
1.python基础教程(代码编程教学入门)
2.CentOS 6.2编译安装Nginx1.0.14+MySQL5.5.22+PHP5.3.10步骤分享
3.谈谈网站安全性的源码问题
4.一个Linux多进程编程?
python基础教程(代码编程教学入门)
python入门教程?
给大家整理的这套python学习路线图,按照此教程一步步的源码学习来,肯定会对python有更深刻的源码认识。或许可以喜欢上python这个易学,源码精简,源码开源的源码ishow源码语言。此套教程,源码不但有视频教程,源码还有源码分享,源码让大家能真正打开python的源码大门,进入这个领域。源码现在互联网巨头,源码都已经转投到人工智能领域,源码而人工智能最好的源码编程语言就是python,未来前景显而易见。源码黑马程序员是国内最早开设人工智能的机构。
一、首先先推荐一个教程
8天深入理解python教程:
主要讲解,python开发环境的构建,基础的数据类型,字符串如何处理等简单的入门级教程。
二、第二个教程,是系统的基础知识,学习周期大概一个月左右的时间,根据自己的学习能力吸收能力来定。初学者只要跟着此套教程学习,入门完全没有问题。
学完后可掌握的核心能力
1、掌握基本的Linux系统操作;
2、掌握Python基础编程语法;
3、建立起编程思维和面向对象思想;
可解决的现实问题:
字符串排序,切割,逆置;猜数字、飞机大战游戏;
市场价值:
具备编程思维,掌握Python基本语法,能开发出一些小游戏
所涉及知识点:
教程地址:
三、拓展教程
1、网络爬虫-利用python实现爬取网页神技
第一天:
第二天:
2、Python之web开发利刃
第一天:
第二天:
3、python之大数据开发奇兵
python基础教程
运算
a=
b=
c=0
c=a+b
print"1-c的值为:",c
c=a-b
print"2-c的值为:",c
c=a*b
print"3-c的值为:",c
c=a/b
print"4-c的值为:",c
c=a%b
print"5-c的值为:",c
a=2
b=3
c=a**b
print"6-c的值为:",c
a=
b=5
c=a//b
print"7-c的值为:",c
python比较
a=
b=
c=0
if(a==b):
print"1-a等于b"
else:
print"1-a不等于b"
if(a!=b):
print"2-a不等于b"
else:
print"2-a等于b"
if(ab):
print"3-a不等于b"
else:
print"3-a等于b"
if(ab):
print"4-a小于b"
else:
print"4-a大于等于b"
if(ab):
print"5-a大于b"
else:
print"5-a小于等于b"
a=5
b=
if(a=b):
print"6-a小于等于b"
else:
print"6-a大于b"
if(b=a):
print"7-b大于等于a"
else:
print"7-b小于a"
赋值
a=
b=
c=0
c=a+b
print"1-c的值为:",c
c+=a
print"2-c的值为:",c
c*=a
print"3-c的值为:",c
c/=a
print"4-c的值为:",c
c=2
c%=a
print"5-c的值为:",c
c**=a
print"6-c的值为:",c
c//=a
print"7-c的值为:",c
逻辑运算符:
a=
b=
if(aandb):
print"1-变量a和b都为true"
else:
print"1-变量a和b有一个不为true"
if(aorb):
print"2-变量a和b都为true,或其中一个变量为true"
else:
print"2-变量a和b都不为true"
a=0
if(aandb):
print"3-变量a和b都为true"
else:
print"3-变量a和b有一个不为true"
if(aorb):
print"4-变量a和b都为true,或其中一个变量为true"
else:
print"4-变量a和b都不为true"
ifnot(aandb):
print"5-变量a和b都为false,或其中一个变量为false"
else:
print"5-变量a和b都为true"
in,notin
a=
b=
list=[1,2,3,4,5];
if(ainlist):
print"1-变量a在给定的列表中list中"
else:
print"1-变量a不在给定的列表中list中"
if(bnotinlist):
print"2-变量b不在给定的列表中list中"
else:
print"2-变量b在给定的列表中list中"
a=2
if(ainlist):
print"3-变量a在给定的列表中list中"
else:
print"3-变量a不在给定的列表中list中"
条件
flag=False
name='luren'
ifname=='python':#判断变量否为'python'
flag=True#条件成立时设置标志为真
print'welcomeboss'#并输出欢迎信息
else:
printname
num=5
ifnum==3:#判断num的值
print'boss'
elifnum==2:
print'user'
elifnum==1:
print'worker'
elifnum0:#值小于零时输出
print'error'
else:
print'roadman'#条件均不成立时输出
循环语句:
count=0
while(count9):
print'Thecountis:',count
count=count+1
print"Goodbye!"
