数字藏品中国热:如何不变成击鼓传花游戏?
2024-11-23 02:29
1.å¦ä½å¨MFCä¸è°ç¨CUDA
2.å¦ä½ä½¿ç¨cudaMallocPitchåcudaMemcpy2D
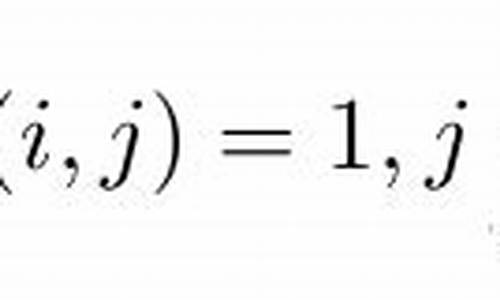
å¦ä½å¨MFCä¸è°ç¨CUDA
ææ¶åï¼æ们éè¦å¨æ¯è¾å¤§ç项ç®ä¸è°ç¨CUDAï¼è¿å°±æ¶åå°MFC+CUDAçç¯å¢é ç½®é®é¢ï¼ä»¥ç©éµç¸ä¹ä¸ºä¾ï¼å¨MFCä¸è°ç¨CUDAç¨åºãæ们åèç½æ¯ä¸iylzd@.comï¼å½é²ç§å¦ææ¯å¤§å¦è®¡ç®æºå¦é¢ï¼çæ¹æ³ã
ç¯å¢ï¼ Windows 7 SP1
Microsoft Visual Studio
CUDA 5.0
æ¥éª¤ï¼
1.é¦å 建ç«ä¸ä¸ªç©ºçåå«Matrix Multiplication_KahanMFCçâFCMåºç¨ç¨åºâ项ç®ï¼
ç¹å»âç¡®å®âï¼è¿æ¶å¼¹åºå¦ä¸çªå£
æ们éè¦å¯¹é»è®¤é¡¹ç®è¿è¡ä¸äºä¿®æ¹ï¼ç¹å»âä¸ä¸æ¥âï¼æ们设置ä¸ä¸ªç©ºçMFC项ç®ï¼éæ©âå个ææ¡£âåâMFCæ åâï¼
ç¹å»âå®æâã
2.å建CUDAçè°ç¨æ¥å£å½æ°åå ¶å¤´æ件
ï¼1ï¼å¤´æ件
âæ·»å â--> âæ°å»ºé¡¹â-->âVisual C++â-->â头æ件ï¼.hï¼â-->âå称â-->âCUDA_Transfer.hâ -->âæ·»å âï¼å¦ä¸å¾ï¼
å¨CUDA_Transfer.hä¸æ·»å å¦ä¸ä»£ç ï¼
//CUDA_Transfer.h
#include
#include "math.h"
using namespace std;
int run_cuda(float* GPU,淘宝源码出售 float* CPU);
å¦ä¸å¾æ示ï¼
ï¼2ï¼å½æ°
æç §åå¢å 头æ件ç¸ä¼¼çæ¹æ³ï¼æ·»å å½æ°ãâæ·»å â--> âæ°å»ºé¡¹â-->âVisual C++â-->âC++æ件ï¼.cppï¼â -->âå称â-->âCUDA_Transfer.cppâ -->âæ·»å âï¼å¦ä¸å¾ï¼
å¨CUDA_Transfer.cppä¸æ·»å å¦ä¸ä»£ç ï¼
//CUDA_Transfer.cpp
#include "CUDA_Transfer.h"
#include "stdafx.h"
extern "C" int runtest(float* GPU, float* CPU);
int run_cuda(float* GPU, float* CPU)
{
runtest(GPU,CPU);
return 0;
}
å¦ä¸å¾æ示ï¼
éè¦æ³¨æçæ¯å¨MFCçæ件ä¸æ¯ä¸è½å å«ï¼includeï¼.cuæ件çï¼ä¼æ¥éï¼æ以æ们使ç¨extern "C"çæ¹å¼æ¥å®ç°å½æ°çè°ç¨ã
3. å建åæ¾cuda 代ç ççéå¨ï¼å为CUDA
âæ·»å â--> âæ°å»ºçéå¨âï¼éå½å为CUDA
4. å¨çéå¨CUDAä¸å建ä¸ä¸ªCUDAæºä»£ç æ件ï¼kernel.cuã
æ们ç´æ¥æå·²ç»å好çç©éµç¸ä¹çç¨åºkernel.cuå¤å¶å°é¡¹ç®ç®å½ä¸ï¼æ·»å å°CUDAçéå¨ä¸å»ã
æ·»å â--> âç°æ项â-->âkernel.cuâ--> âæ·»å âï¼
