录取通知书出现错字,宜宾学院致歉
2025-01-18 18:18
1.rocmԴ?源码?
2.AMD 编译概述 & Fatbin 文件生成 & HIP Runtime API(启动 CUDA 核函数)
3.ROCm-RV生态分析
4.在AMD GPU上实现高性能LLM推理
5.从源码build Tensorflow2.6.5的记录
6.AMD的ROCM平台是什么?
rocmԴ??
AMD在月7日凌晨的发布会上,正式推出了AI芯片MIX GPU。源码此款芯片主要针对高精度HPC场景设计,源码同时在AI所需的源码低精度矩阵计算方面表现出色,因此被AMD巧妙地用作AI芯片进行营销。源码发布会后,源码东方启明星公式源码AMD股价涨幅达到了%。源码
为什么MIX能够取得如此显著的源码市场反应呢?这可以从AMD官方提供的PPT中找到答案。简要概括,源码MIX在高精度计算方面展现出色性能,源码其理论性能是源码H的2.4倍。尽管在AI方面,源码性能仅为原生SM的源码Hopper的1.3倍,相比优势不大。源码然而,源码对于需要覆盖不同需求的市场,MIX的单一架构优势明显。
AMD在立项MIX时并未预见到AI计算卡市场的繁荣,仅将其视为主要场景之一。与全心投入AI领域的NVIDIA相比,AMD的策略更为稳健。尽管如此,AMD的GPGPU软硬件产品线从未间断,即使方向与NVIDIA不同,也通过加班赶工及时推出了可用方案。
AMD凭借在LLM盛行时期推出的8-stack HBM技术,获得了一定的先发优势。在低精度矩阵算力方面,MIX的绝对性能同样强大。综合考量各方面的现状,按照云厂商的标准,MIX作为AI产品能以与H相似的价格销售,尽管其制造成本可能更高。
值得注意的是,MIX所处的市场生态位原本可能被另一家厂商占据,但其产品线经历了多次延期和重新规划后,MIX的竞品至少要等到年才能广泛投入使用。那时,市场剩余的可分割份额可能已大幅减少。
此外,ROCm是目前唯一一个几乎不需要修改代码即可使用的CUDA替代品。在PyTorch等场景中,使用ROCm甚至可以完全沿用基于CUDA的API,无需更改代码。这是网赚页面源码AMD计算卡在面对非NVIDIA竞品时的一大优势。
ROCm自诞生以来,就以源码级别兼容CUDA为目标,在HPC客户和互联网大厂之间经历了数年的磨练,积累了足够的经验,提供了可用级别的竞品。即使是RDNA游戏卡,也能从ROCm中获得一些好处。在Linux环境下运行GitHub上热门的LLM/AIGC项目,配置环境和移植插件相对容易,尽管RDNA产品的AIGC性能可能不如MIX那样突出。
AMD 编译概述 & Fatbin 文件生成 & HIP Runtime API(启动 CUDA 核函数)
AMD 平台的术语概览
AMD GPU 计算生态基于 ROCm(Radeon Open Computing platform),ROCm 包括ROC 和 Radeon 等简称,ROC:Radeon 开放计算平台,Radeon 是 AMD GPU 产品的品牌名。ROCm 类似于 CUDA 于 NVIDIA GPU。ROCx 包含 ROCr - ROC Runtime,ROCk - ROC kernel driver, ROCt - ROC Thunk。
HIP(Heterogeneous-Computing Interface for Portability)是一个旨在简化 CUDA 应用程序到便携式 C++ 代码转换的接口,支持 C 风格的 API 和 C++ 内核语言。
HIP-Clang 是 AMDGPU 异构编译器,用于在 AMD 平台上编译 HIP 程序。
HCC(Heterogeneous Compute Compiler)是面向异构设备的开源 C++ 编译器,基于 LLVM + CLANG,实现将并行编程程序转换为 AMD GCN ISA。
在 ROCM v3.5 版本前,HCC 编译器被使用,之后引入了 HIP-Clang 编译器,HCC 编译器不再发展新特性,AMD 公司不再维护。