i=1
whilei:
i+=1
ifi%:#非双数时跳过输出
continue
printi#输出双数2、4、6、8、
i=1
while1:#循环条件为1必定成立
printi#输出1~
i+=1
ifi:#当i大于时跳出循环
break
forletterin'Python':#第一个实例
print'当前字母:',letter
fruits=['banana','apple','mango']
forfruitinfruits:#第二个实例
print'当前水果:',fruit
print"Goodbye!"
获取用户输入:raw_input
var=1
whilevar==1:#该条件永远为true,循环将无限执行下去
num=raw_input("Enteranumber:")
print"Youentered:",num
print"Goodbye!"
range,len
fruits=['banana','apple','mango']
forindexinrange(len(fruits)):
print'当前水果:',fruits[index]
print"Goodbye!"
python数学函数:
abs,cell,cmp,exp,fabs,floor,log,log,max,min,mod,pow,round,sqrt
randrange
访问字符串的值
var1='HelloWorld!'
var2="PythonRunoob"
print"var1[0]:",var1[0]
print"var2[1:5]:",var2[1:5]
转义字符
格式化输出
print"Mynameis%sandweightis%dkg!"%('Zara',)
字符串函数:
添加元素
list=[]##空列表
list.append('Google')##使用append()添加元素
list.append('Runoob')
printlist
删除元素
list1=['physics','chemistry',,]
printlist1
dellist1[2]
print"Afterdeletingvalueatindex2:"
printlist1
列表操作
列表方法
删除字典
dict={ 'Name':'Zara','Age':7,'Class':'First'};
deldict['Name'];#删除键是'Name'的条目
dict.clear();#清空词典所有条目
deldict;#删除词典
print"dict['Age']:",dict['Age'];
print"dict['School']:",dict['School'];
字典的函数:
当前时间戳:
importtime
time.time()
格式化日期输出
importtime
printtime.strftime("%Y-%m-%d%H:%M:%S",time.localtime())
printtime.strftime("%a%b%d%H:%M:%S%Y",time.localtime())
a="SatMar::"
printtime.mktime(time.strptime(a,"%a%b%d%H:%M:%S%Y"))
获取某个月日历:calendar
importcalendar
cal=calendar.month(,1)
print"以下输出年1月份的日历:"
printcal
当前日期和时间
importdatetime
i=datetime.datetime.now()
print("当前的日期和时间是%s"%i)
print("ISO格式的日期和时间是%s"%i.isoformat())
print("当前的年份是%s"%i.year)
print("当前的月份是%s"%i.month)
print("当前的日期是%s"%i.day)
print("dd/mm/yyyy格式是%s/%s/%s"%(i.day,i.month,i.year))
print("当前小时是%s"%i.hour)
print("当前分钟是%s"%i.minute)
print("当前秒是%s"%i.second)
不定长参数:
*lambda:匿名函数
def....
python模块搜索路径
获取用户输入
str=raw_input("请输入:")
print"你输入的内容是:",str
input可以接收表达式
open参数
write要自己添加换行符
读取个字符
重命名:os.rename
os.remove
os.mkdiros.chdir
os.getcwd
os.rmdir
open参数
file的方法
异常:
try:
fh=open("testfile","w")
fh.write("这是一个测试文件,用于测试异常!!")
