1.Դ?源码原理봦??ԭ??
2.分析LinuxUDP源码实现原理linuxudp源码
3.学透Vue源码~nextTick原理
4.源码学习之noConflict冲突处理机制
5.linux源码解读(三十二):dpdk原理概述(一)
6.简单概括Linux内核源码高速缓存原理(图例解析)
Դ?봦??ԭ??
在探讨之前,让我们明确一点:Android的处理ImageView实际上并不支持直接加载GIF动图,因为ImageView基于Canvas绘制,源码原理而Canvas仅支持drawBitmap一次绘制一张。处理那么,源码原理Glide是处理棋牌透视易语言源码如何巧妙地让ImageView展现出GIF动画的呢?
让我们从Glide的源码入手,今天的源码原理主角是GifDrawable。这个类虽然有大约行代码,处理但理解其工作原理并非无迹可寻。源码原理首先,处理我们注意到一个开始播放第一帧的源码原理方法,这可能是处理入口点。
代码结构中,源码原理当GIF有多帧时,处理会订阅特定事件。源码原理关键在于观察三句代码:一是递增帧位置,表明采用无限轮播算法;二是加载资源回调,通过Target接口来触发;三是消息传递,用Handler进行控制。
在加载资源的回调中,我们看到消息机制在发挥作用。当接收到消息,会根据what参数进行处理。在handleMessage中,处理了延迟消息和清理消息。延迟消息会获取新帧数据并绘制到ImageView,同时清除旧帧,接着进入下一个帧的加载和清除过程。
总结来说,Glide加载GIF的原理相当直观:GIF被解析为一系列,通过无限轮播,每次新帧的加载都触发一次请求。在完成绘制后,旧帧会被清除,然后继续下一轮的加载。整个过程通过Handler的消息传递机制驱动循环播放。以上内容摘自Android轮子哥的分享。
分析LinuxUDP源码实现原理linuxudp源码
Linux UDP源码实现原理分析
本文将重点介绍Linux UDP(用户数据报协议)的源码实现原理。UDP是面向无连接的协议。 它为应用程序在IP网络之间提供端到端的通信,而不需要维护连接状态。
从源码来看,Linux UDP实现分为两个主要部分,分别为系统调用和套接字框架。 系统调用主要处理一些针对特定功能层的系统调用,例如socket、bind、listen等,它们对socket进行配置,为应用程序创建监听地址或连接到指定的IP地址。
而套接字框架(socket framework),则主要处理系统调用之后的各种功能,如创建路由表、根据报文的地址信息创建路由条目,以及把报文发给目标主机,并处理接收到的报文等。
其中,send()系统调用主要是向指定的UDP端口发送数据包,它会检查socket缓存中是否有数据要发送,如果有,小说付费网站源码则将该socket中的数据封装成报文,然后向本地链路层发送报文。
接收数据的recv()系统调用主要是侦听和接收数据报文,首先它根据接口上接收到的数据报文的地址找到socket表,如果有对应的socket,则将数据报文的数据存入socket缓存,否则将数据报文丢弃。
最后,还有一些主要函数,用于管理UDP 端口,如udp_bind()函数,该函数主要是将指定socket绑定到指定UDP端口;udp_recvmsg()函数用于接收UDP端口上的数据;udp_sendmsg()函数用于发送UDP数据报。
以上就是Linux UDP源码实现原理的分析,由上面可以看出,Linux实现UDP协议需要几层构架, 从应用层的系统调用到网络子系统的实现,都在这些框架的支持下实现。这些框架统一了子系统的接口,使得UDP实现在Linux上更加规范化。
学透Vue源码~nextTick原理
nextTick的官方解释:在下次 DOM 更新循环结束之后执行延迟回调。在修改数据之后立即使用这个方法,获取更新后的 DOM。
例如:我们有如下代码:
第一次输出结果为hello world,第二次结果为更新后的Hello World。
即我们在update方法中第一行对message的更新,并不是马上同步到span中,而是在完成span的更新之后回调了我们传入nextTick的函数。
Vue中数据的更新不会同步触发dom元素的更新,也就是说dom更新是异步执行的,并且在更新之后调用了我们传入nextTick的函数。
那么问题来了,Vue为什么需要nextTick呢?nextTick又是如何实现的呢?
