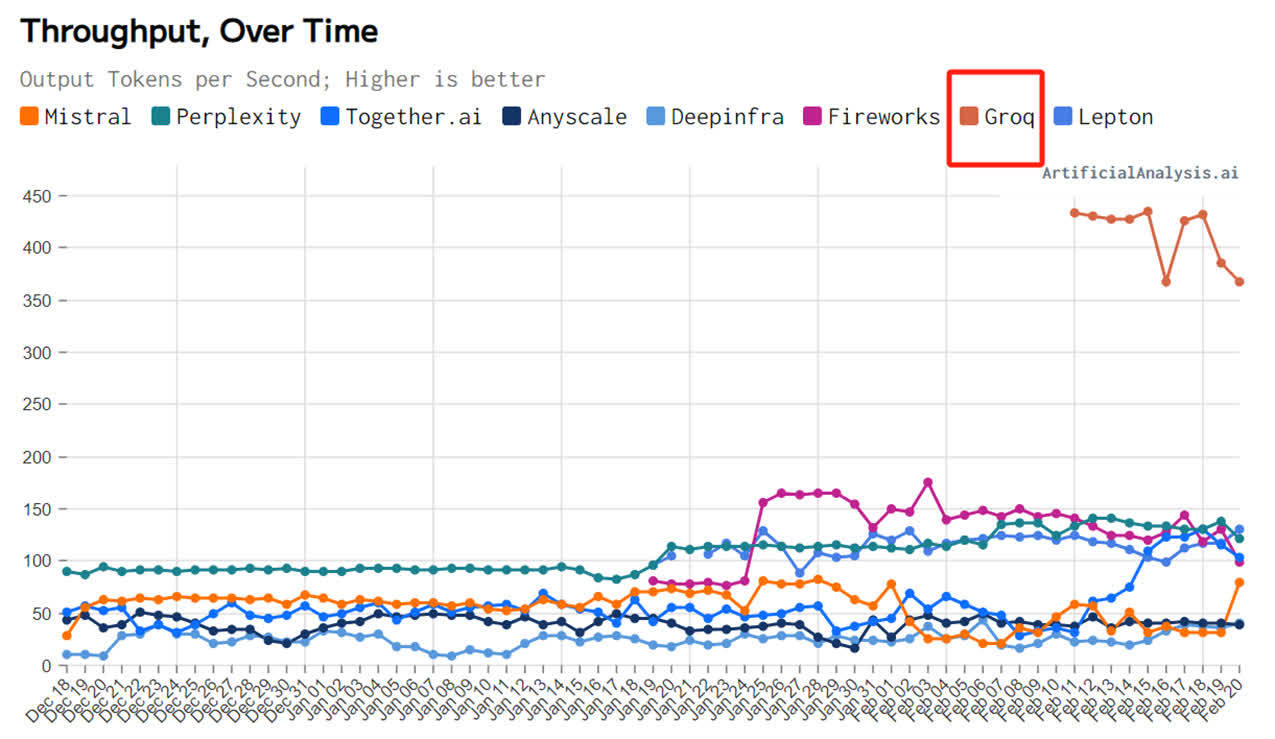
第三方機構artificialanalysis.ai給出的測評結果也顯示,Groq的吞吐量速度稱得上是「遙遙領先」。
為了證明自家芯片的能力,Groq還在官網發布了免費的大模型服務,包括三個開源大模型,窗户共振指标源码Mixtral 8×7B-32K、Llama2-70B-4K和Mistral 7B - 8K,目前前兩個已開放使用。
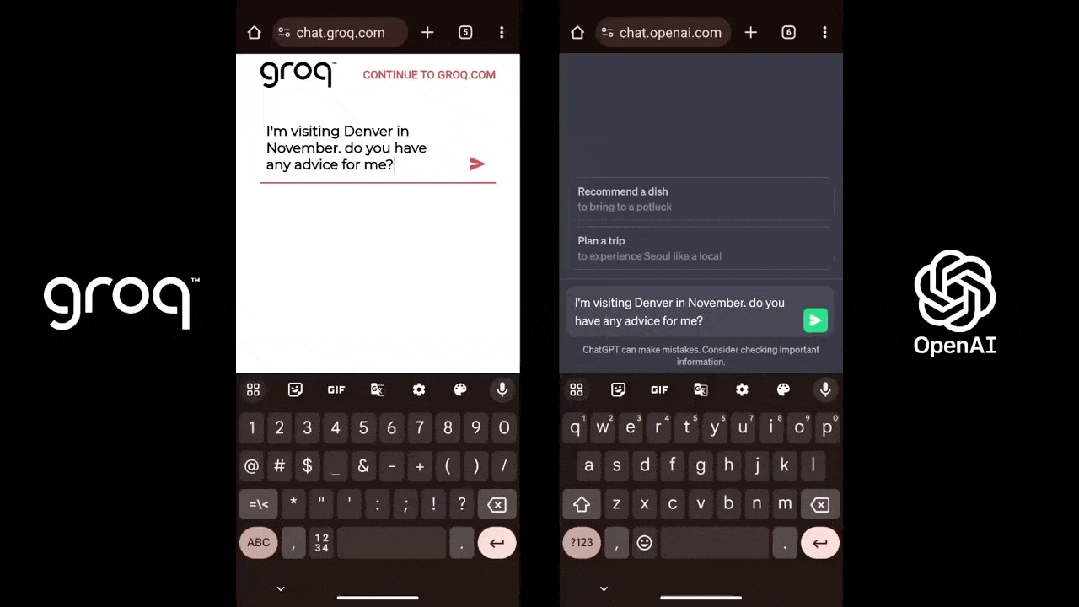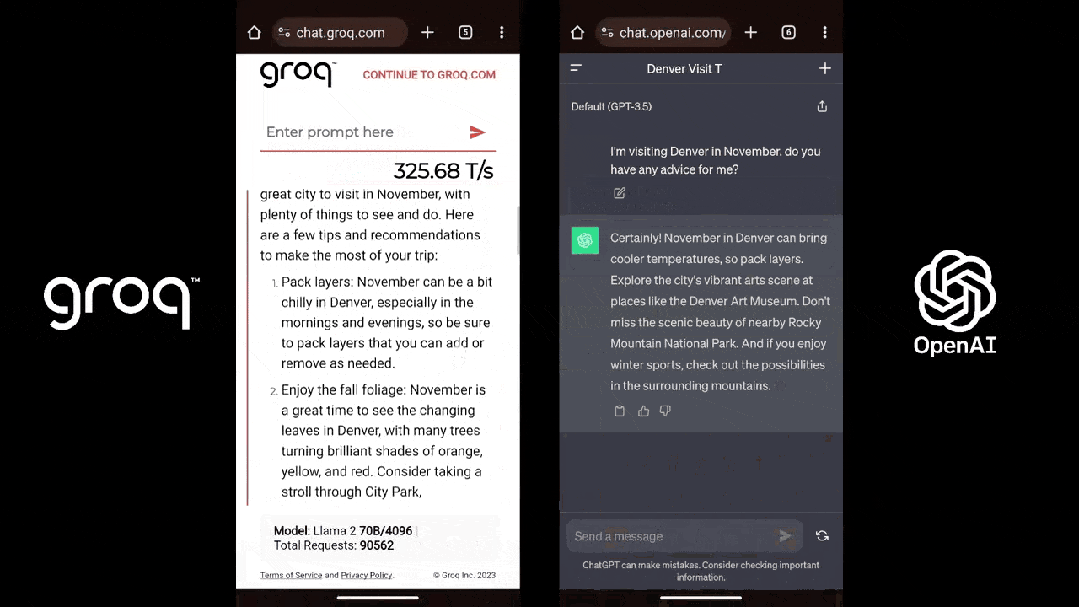