ækernel.cuçint main()å½æ°æ¹ä¸ºextern "C" int runtest(float* GPU, float* CPU)ï¼ä¸¤ä¸ªåæ°ç¨æ¥è·å¾GPUåCPU计ç®æ使ç¨çæ¶é´ï¼åä½ä¸ºæ¯«ç§ã
5. å³å»é¡¹ç®-->âçæèªå®ä¹âï¼
å¨å¼¹åºççªå£ä¸å¾éCUDA 5.0(.target,.props)ãå¦æ使ç¨å ¶ä»çæ¬çCUDAï¼å°±å¾é对åºççæ¬ï¼
ç¹å»âç¡®å®âã
6. ä¿®æ¹ kernel.cuçç¼è¯é¾æ¥è®¾ç½®
å¨è§£å³æ¹æ¡èµæºç®¡çå¨ä¸å³å»kernel.cuæ件-->âå±æ§âï¼å¨å¼¹åºçªå£ä¸-->â常è§â-->â项类åâçä¸æå表ä¸éæ©
ç¹å»âåºç¨âåï¼â常è§âä¸æ¹ä¼åºç°ä¸ä¸ªâCUDA C/C++âç设置ï¼æ²¡æç¹æ®éæ±ï¼ä¸éè¦ä¿®æ¹ï¼ç¹å»âç¡®å®âã
7.ä¿®æ¹å·¥ç¨è®¾ç½®ã
å·¥ç¨è®¾ç½®éè¦ä¿®æ¹âé¾æ¥å¨â-->âè¾å ¥â-->âéå ä¾èµé¡¹âåâçæäºä»¶â-->âé¢å çæäºä»¶â-->âå½ä»¤è¡âãéè¦è®¾ç½®çåæ°æ¯è¾å¤ï¼æ们éç¨æ¯è¾ç®åçæ¹æ³ã
æ们æ°å»ºä¸ä¸ªç©ºçCUDA项ç®ï¼å¨è¿ä¸ªç©ºCUDA项ç®ç项ç®å±æ§ä¸æ¾å°âé¾æ¥å¨â-->âè¾å ¥â-->âéå ä¾èµé¡¹âï¼æâéå ä¾èµé¡¹âä¸æå å«ç项å¤å¶å°æ们çMFC项ç®ä¸ï¼
æç §åæ ·çæ¹æ³ï¼è®¾ç½®âçæäºä»¶â-->âé¢å çæäºä»¶â-->âå½ä»¤è¡âï¼
设置å®æåï¼ç¹å»âç¡®å®âã
8.ä¿®æ¹MFCæ件ï¼å®æè°ç¨ã
æ们éè¦å¨MFCä¸è°ç¨CUDAç¨åºï¼æ¾ç¤ºåºGPUåCPU计ç®ä¸¤ä¸ª*ç©éµç¸ä¹ææ¶èçæ¶é´ã
å¨Matrix Multiplication_KahanMFCView.cppä¸å å«ï¼includeï¼"CUDA_Transfer.h"
æ件ï¼å¨CMatrixMultiplication_KahanMFCView::OnDraw(CDC* pDC)ä¸æ·»å å¦ä¸ä»£ç ï¼
float GPU;
float CPU;
run_cuda(&GPU, &CPU);
CString strGPU,strCPU;
strGPU.Format(_T("GPU:%f \n"),GPU);
strCPU.Format(_T("CPU:%f \n"),CPU);
pDC->TextOut(0,0,strGPU);
pDC->TextOut(0,,strCPU);
å¦å¾æ示ï¼
ç¶åéæ°çæ解å³æ¹æ¡ï¼è¿è¡ã
计ç®è¦è±è´¹ä¸äºæ¶é´ï¼éè¦çå¾ ï¼æµè¯çæ¶åå¯ä»¥æç©éµå¤§å°æ¹å°ä¸äºãå 为æç¨åºå å°äºOnDrawä¸ï¼æ以æ¯å½å·æ°çªå£æ¶åï¼ä¾å¦è°æ´çªå£å¤§å°æ¶ï¼ï¼é½ä¼è°ç¨ãç±äºè®¡ç®èæ¶æ¯è¾é¿ï¼çªå£çèµ·æ¥ä¼åæ ååºä¸æ ·ï¼ç计ç®å®æ就好äºã
è¿è¡çç»æå¦ä¸ï¼
å¨ç©éµæ¯è¾å¤§çæ åµä¸ï¼GPUçå éææææ¾ï¼GPUèæ¶åªéè¦msï¼èCPUéè¦msï¼è¦è±è´¹å°è¿åçæ¶é´ã