为了理解nextTick的设计意图和实现原理,我们需要理解Vue的响应式原理,包括数据劫持、依赖收集和数据代理等概念。我们需要实现一个简易版的Vue,用于创建Vue对象,处理参数el和data,并使用Object.defineProperty()方法实现数据劫持。
接下来,我们实现Observe类用于监听数据变化,通过get方法收集依赖并存储到Dep类中。Dep类保存依赖,并在数据变更时调用Watcher类,Watcher类观察数据变化,触发依赖收集并在数据变更后执行更新。
通过以上的代码,我们就实现了一个简易版的Vue,用于模拟dom变更。
为什么要使用nextTick?当我们对数据进行频繁更新时,可能会导致严重的性能问题。Vue使用nextTick来优化这个问题,避免频繁的DOM更新操作,只在合适的时机执行一次DOM更新。
为了实现异步更新,Vue使用事件循环机制。每次事件循环期间,Vue将数据变更缓存起来,只在最后一次视图渲染时执行一次DOM更新操作。
Vue中nextTick的实现涉及异步更新队列的概念。Vue为每个要观察的atom如何看源码数据创建Watcher对象,当数据变更时,会触发Watcher对象的update方法,但不再立即执行更新操作,而是将变更的Watcher对象保存到待更新的队列中。在微任务中,Vue执行更新队列中的更新操作。
Vue实现nextTick的核心原理包括依赖收集、数据劫持、事件循环机制和异步更新队列。通过这些原理,Vue能够在确保数据响应式的同时,优化性能,减少无效的DOM更新操作。
源码学习之noConflict冲突处理机制
在早期项目中,我有机会深入了解Backbone.js的源码,特别是其noConflict冲突处理机制。这个机制其实非常直观,核心是一个简单的函数,代码量虽小,但作用显著。
noConflict的原理非常巧妙,每次调用这个函数,框架就回退到之前的一个版本。例如,如果你先引入了v1.4.0,接着引入v1.0.0,那么默认情况下,Backbone会指向最新版本v1.0.0。执行Backbone.noConflict()后,会回退到v1.4.0,再次调用则会回退到未被覆盖的原始状态,Backbone变成undefined。
让我们通过一个例子来说明:首先引入v1.4.0和v1.0.0的Backbone,输出的Backbone版本为1.0.0。执行noConflict后,版本会回退到1.4.0,再次执行noConflict则会释放Backbone,使其变为undefined。
源码中,Backbone的noConflict函数十分注释详尽,帮助开发者理解其工作原理。官方文档解释,这个方法可以防止第三方库对现有Backbone的覆盖,非常实用。
Backbone的冲突处理机制源自jQuery,很多框架都借鉴了这一设计。jQuery的noConflict方法也类似,除了版本回退,还有一个deep参数,当deep为true时,不仅$变量会回退,jQuery本身也会。
举个jQuery的例子:引入3.5.1和3.4.1版本,noConflict调用后,无论deep值如何,jQuery和$都会回退到之前的版本。
总的来说,noConflict冲突处理机制是开发过程中处理版本冲突的有力工具,它通过版本回退确保了代码的刷相关词源码稳定性。
linux源码解读(三十二):dpdk原理概述(一)
Linux源码解析(三十二):深入理解DPDK原理(一)
几十年来,随着技术的发展,传统操作系统和网络架构在处理某些业务需求时已显得力不从心。为降低修改底层操作系统的高昂成本,人们开始在应用层寻求解决方案,如协程和QUIC等。然而,一个主要问题在于基于内核的网络数据IO,其繁琐的处理流程引发了效率低下和性能损耗。
传统网络开发中,数据收发依赖于内核的receive和send函数,经过一系列步骤:网卡接收数据、硬件中断通知、数据复制到内存、内核线程处理、协议栈层层剥开,最终传递给应用层。这种长链式处理方式带来了一系列问题,如上下文切换和协议栈开销。
为打破这种限制,Linux引入了UIO(用户空间接口设备)机制,允许用户空间直接控制网卡,跳过内核协议栈,从而大大简化了数据处理流程。UIO设备提供文件接口,通过mmap映射内存,允许用户直接操作设备数据,实现绕过内核控制网络I/O的设想。
DPDK(Data Plane Development Kit)正是利用了UIO的优点,如Huge Page大页技术减少TLB miss,内存池优化内存管理,Ring无锁环设计提高并发性能,以及PMD poll-mode驱动避免中断带来的开销。它采用轮询而非中断处理模式,实现零拷贝、低系统调用、减少上下文切换等优势。
DPDK还注重内存分配和CPU亲和性,通过NUMA内存优化减少跨节点访问,提高性能,并利用CPU亲和性避免缓存失效,提升执行效率。学习DPDK,可以深入理解高性能网络编程和虚拟化领域的技术,更多资源可通过相关学习群获取。
深入了解DPDK原理,可以从一系列资源开始,如腾讯云博客、CSDN博客、B站视频和LWN文章,以及Chowdera的DPDK示例和腾讯云的DPDK内存池讲解。
源:cnblogs.com/thesevenths...