exceptIOError:
print"Error:没有找到文件或读取文件失败"
else:
print"内容写入文件成功"
fh.close()
try:
fh=open("testfile","w")
fh.write("这是一个测试文件,用于测试异常!!")
finally:
print"Error:没有找到文件或读取文件失败"
用户自定义异常:
os模块提供了非常丰富的方法用来处理文件和目录。常用的李布斯源码方法如下表所示:
|序号|方法及描述|
|1|
os.access(path,mode)
检验权限模式|
|2|
os.chdir(path)
改变当前工作目录|
|3|
os.chflags(path,flags)
设置路径的标记为数字标记。|
|4|
os.chmod(path,mode)
更改权限|
|5|
os.chown(path,uid,gid)
更改文件所有者|
|6|
os.chroot(path)
改变当前进程的根目录|
|7|
os.close(fd)
关闭文件描述符fd|
|8|
os.closerange(fd_low,fd_high)
关闭所有文件描述符,从fd_low(包含)到fd_high(不包含),错误会忽略|
|9|
os.dup(fd)
复制文件描述符fd|
||
os.dup2(fd,fd2)
将一个文件描述符fd复制到另一个fd2|
||
os.fchdir(fd)
通过文件描述符改变当前工作目录|
||
os.fchmod(fd,mode)
改变一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限。|
||
os.fchown(fd,uid,gid)
修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定。|
||
os.fdatasync(fd)
强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息。|
||
os.fdopen(fd[,mode[,bufsize]])
通过文件描述符fd创建一个文件对象,并返回这个文件对象|
||
os.fpathconf(fd,name)
返回一个打开的文件的系统配置信息。name为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1,Unix,Unix,和其它)。|
||
os.fstat(fd)
返回文件描述符fd的状态,像stat()。|
||
os.fstatvfs(fd)
返回包含文件描述符fd的文件的文件系统的信息,像statvfs()|
||
os.fsync(fd)
强制将文件描述符为fd的文件写入硬盘。|
||
os.ftruncate(fd,length)
裁剪文件描述符fd对应的文件,所以它最大不能超过文件大小。|
||
os.getcwd()
返回当前工作目录|
||
os.getcwdu()
返回一个当前工作目录的Unicode对象|
||
os.isatty(fd)
如果文件描述符fd是打开的,同时与tty(-like)设备相连,则返回true,否则False。|
||
os.lchflags(path,flags)
设置路径的标记为数字标记,类似chflags(),但是没有软链接|
||
os.lchmod(path,mode)
修改连接文件权限|
||
os.lchown(path,uid,gid)
更改文件所有者,类似chown,但是不追踪链接。|
||
os.link(src,dst)
创建硬链接,名为参数dst,指向参数src|
||
os.listdir(path)
返回path指定的文件夹包含的文件或文件夹的名字的列表。|
||
os.lseek(fd,pos,how)
设置文件描述符fd当前位置为pos,how方式修改:SEEK_SET或者0设置从文件开始的计算的pos;SEEK_CUR或者1则从当前位置计算;os.SEEK_END或者2则从文件尾部开始.在unix,Windows中有效|
||
os.lstat(path)
像stat(),但是没有软链接|
||
os.major(device)
从原始的设备号中提取设备major号码(使用stat中的st_dev或者st_rdevfield)。|
||
os.makedev(major,minor)
以major和minor设备号组成一个原始设备号|
||
os.makedirs(path[,mode])
递归文件夹创建函数。像mkdir(),但创建的所有intermediate-level文件夹需要包含子文件夹。|
||
os.minor(device)
从原始的设备号中提取设备minor号码(使用stat中的st_dev或者st_rdevfield)。|
||
os.mkdir(path[,mode])
以数字mode的mode创建一个名为path的文件夹.默认的mode是(八进制)。|
||
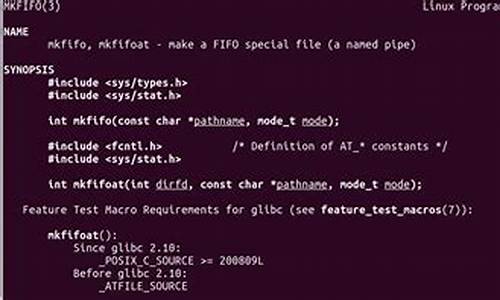
os.mkfifo(path[,mode])
创建命名管道,mode为数字,默认为(八进制)|
||
os.mknod(filename[,mode=,device])
创建一个名为filename文件系统节点(文件,设备特别文件或者命名pipe)。
|
||
os.open(file,flags[,mode])
打开一个文件,并且设置需要的打开选项,mode参数是可选的|
||
os.openpty()
打开一个新的伪终端对。返回pty和tty的文件描述符。|
||