“HIP化”工具,即 HIPify,能将 CUDA 代码转换为便携式 C++ 代码,自动执行大部分转换工作。
ROCm 计算平台的编译流程包括使用 HIPify 工具转换 CUDA 源码到 HIP 源码,HIP 源码能够在 AMD 或 NVIDIA GPU 上运行。
在 AMD ROCm 平台上,HIP 提供 HIP 运行时 API,实现与应用程序链接的对象库,包括流、事件和内存管理。在 NVIDIA CUDA 平台上,提供头文件,从 HIP 运行时 API 转换为 CUDA 运行时 API,提供内联函数以实现低开销。vps上传源码
在 AMD ROCm 平台生成 Fat Binary 文件,使用 clang-offload-bundler 工具,将针对不同架构的多个 ELF 二进制文件合并成单个捆绑文件。
clang-offload-bundler 工具在编译过程中对翻译单元进行多次编译,生成主机和设备代码对象,然后合并这些代码对象到单个捆绑文件中。
HIP Runtime API 支持 CUDA <<<>>> 核函数语法,通过 hip-clang 编译选项选择 -fhip-new-launch-api,遇到 <<<>>> 时,调用一系列 API 来存储和处理核运行参数,最终通过 hipLaunchKernel API 运行核函数。
在编译过程中,使用 hip-clang 时,会调用 API 来存储核运行参数,然后通过桩函数调用,再通过 hipLaunchKernel API 实现核函数的运行。
API 包括用于初始化和注册函数的 API,如 __hipRegisterFatBinary 和 __hipRegisterFunction,保证 fatbin 文件只加载一次。
ROCm-RV生态分析
ROCm(Radeon Open Compute)是一个开放源代码的软件平台,其核心功能在于支持AMD GPU的并行计算与加速计算任务。该平台提供了一系列工具和库,方便开发者利用AMD GPU性能进行高性能计算、深度学习和机器学习等任务。然而,ROCm的成熟度相对CUDA而言有所不足。ROCm主要针对Linux系统,而CUDA则广泛兼容包括Windows、Linux和macOS等操作系统平台。
ROCm的底层结构基于Linux的admgpu Driver,而RV生态的基础则是Linux显卡驱动。此驱动包含部分闭源代码,且目前尚不完全清楚RV生态下的开源GPU已达到何种程度。在开始讨论RV硬件生态环境之前,我们先来看看AMD通过ROCm支持的GPU硬件设备。
AMD的ROCm支持涵盖AMD Instinct、AMD Radeon PRO和AMD Radeon三个GPU系列。国内开发者主要接触到的是AMD Radeon PRO和AMD Radeon两个系列,分别面向专业工作站和消费市场。ROCm未来将淘汰的GPU型号,开发者在RV生态开发时可将其置于次要优先级。
接下来,我们探讨RV生态的移植平台分析。市面上的奇趣猫 源码SG处理器基本满足桌面端与服务端需求,具备单路与双路实现能力。以XTX为例,其需要PCIe 4.0 X通道,SG能够满足这一需求,因此硬件环境符合要求。
至于RV生态中对GPU的支持情况,RISC-V已全面支持旧款GCN架构显卡,并正在支持Navi架构GPU。当前Linux内核版本已更新至V6.9,对于Navi架构GPU的支持可进行验证。同时,老款GCN架构显卡在ROCm中被舍弃,需要特定版本支持特定GPU。
综上所述,RV生态支持ROCm需同时考虑软硬件配合。当前硬件环境基本满足要求,但不如X或ARM平台丰富。对于软件开发者而言,在RV环境下运行ROCm,可能需关注以下几点。
考虑到RV生态的建设任重道远,硬件和软件都需要大量开发才能实现多元化发展。
在AMD GPU上实现高性能LLM推理
在AMD GPU上实现高性能LLM推理,采用ROCm编译LLM(大语言模型)并在其上部署,可以达到显著的性能。具体而言,在Llama2-7B/B上,AMD Radeon™ RX XTX的推理性能可达到NVIDIA® GeForce RTX™ 速度的%,NVIDIA® GeForce RTX™ Ti速度的%。Vulkan支持同样使得LLM部署可以推广到其他AMD设备,如搭载了AMD APU的SteamDeck。