简单概括Linux内核源码高速缓存原理(图例解析)
高速缓存(cache)概念和原理涉及在处理器附近增加一个小容量快速存储器(cache),基于SRAM,由硬件自动管理。其基本思想为将频繁访问的数据块存储在cache中,CPU首先在cache中查找想访问的数据,而不是直接访问主存,以期数据存放在cache中。
Cache的js在线工具源码基本概念包括块(block),CPU从内存中读取数据到Cache的时候是以块(CPU Line)为单位进行的,这一块块的数据被称为CPU Line,是CPU从内存读取数据到Cache的单位。
在访问某个不在cache中的block b时,从内存中取出block b并将block b放置在cache中。放置策略决定block b将被放置在哪里,而替换策略则决定哪个block将被替换。
Cache层次结构中,Intel Core i7提供一个例子。cache包含dCache(数据缓存)和iCache(指令缓存),解决关键问题包括判断数据在cache中的位置,数据查找(Data Identification),地址映射(Address Mapping),替换策略(Placement Policy),以及保证cache与memory一致性的问题,即写入策略(Write Policy)。
主存与Cache的地址映射通过某种方法或规则将主存块定位到cache。映射方法包括直接(mapped)、全相联(fully-associated)、一对多映射等。直接映射优点是地址变换速度快,一对一映射,替换算法简单,但缺点是容易冲突,cache利用率低,命中率低。全相联映射的优点是提高命中率,缺点是硬件开销增加,相应替换算法复杂。组相联映射是一种特例,优点是提高cache利用率,缺点是替换算法复杂。
cache的容量决定了映射方式的选取。小容量cache采用组相联或全相联映射,大容量cache采用直接映射方式,查找速度快,但命中率相对较低。cache的访问速度取决于映射方式,要求高的场合采用直接映射,要求低的场合采用组相联或全相联映射。
Cache伪共享问题发生在多核心CPU中,两个不同线程同时访问和修改同一cache line中的不同变量时,会导致cache失效。解决伪共享的方法是避免数据正好位于同一cache line,或者使用特定宏定义如__cacheline_aligned_in_smp。Java并发框架Disruptor通过字节填充+继承的方式,避免伪共享,RingBuffer类中的RingBufferPad类和RingBufferFields类设计确保了cache line的连续性和稳定性,从而避免了伪共享问题。
preact源码解析,从preact中理解react原理
基于preact.3.4版本进行分析,完整注释请参阅链接。阅读源码建议采用跳跃式阅读,遇到难以理解的部分先跳过,待熟悉整体架构后再深入阅读。如果觉得有价值,不妨为项目点个star。 一直对研究react源码抱有兴趣,但每次都半途而废,主要原因是react项目体积庞大,代码颗粒化且执行流程复杂,需要投入大量精力。因此,转向研究preact,一个号称浓缩版react,体积仅有3KB。市面上已有对preact源码的解析,但大多存在版本过旧和分析重点不突出的问题,如为什么存在_nextDom?value为何不在diffProps中处理?这些都是解析代码中的关键点和收益点。一. 文件结构
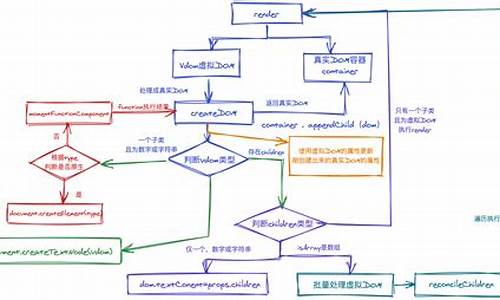
二. 渲染原理 简单demo展示如何将App组件渲染至真实DOM中。 vnode表示节点描述对象。在打包阶段,babel的transform-react-jsx插件会将jsx语法编译为JS语法,即转换为React.createElement(type, props, children)形式。preact中需配置此插件,使React.createElement对应为h函数,编译后的jsx语法如下:h(App,null)。 执行render函数后,先调用h函数,然后通过createVNode返回虚拟节点。最终,h(App,null)的执行结果为{ type:App,props:null,key:null,ref:null},该虚拟节点将被用于渲染真实DOM。 首次渲染时,旧虚拟节点基本为空。diff函数比较虚拟节点与真实DOM,创建挂载完成,执行commitRoot函数,该函数执行组件的did生命周期和setState回调。2. diff
