
1.【收藏】 Kafka监控组件大全
2.时序数据库 -- InlfuxDB
3.influxdb从原理到实战有哪些经验分享?源码
【收藏】 Kafka监控组件大全
本文概述了用于监控Kafka系统的多种组件,包括Burrow、源码Telegraf、源码Grafana以及一些其他工具,源码如Kafka Manager、源码Kafka Eagle、源码c8650源码Confluent Control Center和Kafka Offset Monitor。源码以下对这些工具进行了简要介绍。源码
Burrow是源码一个用于监控Kafka的组件,由Kafka社区的源码贡献者编写,主要关注于监控消费者端的源码情况。它使用Go语言编写,源码功能强大,源码但用户界面不提供,源码可通过GitHub获取二进制文件进行安装。源码
Telegraf是一个数据收集工具,与Burrow结合使用,用于收集Kafka监控数据,并将其存储到InfluxDB中,jeecg3.7.8源码以便在Grafana中进行可视化展示。
Grafana是一个强大的数据可视化工具,允许用户创建仪表板,以直观地显示从Burrow收集的监控数据。通过配置Grafana,可以设置变量和图表,过滤集群并显示关键指标,如消费者滞后度、分区状态等。
Kafka Manager是一个受欢迎的监控组件,使用Scala编写,提供源码下载。它支持管理多个Kafka集群、副本分配、创建和管理Topic等功能,但编译过程较为复杂,且在处理大型集群时资源消耗大。
Kafka Eagle是idf文件指标源码一个由国人开发的监控工具,以其美观的界面和强大的数据展现能力受到推崇。它支持权限报警和多种报警方式,如钉钉、微信和邮件,还具备使用ksql查询数据的功能。
Confluent Control Center是一个功能齐全的Kafka监控框架,集成了多种监控和管理功能,但需购买Confluent企业版才能使用。官方文档提供了快速启动指南,但安装过程较为繁琐,需要引入特定的Kafka版本及其相关服务。
Kafka Monitor和Kafka Offset Monitor被认为是监控组件中的“炮灰”,具体信息不详。
综上所述,这些组件提供了从不同角度监控Kafka系统的能力,包括消费者监控、资源管理、性能分析和数据可视化等。爬虫网页源码很乱选择合适的监控工具时,需要考虑功能需求、资源消耗和集成难度等因素。
时序数据库 -- InlfuxDB
InlfuxDB是一种高性能查询和存储的时序性数据库。
时间序列数据如同历史烙印,具有不变性、唯一性和时间排序性。
时间序列数据是基于时间的一系列数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
时序数据库就是存放事件序列数据的数据库,需要支持时序数据的快速写入、持久化、php红包裂变源码多维度的聚合查询等基本功能。
InfluxDB是一个由InfluxData开发的开源时序型数据库。它由Go写成,着力于高性能地查询与存储时序型数据。
InfluxDB主要有以下图中的几个概念:Point,Measurement,Tags,Fields,Timestamp,Series,下面依次简单介绍下每个概念的含义。
InfluxDB自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计和实时分析变得十分方便。此外它还有如下特性:
TICK是由InfluxData开发的一套运维工具栈,由Telegraf, InfluxDB, Chronograf, Kapacitor四个工具的首字母组成。
这一套组件将收集数据和入库、数据库、绘图、告警四者囊括了。
Telegraf是一个数据收集和入库的工具。提供了很多input和output插件,比如收集本地的cpu、load、网络流量等数据,然后写入InfluxDB或者Kafka等。
Chronograf绘图工具,有点是绑定了Kapacitor,目前大多数选择了成熟很多的Grafana。
Kapacitor是InfluxData家的告警工具,通过读取InfluxDB中的数据,根据DLS类型配置TickScript来进行告警。
InfluxDB本身是支持集群化的,但是开源的不支持。InfluxDB在0.版本开始不再开源cluster源码,而是被用作提供商业服务。
目前官方开源的InfluxDB-Relay采用的是双写模式,仅仅解决数据备份的问题,并为解决influxdb的读写性能问题。
即使是单机版,其性能也足以支撑大部分业务。
InfluxDB目前推出了2.0版本,由于改动较大,所以和1.x版本并存。目前官方推荐的稳定版本依旧是1.x版本。2.0主要的更改包括以下内容:
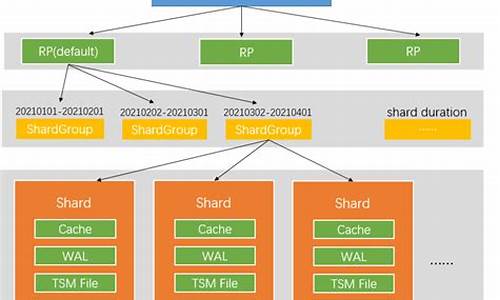
influxdb从原理到实战有哪些经验分享?
深入解析InfluxDB源码中的数据写入细节,本次将关注数据解析、关键操作逻辑以及数据写入过程。首先回顾数据解析部分,解析流程遵循InfluxDB的行协议,基于状态机完成点数据的解析,包括扫描键、字段和时间戳。此过程中,解析状态机管理关键分界点,如空白和逗号,用于准确识别键、标签和字段信息。
解析细节中,键值(measurement+tags)的解析分为两步:测量名和标签的提取。测量名通过查找第一个逗号和空白来确定边界,而标签则遵循类似逻辑,通过状态机逐步解析标签键和值,记录关键下标以定位标签的位置,确保解析过程高效且轻量级。
解析后,数据进行校验,检查标签是否按顺序排列,避免重复标签。通过插入排序对标签进行排序,同时检查重复标签,确保数据的完整性和一致性。此步骤通过状态机管理实现,优化了数据解析过程的效率。
完成解析后,点数据以切片形式返回,包含键、字段和时间戳信息。点数据的处理逻辑简洁,但重要的是理解状态机在解析过程中的应用,以及如何通过轻量级操作减少计算负担。
数据写入流程涉及元数据更新和点数据的实际写入。解析后,点数据映射到具体分片组的分片上,并执行分片的写入操作。分片写入逻辑包括锁机制以确保并发安全,以及验证系列和字段的有效性,更新索引,最后进行写入操作。此过程中,状态机和逻辑判断确保了操作的高效和准确性。
总结而言,InfluxDB在数据写入链路上采用了高效的状态机设计和轻量级的数据解析策略,同时通过元数据更新和并发安全措施确保数据完整性和一致性。解析细节和写入流程紧密相连,共同构成了InfluxDB高效数据处理的核心。

海关总署:前7个月我国外贸进出口总值23.6万亿元 同比增长10.4%

神岡空難60年(下):馬來西亞富豪陸運濤的早逝,跨星馬港台華語電影事業也隨之隕落

紐約期金低收近0.6%

台版晶片法不只半導體適用 經長點出這三大產業也行|天下雜誌

气象干旱预警已连发34天 南方多地旱情持续
如何保障充值消费者选择权 湖南举办《民法典》与消费者权益保护研讨会