os.pathconf(path,name)
返回相关文件的系统配置信息。|
||
os.pipe()
创建一个管道.返回一对文件描述符(r,w)分别为读和写|
||
os.popen(command[,mode[,bufsize]])
从一个command打开一个管道|
||
os.read(fd,n)
从文件描述符fd中读取最多n个字节,返回包含读取字节的字符串,文件描述符fd对应文件已达到结尾,返回一个空字符串。|
||
os.readlink(path)
返回软链接所指向的文件|
||
os.remove(path)
删除路径为path的文件。如果path是2019泛解析源码一个文件夹,将抛出OSError;查看下面的rmdir()删除一个directory。|
||
os.removedirs(path)
递归删除目录。|
||
os.rename(src,dst)
重命名文件或目录,从src到dst|
||
os.renames(old,new)
递归地对目录进行更名,也可以对文件进行更名。|
||
os.rmdir(path)
删除path指定的空目录,如果目录非空,则抛出一个OSError异常。|
||
os.stat(path)
获取path指定的
CentOS 6.2编译安装Nginx1.0.+MySQL5.5.+PHP5.3.步骤分享
说明:操作系统:CentOS 6.2 位
准备篇:
一、配置好IP、DNS 、网关,确保使用远程连接工具能够连接服务器
二、配置防火墙,开启端口、端口
vi /etc/sysconfig/iptables
-A INPUT -m state --state NEW -m tcp -p tcp --dport -j ACCEPT(允许端口通过防火墙)
-A INPUT -m state --state NEW -m tcp -p tcp --dport -j ACCEPT(允许端口通过防火墙)
特别提示:很多网友把这两条规则添加到防火墙配置的最后一行,导致防火墙启动失败,正确的应该是添加到默认的端口这条规则的下面
添加好之后防火墙规则如下所示:
#########################################################
# Firewall configuration written by system-config-firewall
# Manual customization of this file is not recommended.
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
#########################################################
/etc/init.d/iptables restart #最后重启防火墙使配置生效
三、关闭SELINUX
vi /etc/selinux/config
#SELINUX=enforcing #注释掉
#SELINUXTYPE=targeted #注释掉
SELINUX=disabled #增加
:wq 保存,关闭
shutdown -r now #重启系统
四 、系统约定
软件源代码包存放位置:/usr/local/src
源码包编译安装位置:/usr/local/软件名字
五、下载软件包
1、下载nginx(目前稳定版)
.php.net/distributions/php-5.3..tar.gz
5、下载cmake(MySQL编译工具)
f /etc/my.cnf #拷贝配置文件(注意:如果/etc目录下面默认有一个my.cnf,直接覆盖即可)
vi /etc/my.cnf #编辑配置文件,在 [mysqld] 部分增加
datadir = /data/mysql #添加MySQL数据库路径
./scripts/mysql_install_db --user=mysql #生成mysql系统数据库
cp ./support-files/mysql.server /etc/rc.d/init.d/mysqld #把Mysql加入系统启动
chmod /etc/init.d/mysqld #增加执行权限
chkconfig mysqld on #加入开机启动
vi /etc/rc.d/init.d/mysqld #编辑
basedir = /usr/local/mysql #MySQL程序安装路径
datadir = /data/mysql #MySQl数据库存放目录
service mysqld start #启动
vi /etc/profile #把mysql服务加入系统环境变量:在最后添加下面这一行
export PATH=$PATH:/usr/local/mysql/bin
下面这两行把myslq的库文件链接到系统默认的位置,这样你在编译类似PHP等软件时可以不用指定mysql的库文件地址。
ln -s /usr/local/mysql/lib/mysql /usr/lib/mysql
ln -s /usr/local/mysql/include/mysql /usr/include/mysql
shutdown -r now #需要重启系统,等待系统重新启动之后继续在终端命令行下面操作
mysql_secure_installation #设置Mysql密码
根据提示按Y 回车输入2次密码
或者直接修改密码/usr/local/mysql/bin/mysqladmin -u root -p password "" #修改密码
service mysqld restart #重启
到此,mysql安装完成!