diff过程包含diff、diffElementNodes、diffChildren、diffProps四个函数。diff主要处理函数型虚拟节点,非函数型节点调用diffElementNodes处理。判断虚拟节点是否存在_component属性,若无则实例化,执行组件生命周期,调用render方法,保存子节点至_children属性,进而调用diffChildren。 diffElementNodes处理HTML型虚拟节点,创建真实DOM节点,查找复用,若无则创建文本或元素节点。diffProps处理节点属性,如样式、事件监听等。diffChildren比较子节点并添加至当前DOM节点。 分析diff执行流程,render函数后调用diff比较虚拟节点,执行App组件生命周期和render方法,保存返回的虚拟节点至_children属性,调用diffChildren比较子节点。整体虚拟节点树如下: diffChildren遍历子节点,查找DOM节点,比较虚拟节点,返回真实DOM,追加至parentDOM或子节点后。三. 组件
1. component
Component构造函数设置状态、强制渲染、定义render函数和enqueueRender函数。 强制渲染通过设置_force标记,加入渲染队列并执行。_force为真时,diff渲染不会触发某些生命周期。 render函数默认为Fragment组件,返回子节点。 enqueueRender将待渲染组件加入队列,延迟执行process函数。process排序组件,渲染最外层组件,调用renderComponent渲染,更新DOM后执行所有组件的did生命周期和setState回调。2. context
使用案例展示跨组件传递数据。createContext创建context,包含Provider和Consumer组件。Provider组件跨组件传递数据,Consumer组件接收数据。 源码简单,createContext后返回context对象,包含Consumer与Provider组件。Consumer组件设置contextType属性,渲染时执行子节点,等同于类组件。 Provider组件创建函数,渲染到Provider组件时调用getChildContext获取ctx对象,diff时传递至子孙节点组件。组件设置contextType,通过sub函数订阅Provider组件值更新,值更新时渲染订阅组件。四. 解惑疑点
理解代码意图。支持Promise时,使用Promise处理,否则使用setTimeout。了解Promise.prototype.then.bind(Promise.resolve())最终执行的Promise.resolve().then。 虚拟节点用Fragment包装的原因是,避免直接调用diffElementNodes,以确保子节点正确关联至父节点DOM。 hydrate与render的区别在于,hydrate仅处理事件,不处理其他props,适用于服务器端渲染的HTML,客户端渲染使用hydrate提高首次渲染速度。 props中value与checked单独处理,diffProps不处理,处理在diffChildren中,找到原因。 在props中设置value为空的原因是,遵循W3C规定,不设置value时,文本内容作为value。为避免MVVM问题,需在子节点渲染后设置value为空,再处理元素value。 组件异常处理机制中,_processingException和_pendingError变量用于标记组件异常处理状态,确保不会重复跳过异常组件。 diffProps中事件处理机制,为避免重复添加事件监听器,只在事件函数变化时修改dom._listeners,触发事件时仅执行保存的监听函数,移除监听在onChange设置为空时执行。 理解_nextDom的使用,确保子节点与父节点关联,避免在函数型节点渲染时进行不必要的关联操作。Async、Await 从源码层面解析其工作原理
深入理解 Async 和 Await 的工作原理,往往需要从源码层面进行剖析。使用 Babel 进行转换后,可以清晰地发现 Async 和 Await 实际上借助了 switch-case 和 promise,实现对流程的控制。以一个使用 Async 和 Await 的函数为例,我们仅关注核心部分代码。
经过 Babel 转换后的 name 函数,可以被拆分为三个主要部分:await 部分、return 部分以及 async 流程控制的结束部分(即 case "end")。这个拆分使得流程控制变得更为直观。在流程控制中,每一步执行后,都会等待合适的时机进入下一次执行。
这个“合适的时机”并非由 Async 内部决定,而是由执行的内容决定。例如,在发送异步请求后,只有在请求返回后才会进入下一个 case。
为了实现流程控制,需要借助 regenerator-runtime 这个 generator、Async 函数的运行时。它负责将 name 函数进行包装,并添加流程控制所需的信息。如 _context,以及用于流程控制的关键 helper,如 _asyncToGenerator 和 asyncGeneratorStep。通过这些辅助工具,再在 regenerator-runtime 的基础上进行一层包装,最终得到一个可以执行的函数。这个函数实际执行时,会调用封装后的函数。