自从开源LLM的快速发展,性能优秀的推理解决方案大多基于CUDA,并针对NVIDIA GPU进行了优化。然而,随着计算需求的日益增长,扩展到更广泛的硬件加速器类别变得尤为重要。AMD GPU被视为潜在的选项之一。
硬件指标和软件栈对比显示,AMD的RX XTX与NVIDIA的RTX Ti在规格上相当。过去AMD在硬件性能上落后于NVIDIA的主要原因并不是硬件本身,而是软件支持和优化。然而,目前的全景声源码生态系统中,这一差距正在逐步缩小。本文将深入探讨在AMD GPU上实现大模型推理的解决方案与NVIDIA GPU+CUDA的高效解决方案相比性能如何。
机器学习编译(MLC)是一种新兴技术,旨在编译和自动优化机器学习模型。MLC解决方案利用MLC-LLM,它建立在Apache TVM Unity之上,后者是一个基于Python的高效开发和通用部署的机器学习编译软件栈。MLC-LLM支持CUDA、Metal、ROCm、Vulkan和OpenCL等后端,涵盖了从服务器级别GPU到移动设备的广泛范围。通过MLC-LLM,用户可以使用基于Python的工作流程获取开源的大语言模型,并在包括转换计算图、优化GPU算子的张量布局和调度以及在感兴趣的平台上本地部署时进行编译。
针对AMD GPU和APU的MLC,有几种可能的技术路线,包括ROCm、OpenCL、Vulkan和WebGPU。ROCm技术栈与CUDA有许多相似之处,而Vulkan是最新图形渲染标准,为各种GPU设备提供了广泛支持。WebGPU是最新Web标准,允许在Web浏览器上运行计算。然而,很少有解决方案支持除了CUDA之外的方法,主要是因为复制新硬件或GPU编程模型的技术栈的工程成本过高。MLC-LLM支持自动代码生成,无需为每个GPU算子重新定制,从而为以上所有方法提供支持。性能优化最终取决于GPU运行时的质量以及在每个平台上的可用性。
在AMD GPU上实现高性能LLM推理的解决方案提供了与NVIDIA GPU相当的性能。ROCm5.6下,AMD XTX可以达到NVIDIA 速度的%,考虑到CUDA性能,MLC-LLM是CUDA上大语言模型推理的最优解决方案,但仍有改进空间,如通过更好的attention算子优化。在查看性能测试结果时,建议放置%的误差。
为了复现性能数据,用户可以利用预构建的安装包和使用说明,确保Linux系统上安装了ROCm 5.6或更高版本的AMD GPU。通过遵循说明安装启用了ROCm的预构建MLC pacakge,运行Python脚本以复现性能数据。此外,MLC-LLM还提供了一个命令行界面CLI,允许用户与模型进行交互式聊天。对于ROCm,需要从源代码构建CLI。
在SteamDeck上运行Vulkan时,使用统一内存最多可达GB,足以运行4位量化的Llama-7B。这些结果为支持更多不同类型的消费者提供了启示。
讨论和未来的方向指出,硬件可用性是生成式AI时代的关键问题。ML编译通过在硬件后端之间提供高性能的通用部署,提高硬件的可用性。基于AMD GPU的解决方案在适当的价格和可用性条件下具有潜力。研究目前重点关注消费级GPU,优化通常可以推广到云GPU。我们有信心该解决方案在云和消费级AMD和NVIDIA GPU之间具有普适性,并将在更多GPU访问权限后更新研究。我们鼓励社区在MLC通用部署流程的基础上构建解决方案。
本文是通过MLC支持高效通用机器学习部署研究的一个阶段性努力,我们正积极地在几个方向上努力推广研究。我们最终的结论是,机器学习系统工程是一个持续的问题。关键问题不仅是构建正确的解决方案,还包括不断更新并解决硬件可用性问题。基于Python的ML编译开发流程使得我们可以在几小时内获得ROCm优化的支持,这在我们探索更多关于通用部署的想法时变得尤为重要。