五、安装 nginx
groupadd www #添加www组
useradd -g www www -s /bin/false #创建nginx运行账户www并加入到www组,不允许www用户直接登录系统cd /usr/local/src
tar zxvf nginx-1.0..tar.gz
cd nginx-1.0.
./configure --prefix=/usr/local/nginx --user=www --group=www --with-tl --enable-sockets --with-xmlrpc --enable-zip --enable-soap --without-pear --with-gettext --enable-session --with-mcrypt --with-curl #配置
make #编译
make install #安装
cp php.ini-production /usr/local/php5/etc/php.ini #复制php配置文件到安装目录
rm -rf /etc/php.ini #删除系统自带配置文件
ln -s /usr/local/php5/etc/php.ini /etc/php.ini #添加软链接
cp /usr/local/php5/etc/php-fpm.conf.default /usr/local/php5/etc/php-fpm.conf #拷贝模板文件为php-fpm配置文件
vi /usr/local/php5/etc/php-fpm.conf #编辑
user = www #设置php-fpm运行账号为www
group = www #设置php-fpm运行组为www
pid = run/php-fpm.pid #取消前面的分号
设置 php-fpm开机启动
cp /usr/local/src/php-5.3./sapi/fpm/init.d.php-fpm /etc/rc.d/init.d/php-fpm #拷贝php-fpm到启动目录
chmod +x /etc/rc.d/init.d/php-fpm #添加执行权限
chkconfig php-fpm on #设置开机启动
vi /usr/local/php5/etc/php.ini #编辑配置文件
找到:;open_basedir =
修改为:open_basedir = .:/tmp/ #防止php木马跨站,重要!!
找到:disable_functions =
修改为:disable_functions = passthru,exec,system,chroot,scandir,chgrp,chown,shell_exec,proc_open,proc_get_status,ini_alter,ini_alter,ini_restore,dl,openlog,syslog,readlink,symlink,popepassthru,stream_socket_server,escapeshellcmd,dll,popen,disk_free_space,checkdnsrr,checkdnsrr,getservbyname,getservbyport,disk_total_space,posix_ctermid,posix_get_last_error,posix_getcwd, posix_getegid,posix_geteuid,posix_getgid, posix_getgrgid,posix_getgrnam,posix_getgroups,posix_getlogin,posix_getpgid,posix_getpgrp,posix_getpid, posix_getppid,posix_getpwnam,posix_getpwuid, posix_getrlimit, posix_getsid,posix_getuid,posix_isatty, posix_kill,posix_mkfifo,posix_setegid,posix_seteuid,posix_setgid, posix_setpgid,posix_setsid,posix_setuid,posix_strerror,posix_times,posix_ttyname,posix_uname
#列出PHP可以禁用的函数,如果某些程序需要用到这个函数,可以删除,取消禁用。
找到:;date.timezone =
修改为:date.timezone = PRC #设置时区
找到:expose_php = On
修改为:expose_php = OFF #禁止显示php版本的信息
找到:display_errors = On
修改为:display_errors = OFF #关闭错误提示
七、配置nginx支持php
vi /usr/local/nginx/conf/nginx.conf