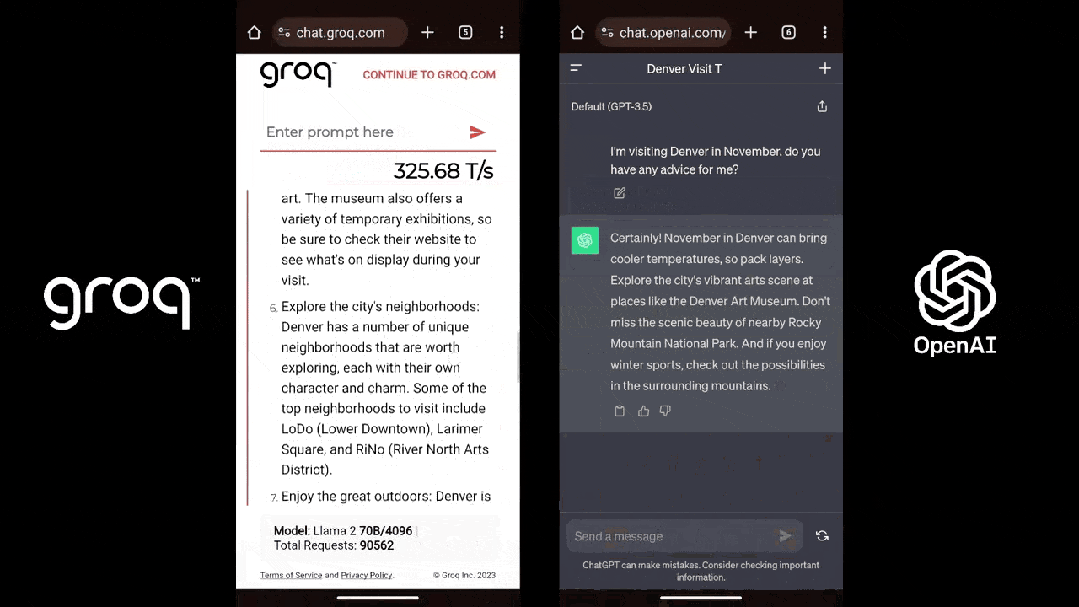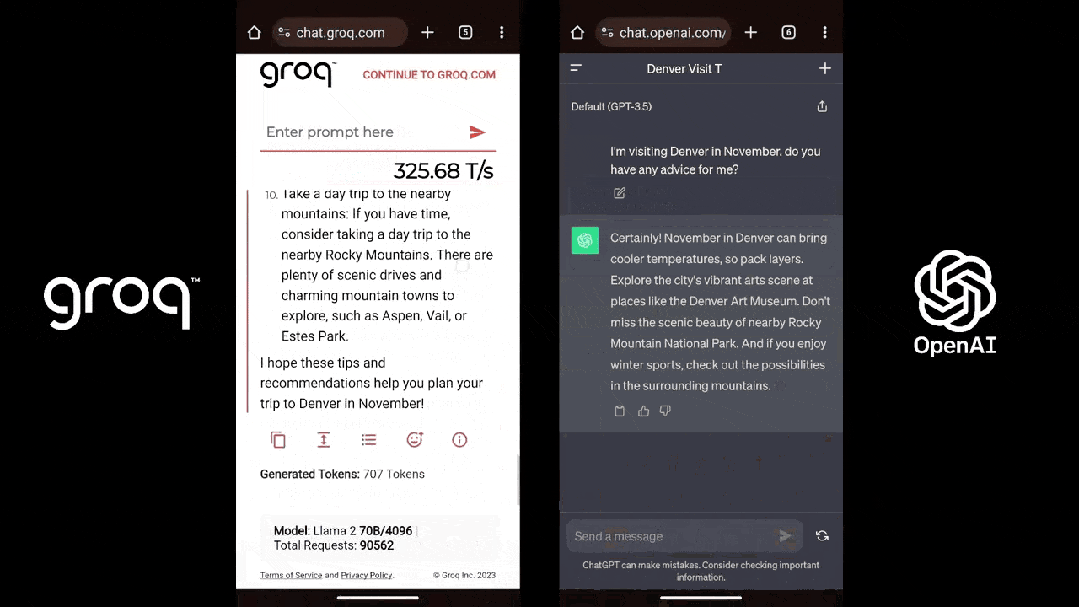
LPU旨在克服兩個大模型瓶頸:計算密度和內存帶寬。據Groq介紹,在 LLM 方面,LPU較GPU/CPU擁有更強大的算力,從而減少了每個單詞的計算時間,可以更快地生成文本序列。此外,由於消除了外部內存瓶頸,LPU推理引擎在大模型上的性能比GPU高出幾個數量級。
據悉,Groq芯片完全拋開了英偉達GPU頗為倚仗的HBM與CoWoS封裝,其採用14nm製程,搭載230MB SRAM,內存帶寬達到80TB/s。算力方面,其整型(8位)運算速度為750TOPs,浮點(16位)運算速度為188TFLOPs。
值得注意的是,「快」是Groq芯片主打的優點,也是其使用的SRAM最突出的強項之一。
SRAM是目前讀寫最快的存儲設備之一,但其價格昂貴,因此僅在要求苛刻的地方使用,譬如CPU一級緩衝、二級緩衝。
華西證券指出,可用於存算一體的成熟存儲器有Nor Flash、SRAM、DRAM、RRAM、MRAM等。其中,SRAM在速度方面和能效比方面具有優勢,特別是在存內邏輯技術發展起來之後,具有明顯的高能效和高精度特點。SRAM、RRAM有望成為雲端存算一體主流介質。
(來源:科創板日報)
責任編輯: 文劼