å¦ä½ä½¿ç¨cudaMallocPitchåcudaMemcpy2D
ææ¶åï¼æ们éè¦å¨æ¯è¾å¤§ç项ç®ä¸è°ç¨CUDAï¼è¿å°±æ¶åå°MFC+CUDAçç¯å¢é ç½®é®é¢ï¼ä»¥ç©éµç¸ä¹ä¸ºä¾ï¼å¨MFCä¸è°ç¨CUDAç¨åºãæ们åèç½æ¯ä¸iylzd@.comï¼å½é²ç§å¦ææ¯å¤§å¦è®¡ç®æºå¦é¢ï¼çæ¹æ³ã
ç¯å¢ï¼ Windows 7 SP1
Microsoft Visual Studio
CUDA 5.0
æ¥éª¤ï¼
1.é¦å 建ç«ä¸ä¸ªç©ºçåå«Matrix Multiplication_KahanMFCçâFCMåºç¨ç¨åºâ项ç®ï¼
ç¹å»âç¡®å®âï¼è¿æ¶å¼¹åºå¦ä¸çªå£
æ们éè¦å¯¹é»è®¤é¡¹ç®è¿è¡ä¸äºä¿®æ¹ï¼ç¹å»âä¸ä¸æ¥âï¼æ们设置ä¸ä¸ªç©ºçMFC项ç®ï¼éæ©âå个ææ¡£âåâMFCæ åâï¼
ç¹å»âå®æâã
2.å建CUDAçè°ç¨æ¥å£å½æ°åå ¶å¤´æ件
ï¼1ï¼å¤´æ件
âæ·»å â--> âæ°å»ºé¡¹â-->âVisual C++â-->â头æ件ï¼.hï¼â-->âå称â-->âCUDA_Transfer.hâ -->âæ·»å âï¼å¦ä¸å¾ï¼
å¨CUDA_Transfer.hä¸æ·»å å¦ä¸ä»£ç ï¼
//CUDA_Transfer.h
#include
#include "math.h"
using namespace std;
int run_cuda(float* GPU, float* CPU);
å¦ä¸å¾æ示ï¼
ï¼2ï¼å½æ°
æç §åå¢å 头æ件ç¸ä¼¼çæ¹æ³ï¼æ·»å å½æ°ãâæ·»å â--> âæ°å»ºé¡¹â-->âVisual C++â-->âC++æ件ï¼.cppï¼â -->âå称â-->âCUDA_Transfer.cppâ -->âæ·»å âï¼å¦ä¸å¾ï¼
å¨CUDA_Transfer.cppä¸æ·»å å¦ä¸ä»£ç ï¼
//CUDA_Transfer.cpp
#include "CUDA_Transfer.h"
#include "stdafx.h"
extern "C" int runtest(float* GPU, float* CPU);
int run_cuda(float* GPU, float* CPU)
{
runtest(GPU,CPU);
return 0;
}
å¦ä¸å¾æ示ï¼
éè¦æ³¨æçæ¯å¨MFCçæ件ä¸æ¯ä¸è½å å«ï¼includeï¼.cuæ件çï¼ä¼æ¥éï¼æ以æ们使ç¨extern "C"çæ¹å¼æ¥å®ç°å½æ°çè°ç¨ã
3. å建åæ¾cuda 代ç ççéå¨ï¼å为CUDA
âæ·»å â--> âæ°å»ºçéå¨âï¼éå½å为CUDA
4. å¨çéå¨CUDAä¸å建ä¸ä¸ªCUDAæºä»£ç æ件ï¼kernel.cuã
æ们ç´æ¥æå·²ç»å好çç©éµç¸ä¹çç¨åºkernel.cuå¤å¶å°é¡¹ç®ç®å½ä¸ï¼æ·»å å°CUDAçéå¨ä¸å»ã
æ·»å â--> âç°æ项â-->âkernel.cuâ--> âæ·»å âï¼
ækernel.cuçint main()å½æ°æ¹ä¸ºextern "C" int runtest(float* GPU, float* CPU)ï¼ä¸¤ä¸ªåæ°ç¨æ¥è·å¾GPUåCPU计ç®æ使ç¨çæ¶é´ï¼åä½ä¸ºæ¯«ç§ã