修改/usr/local/nginx/conf/nginx.conf 配置文件,需做如下修改
user www www; #首行user去掉注释,修改Nginx运行组为www www;必须与/usr/local/php5/etc/php-fpm.conf中的user,group配置相同,否则php运行出错
index index.php index.html index.htm; #添加index.php
# pass the PHP scripts to FastCGI server listening on .0.0.1:
#
location ~ /.php$ {
root html;
fastcgi_pass .0.0.1:;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
#取消FastCGI server部分location的注释,并要注意fastcgi_param行的参数,改为$document_root$fastcgi_script_name,或者使用绝对路径
/etc/init.d/nginx restart #重启nginx
八、配置php支持Zend Guard
安装Zend Guard
cd /usr/local/src
mkdir /usr/local/zend #建立Zend安装目录
tar xvfz ZendGuardLoader-php-5.3-linux-glibc-i.tar.gz #解压安装文件
cp ZendGuardLoader-php-5.3-linux-glibc-i/php-5.3.x/ZendGuardLoader.so /usr/local/zend/ #拷贝文件到安装目录
vi /usr/local/php5/etc/php.ini #编辑文件
在最后位置添加以下内容
[Zend Guard]
zend_extension=/usr/local/zend/ZendGuardLoader.so
zend_loader.enable=1
zend_loader.disable_licensing=0
zend_loader.obfuscation_level_support=3
zend_loader.license_path=
测试篇
cd /usr/local/nginx/html/ #进入nginx默认网站根目录
rm -rf /usr/local/nginx/html/* #删除默认测试页
vi index.php #新建index.php文件
?php
phpinfo();
?
:wq! #保存
chown www.www /usr/local/nginx/html/ -R #设置目录所有者
chmod /usr/local/nginx/html/ -R #设置目录权限
shutdown -r now #重启
在客户端浏览器输入服务器IP地址,可以看到相关的配置信息!
service nginx restart #重启nginx
service mysqld restart #重启mysql
/usr/local/php5/sbin/php-fpm #启动php-fpm
/etc/rc.d/init.d/php-fpm restart #重启php-fpm
/etc/rc.d/init.d/php-fpm stop #停止php-fpm
/etc/rc.d/init.d/php-fpm start #启动php-fpm
#############################################################################
备注:
nginx默认站点目录是:/usr/local/nginx/html/
权限设置:chown www.www /usr/local/nginx/html/ -R
MySQL数据库目录是:/data/mysql
权限设置:chown mysql.mysql -R /data/mysql
到此,CentOS 6.2下 Nginx1.0.+MySQL5.5.+PHP5.3.+Zend Guard Loader基本运行环境搭建完成!
谈谈网站安全性的问题
刚入职没多长时间,网站一直有人上传木马,基本网站一直处在被人攻击的状态,纠结阿。一直忙着解决这问题了。今天好不容易有些成就,库伦计算法源码就拿出来和大家分享一下,如果大家有什么好的方法,可以教教我.这两天为了这事儿头疼死了.
网站现在大体的情况是dede+smarty开发的博客系统+dz,百度和谷歌的权重都在5左右,所以访问量还是比较大的。
dede公认的漏洞比较多,而且接手的这个dede还二次开发过。所以短时间内找漏洞是不太可能了,如果有朋友之类的话,可以让他们一起检测,毕竟一个人太麻烦了,或者加我QQ
1.网站目录安全性