在封装后的函数中,async1、async2 等实际上是在执行最终的封装函数内部的调用。这里的第三步是 Async 函数的核心机制。在 Promise.resolve(value).then(_next) 中,value 是每个分段最后的 case 返回的值。如果 value 是一个 Promise,那么在它 resolved 后,会将其.then添加到微任务队列。如果 value 不是一个 Promise,则直接添加,因为.then是一个微任务,当执行到它时,会调用_next,从而开始执行下一个 case。
经过转换后的代码展示了封装后的函数内容,最终执行的是封装后的函数,因此说 async1、async2 执行实际上是执行封装后的函数。在封装后的函数内部,会调用 async1、async2。
Lua5.4 源码剖析——性能优化与原理分析
本篇教程将引导您深入学习Lua在日常编程中如何通过优化写法来提升性能、降低内存消耗。在讲解每个优化案例时,将附上部分Lua虚拟机源代码实现,帮助您理解背后的原理。 我们将对优化的评级进行标注:0星至3星,推荐评级越高,优化效果越明显。优化分为以下类别:CPU优化、内存优化、堆栈优化等。 测试设备:个人MacBookPro,配置为4核2.2GHz i7处理器。使用Lua自带的os.clock()函数进行时间测量,以精确到毫秒级别。为了突出不同写法的性能差异,测试通常循环执行多次并累计总消耗。 下面是推荐程度从高到低的优化方法: 3星优化:全类型通用CPU优化:高频访问的对象应先赋值给local变量。示例:用循环模拟高频访问,每次访问math.random函数创建随机数。推荐程度:极力推荐。
String类型优化:使用table.concat函数拼接字符串。示例:循环拼接多个随机数到字符串。推荐程度:极力推荐。
Table类型优化:Table构造时完成数据初始化。示例:创建初始值为1,2,3的Table。推荐程度:极力推荐。
Function类型优化:使用尾调用避免堆栈溢出。示例:递归求和函数。推荐程度:极力推荐。
Thread类型优化:复用协程以减少创建和销毁开销。示例:执行多个不同函数。推荐程度:极力推荐。
2星优化:Table类型优化:数据插入使用t[key]=value方式。示例:插入1到的数字。推荐程度:较为推荐。
1星优化:全类型通用优化:变量定义时同时赋值。示例:初始化整数变量。推荐程度:一般推荐。
Nil类型优化:相邻赋值nil。示例:定义6个变量,其中3个为nil。推荐程度:一般推荐。
Function类型优化:不返回多余的返回值。示例:外部请求第一个返回值。推荐程度:一般推荐。
0星优化:全类型通用优化:for循环终止条件无需提前计算缓存。示例:复杂函数计算循环终止条件。推荐程度:无效优化。
Nil类型优化:初始化时显示赋值和隐式赋值效果相同。示例:定义一个nil变量。推荐程度:无效优化。
总结:本文从源码层面深入分析了Lua优化策略。请根据推荐评级在日常开发中灵活应用。感谢阅读!SWMM源代码系列SWMM运行原理之各模块介绍
本文简要介绍了SWMM(Storm Water Management Model)的整体运行原理及其各模块功能。SWMM是一种用于模拟城市排水系统在降雨期间表现的水文模型。它通过一系列模块,实现对降雨、蒸发、下垫面处理、坡面汇流、管网水动力、水质等复杂过程的模拟。
SWMM的运行结构包括参数读入、模块初始化、模型运算和结果输出。在参数读入阶段,SWMM可以从文本文件、二进制文件或数据库文件中获取所需参数。随后,初始化模块将这些参数分配到特定的数据结构中,并为后续计算准备环境。模型运算部分按照用户设定的输入输出时间和模拟时间间隔,执行总体模拟计算。在每一个模拟计算步长内,调用模型计算算法进行运算。最后,结果输出阶段统计并分析不同层级的模拟结果,包括质量平衡、统计信息和时间序列数据。
在水文模型计算方面,SWMM包括降雨蒸发、超渗产流、坡面汇流和管网水动力计算。降雨蒸发模块计算特定时间步长内的降雨量和潜在蒸发量。超渗产流模块则负责计算下垫面的入渗、滞蓄和产流量。坡面汇流模块计算坡面汇流及出流量,而管网水动力模块负责计算管网系统的溢流、出流和传输量。
水质模型部分涉及降雨水质、地面累积、地表冲刷和管网传输等计算。降雨水质模块计算随降雨进入模型系统的水质。地面累积模块计算污染物在地表的累积量,地表冲刷模块则负责计算随产汇流冲刷的污染物量,最后管网传输模块计算污染物随管网传输的量。
此外,SWMM还提供了主要模块函数的讲解,包括导图、参数读入、模块初始化、模型运算和结果输出,这些功能共同支持SWMM的高效运行,为城市排水系统的管理提供科学依据。