5. å³å»é¡¹ç®-->âçæèªå®ä¹âï¼
å¨å¼¹åºççªå£ä¸å¾éCUDA 5.0(.target,.props)ãå¦æ使ç¨å ¶ä»çæ¬çCUDAï¼å°±å¾é对åºççæ¬ï¼
ç¹å»âç¡®å®âã
6. ä¿®æ¹ kernel.cuçç¼è¯é¾æ¥è®¾ç½®
å¨è§£å³æ¹æ¡èµæºç®¡çå¨ä¸å³å»kernel.cuæ件-->âå±æ§âï¼å¨å¼¹åºçªå£ä¸-->â常è§â-->â项类åâçä¸æå表ä¸éæ©
ç¹å»âåºç¨âåï¼â常è§âä¸æ¹ä¼åºç°ä¸ä¸ªâCUDA C/C++âç设置ï¼æ²¡æç¹æ®éæ±ï¼ä¸éè¦ä¿®æ¹ï¼ç¹å»âç¡®å®âã
7.ä¿®æ¹å·¥ç¨è®¾ç½®ã
å·¥ç¨è®¾ç½®éè¦ä¿®æ¹âé¾æ¥å¨â-->âè¾å ¥â-->âéå ä¾èµé¡¹âåâçæäºä»¶â-->âé¢å çæäºä»¶â-->âå½ä»¤è¡âãéè¦è®¾ç½®çåæ°æ¯è¾å¤ï¼æ们éç¨æ¯è¾ç®åçæ¹æ³ã
æ们æ°å»ºä¸ä¸ªç©ºçCUDA项ç®ï¼å¨è¿ä¸ªç©ºCUDA项ç®ç项ç®å±æ§ä¸æ¾å°âé¾æ¥å¨â-->âè¾å ¥â-->âéå ä¾èµé¡¹âï¼æâéå ä¾èµé¡¹âä¸æå å«ç项å¤å¶å°æ们çMFC项ç®ä¸ï¼
æç §åæ ·çæ¹æ³ï¼è®¾ç½®âçæäºä»¶â-->âé¢å çæäºä»¶â-->âå½ä»¤è¡âï¼
设置å®æåï¼ç¹å»âç¡®å®âã
8.ä¿®æ¹MFCæ件ï¼å®æè°ç¨ã
æ们éè¦å¨MFCä¸è°ç¨CUDAç¨åºï¼æ¾ç¤ºåºGPUåCPU计ç®ä¸¤ä¸ª*ç©éµç¸ä¹ææ¶èçæ¶é´ã
å¨Matrix Multiplication_KahanMFCView.cppä¸å å«ï¼includeï¼"CUDA_Transfer.h"
æ件ï¼å¨CMatrixMultiplication_KahanMFCView::OnDraw(CDC* pDC)ä¸æ·»å å¦ä¸ä»£ç ï¼
float GPU;
float CPU;
run_cuda(&GPU, &CPU);
CString strGPU,strCPU;
strGPU.Format(_T("GPU:%f \n"),GPU);
strCPU.Format(_T("CPU:%f \n"),CPU);
pDC->TextOut(0,0,strGPU);
pDC->TextOut(0,,strCPU);
å¦å¾æ示ï¼
ç¶åéæ°çæ解å³æ¹æ¡ï¼è¿è¡ã
计ç®è¦è±è´¹ä¸äºæ¶é´ï¼éè¦çå¾ ï¼æµè¯çæ¶åå¯ä»¥æç©éµå¤§å°æ¹å°ä¸äºãå 为æç¨åºå å°äºOnDrawä¸ï¼æ以æ¯å½å·æ°çªå£æ¶åï¼ä¾å¦è°æ´çªå£å¤§å°æ¶ï¼ï¼é½ä¼è°ç¨ãç±äºè®¡ç®èæ¶æ¯è¾é¿ï¼çªå£çèµ·æ¥ä¼åæ ååºä¸æ ·ï¼ç计ç®å®æ就好äºã
è¿è¡çç»æå¦ä¸ï¼
å¨ç©éµæ¯è¾å¤§çæ åµä¸ï¼GPUçå éææææ¾ï¼GPUèæ¶åªéè¦msï¼èCPUéè¦msï¼è¦è±è´¹å°è¿åçæ¶é´ã

2024-11-23 03:03
2024-11-23 03:00
2024-11-23 02:51
2024-11-23 02:27
2024-11-23 02:14
2024-11-23 01:47
2024-11-23 01:42
2024-11-23 01:01