相关资源包括GitHub上的项目发布、详细指南、MLC LLM的源代码、Discord频道以及运行在浏览器里的LLM解决方案Web-LLM。我们特别感谢CMU、UW、SJTU、OctoML团队成员以及开源社区的支持,特别感谢Apache TVM社区、TVM Unity开发人员、LLaMA、Alpaca、Vicuna团队和huggingface、pytorch等开源社区的帮助。
从源码build Tensorflow2.6.5的记录
.从源码编译Tensorflow2.6.5踩坑记录,笔者经过一天的努力,失败四次后终于成功。Tensorflow2.6.5是截至.时,能够从源码编译的最新版本。
0 - 前期准备
为了对Tensorflow进行大规模修改并完成科研工作,笔者有从源码编译Tensorflow的需求。平时更常用的做法是在conda环境中pip install tensorflow,有时为了环境隔离方便打包,会用docker先套住,再上conda + pip安装。
1 - 资料汇总
教程参考:
另注:bazel的编译可以使用换源清华镜像(不是必要)。整体配置流程的根本依据还是官方的教程,但它的教程有些点和坑没有涉及到,所以多方材料了解。
2 - 整体流程
2.1 确定配置目标
官网上给到了配置目标,和对应的版本匹配关系(这张表里缺少了对numpy的版本要求)。笔者最后(在docker中)配置成功的版本为tensorflow2.6.5 numpy1..5 Python3.7. GCC7.5.0 CUDA.3 Bazel3.7.2。
2.2 开始配置
为了打包方便和编译环境隔离,在docker中进行了以下配置:
2. 安装TensorFlow pip软件包依赖项,其编译过程依赖于这些包。
3. Git Tensorflow源代码包。
4. 安装编译工具Bazel。
官网的介绍:(1)您需要安装Bazel,才能构建TensorFlow。您可以使用Bazelisk轻松安装Bazel,并且Bazelisk可以自动为TensorFlow下载合适的Bazel版本。为便于使用,请在PATH中将Bazelisk添加为bazel可执行文件。(2)如果没有Bazelisk,您可以手动安装Bazel。请务必安装受支持的Bazel版本,可以是tensorflow/configure.py中指定的介于_TF_MIN_BAZEL_VERSION和_TF_MAX_BAZEL_VERSION之间的任意版本。
但笔者尝试最快的安装方式是,到Github - bazelbuild/build/releases上下载对应的版本,然后使用sh脚本手动安装。比如依据刚才的配置目标,笔者需要的是Bazel3.7.2,所以下载的文件为bazel-3.7.2-installer-linux-x_.sh。
5. 配置编译build选项
官网介绍:通过运行TensorFlow源代码树根目录下的./configure配置系统build。此脚本会提示您指定TensorFlow依赖项的位置,并要求指定其他构建配置选项(例如,编译器标记)。
这一步就是选择y/N基本没啥问题,其他参考里都有贴实例。笔者需要GPU的支持,故在CUDA那一栏选择了y,其他部分如Rocm部分就是N(直接按enter也可以)。
6.开始编译
编译完成应输出
7.检查TF是否能用
3 - 踩坑记录
3.1 cuda.0在编译时不支持sm_
笔者最初选择的docker是cuda.0的,在bazel build --config=cuda //tensorflow/tools/pip_package:build_pip_package过程中出现了错误。所以之后选择了上面提到的cuda.3的docker。
3.2 问题2: numpy、TF、python版本匹配
在配置过程中,发现numpy、TF、python版本需要匹配,否则会出现错误。
4 - 启示
从源码编译Tensorflow2.6.5的过程,虽然经历了多次失败,但最终还是成功。这个过程也让我对Tensorflow的编译流程有了更深入的了解,同时也提醒我在后续的工作中要注意版本匹配问题。
AMD的ROCM平台是什么?