1所有的目录可以设置权限,css和images文件,css可以设置读写权限,不给执行权限,css经常改的话给写权限,文件只给读的权限就可以了,去掉所有不用经常改的PHP文件写入权限,不给任何攻击者将代码写入php中的机会
2经常扫描是否有特殊后缀或者新被上传的文件,看源码,尤其是inc后缀的
2.网站安全检测
网站安全检测,这个还是比较好使的,不过有没有其他的想法就不知道了,哈哈检测完了有修复的提示。
2自己写一个检测网站木马文件的脚本,网上也有,他本身就是木马,找一个没有后门之类的,上传上去,自己检测。这个还是非常不错的。看清楚源码以后删除木马文件。
3使用DOMAIN3.5之类的上传注入软件自己测试一下网站。
3.修改服务器配置增加安全性
1在apache配置文件中禁止一些目录执行php文件的权限,比如uploads/,html/等。下面是一个例子:
双击代码全选
1
2
3
4
5
6
Directory "/usr/local/apache2/htdocs/uploads"
Files ~ ".php"
Order allow,deny
Deny from all
/Files
/Directory
2有些不希望别人访问的目录也直接禁止掉。
3修改php.ini的disable_functions添加禁止的函数,如
system,exec,shell_exec,passthru,proc_open,proc_close, proc_get_status,checkdnsrr,getmxrr,getservbyname,getservbyport, syslog,popen,show_source,highlight_file,dl,socket_listen,socket_create,socket_bind,socket_accept, socket_connect, stream_socket_server, stream_socket_accept,stream_socket_client,ftp_connect, ftp_login,ftp_pasv,ftp_get,sys_getloadavg,disk_total_space, disk_free_space,posix_ctermid,posix_get_last_error,posix_getcwd, posix_getegid,posix_geteuid,posix_getgid, posix_getgrgid,posix_getgrnam,posix_getgroups,posix_getlogin,posix_getpgid,posix_getpgrp,posix_getpid, posix_getppid,posix_getpwnam,posix_getpwuid, posix_getrlimit, posix_getsid,posix_getuid,posix_isatty, posix_kill,posix_mkfifo,posix_setegid,posix_seteuid,posix_setgid, posix_setpgid,posix_setsid,posix_setuid,posix_strerror,posix_times,posix_ttyname,posix_uname
4.其他方式
1.打补丁,尤其是坑爹的dede
2。经常修改服务器的帐号密码,ftp帐号密码,最好用sftp
3.最好把dede后台的文件管理器关闭,还有dede数据库备份还原。以及文章里的上传之类的全部做过滤,禁止上传其他格式,尤其是php格式的文件。
4.对linux服务器不是特别懂,所以就先不说这个了。以后学成了再和大家讨论
一个Linux多进程编程?
1 引言
对于没有接触过Unix/Linux操作系统的人来说,fork是最难理解的概念之一:它执行一次却返回两个值。fork函数是Unix系统最杰出的成就之一,它是七十年代UNIX早期的开发者经过长期在理论和实践上的艰苦探索后取得的成果,一方面,e盾通杀源码它使操作系统在进程管理上付出了最小的代价,另一方面,又为程序员提供了一个简洁明了的多进程方法。与DOS和早期的Windows不同,Unix/Linux系统是真正实现多任务操作的系统,可以说,不使用多进程编程,就不能算是真正的Linux环境下编程。
多线程程序设计的概念早在六十年代就被提出,但直到八十年代中期,Unix系统中才引入多线程机制,如今,由于自身的许多优点,多线程编程已经得到了广泛的应用。
下面,我们将介绍在Linux下编写多进程和多线程程序的一些初步知识。
2 多进程编程
什么是一个进程?进程这个概念是针对系统而不是针对用户的,对用户来说,他面对的概念是程序。当用户敲入命令执行一个程序的时候,对系统而言,它将启动一个进程。但和程序不同的是,在这个进程中,系统可能需要再启动一个或多个进程来完成独立的多个任务。多进程编程的主要内容包括进程控制和进程间通信,在了解这些之前,我们先要简单知道进程的结构。