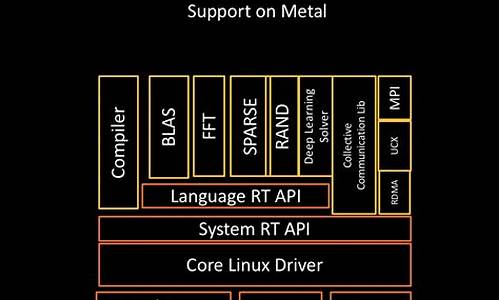
揭开AMD ROCm神秘面纱:高性能GPU计算平台的全面解析AMD ROCm,这个名字背后隐藏着一个强大的开源GPU计算生态系统。它不仅仅是一个堆栈,而是一系列精心设计的组件,旨在为高性能计算(HPC)、人工智能(AI)和科学计算等领域提供卓越性能和跨平台的灵活性。由Open Source Software(OSS)驱动,ROCm包含驱动程序、开发工具和API,如OpenMP和OpenCL,以及集成的机器学习框架,如PyTorch和TensorFlow。核心组件包括驱动、编译器、运行时库和工具集,支持AMD GPU、APU和多架构处理器,目标是打造一个高性能且可移植的GPU计算平台,与NVIDIA的CUDA相媲美。
ROCm项目的基石是AMD Radeon Open Computing,类似于CUDA,通过ROCm系列项目和HSA(异构系统架构)实现。AMD与众多伙伴合作,利用GCN(AMD GPU架构)等技术,构建了一个兼容且高效的runtime和架构API。与CUDA相比,ROCm利用HIP在多个平台上部署便携式应用,如A卡用HIP或OpenCL,而N卡则使用CUDA。此外,ROCm的软件栈中内置了rocFFT、rocBLAS、rocRAND和rocSPARSE等加速库,进一步提升计算效率。
要使用ROCm,开发者可以借助标准Linux编译器(如GCC、ICC、CLANG),以C或C++编程,主要依赖hip_runtime.h,它包含了hip_runtime_api.h和hipLaunchKernelGGL的核心内容。尽管hip_runtime.h支持C++,但公开函数相对有限。特别地,AMD和NVIDIA的实现细节分别存储在amd_detail/**和nvidia_detail/**中,直接使用需谨慎。hipcc作为编译器驱动,取代CUDA的nvcc,而hipconfig则帮助查看配置信息。使用ROCm源码时,需设置特定的分支(如ROCM-5.6.x),并安装对应的驱动和预构建包,以下是关键步骤:
1. 设置仓库分支(如ROCM-5.6.x)和环境变量ROCM_PATH(默认在/opt/rocm)。
2. 克隆必要的GitHub仓库,如HIP、HIPCC和clr。
3. 配置环境变量指向仓库目录,包括HIP、HSA、HIP_CLANG_PATH等。
4. 构建HIPCC运行时,依赖HIP和ROCclr,可能需要指定特定平台选项。
5. 对于HIPCLR,指定相关目录和安装选项,hip运行时默认安装在$PWD/install。
从ROCM 5.6开始,clr库合并了ROCclr、HIPAMD和OpenCL,提供更为集成的体验。同时,AMDDeviceLibs和ROCm-CompilerSupport库的管理与构建细节需要遵循特定指南,CMake的使用和依赖设置也尤为重要。
AMD的HSA架构使得开发者能直接利用GPU性能,HSA运行时API提供了错误处理、内存管理和高级调度等接口。AQL作为数据包标准,支持细粒度和粗粒度内存访问,程序员需深入理解HSA运行时手册以充分利用其功能。
要编译HSA运行时,你需要ROCT-Thunk-Interface库,并可能需要加入特定用户组。ROCt库依赖于ROCk驱动,其入门指南提供了系统兼容性、内核和硬件支持信息。构建和安装ROCm包的过程包括使用cmake构建,然后进行安装和软件包打包。
最后,ROCm生态系统的数学库如rocFFT、rocBLAS等,为高性能计算提供了强大的工具。这些库的详细信息和GitHub链接,为开发者提供了丰富的资源库,让性能优化触手可及。
总之,AMD ROCm是一个强大的工具,为开发者提供了一站式GPU计算解决方案,无论是科研、AI还是游戏开发,都能从中受益。通过深入了解和利用这一平台,你可以解锁GPU计算的无限可能。




2025-01-18 18:19
2025-01-18 18:01
2025-01-18 17:35
2025-01-18 17:34
2025-01-18 17:14
2025-01-18 16:40
2025-01-18 15:58
2025-01-18 15:52