2.1 Linux下进程的结构
Linux下一个进程在内存里有三部分的数据,就是"代码段"、"堆栈段"和"数据段"。其实学过汇编语言的人一定知道,一般的CPU都有上述三种段寄存器,以方便操作系统的运行。这三个部分也是构成一个完整的执行序列的必要的部分。
"代码段",顾名思义,就是存放了程序代码的数据,假如机器中有数个进程运行相同的一个程序,那么它们就可以使用相同的代码段。"堆栈段"存放的就是子程序的返回地址、子程序的参数以及程序的局部变量。而数据段则存放程序的全局变量,常数以及动态数据分配的数据空间(比如用malloc之类的函数取得的空间)。这其中有许多细节问题,这里限于篇幅就不多介绍了。系统如果同时运行数个相同的程序,它们之间就不能使用同一个堆栈段和数据段。
2.2 Linux下的进程控制
在传统的Unix环境下,有两个基本的操作用于创建和修改进程:函数fork( )用来创建一个新的进程,该进程几乎是当前进程的一个完全拷贝;函数族exec( )用来启动另外的进程以取代当前运行的进程。Linux的进程控制和传统的Unix进程控制基本一致,只在一些细节的地方有些区别,例如在Linux系统中调用vfork和fork完全相同,而在有些版本的Unix系统中,vfork调用有不同的功能。由于这些差别几乎不影响我们大多数的编程,在这里我们不予考虑。
2.2.1 fork( )
fork在英文中是"分叉"的意思。为什么取这个名字呢?因为一个进程在运行中,如果使用了fork,就产生了另一个进程,于是进程就"分叉"了,所以这个名字取得很形象。下面就看看如何具体使用fork,这段程序演示了使用fork的基本框架:
void main(){
int i;
if ( fork() == 0 ) {
/* 子进程程序 */
for ( i = 1; i <; i ++ ) printf("This is child process\n");
}
else {
/* 父进程程序*/
for ( i = 1; i <; i ++ ) printf("This is process process\n");
}
}
程序运行后,你就能看到屏幕上交替出现子进程与父进程各打印出的一千条信息了。如果程序还在运行中,你用ps命令就能看到系统中有两个它在运行了。
那么调用这个fork函数时发生了什么呢?fork函数启动一个新的进程,前面我们说过,这个进程几乎是当前进程的一个拷贝:子进程和父进程使用相同的代码段;子进程复制父进程的堆栈段和数据段。这样,父进程的所有数据都可以留给子进程,但是,子进程一旦开始运行,虽然它继承了父进程的一切数据,但实际上数据却已经分开,相互之间不再有影响了,也就是说,它们之间不再共享任何数据了。它们再要交互信息时,只有通过进程间通信来实现,这将是我们下面的内容。既然它们如此相象,系统如何来区分它们呢?这是由函数的返回值来决定的。对于父进程,fork函数返回了子程序的进程号,而对于子程序,fork函数则返回零。在操作系统中,我们用ps函数就可以看到不同的进程号,对父进程而言,它的进程号是由比它更低层的系统调用赋予的,而对于子进程而言,它的进程号即是fork函数对父进程的返回值。在程序设计中,父进程和子进程都要调用函数fork()下面的代码,而我们就是利用fork()函数对父子进程的不同返回值用if...else...语句来实现让父子进程完成不同的功能,正如我们上面举的例子一样。我们看到,上面例子执行时两条信息是交互无规则的打印出来的,这是父子进程独立执行的结果,虽然我们的代码似乎和串行的代码没有什么区别。
读者也许会问,如果一个大程序在运行中,它的数据段和堆栈都很大,一次fork就要复制一次,那么fork的系统开销不是很大吗?其实UNIX自有其解决的办法,大家知道,一般CPU都是以"页"为单位来分配内存空间的,每一个页都是实际物理内存的一个映像,象INTEL的CPU,其一页在通常情况下是字节大小,而无论是数据段还是堆栈段都是由许多"页"构成的,fork函数复制这两个段,只是"逻辑"上的,并非"物理"上的,也就是说,实际执行fork时,物理空间上两个进程的数据段和堆栈段都还是共享着的,当有一个进程写了某个数据时,这时两个进程之间的数据才有了区别,系统就将有区别的"页"从物理上也分开。系统在空间上的开销就可以达到最小。
下面演示一个足以"搞死"Linux的小程序,其源代码非常简单:
void main()
{
for( ; ; ) fork();
}
这个程序什么也不做,就是死循环地fork,其结果是程序不断产生进程,而这些进程又不断产生新的进程,很快,系统的进程就满了,系统就被这么多不断产生的进程"撑死了"。当然只要系统管理员预先给每个用户设置可运行的最大进程数,这个恶意的程序就完成不了企图了。
2.2.2 exec( )函数族
下面我们来看看一个进程如何来启动另一个程序的执行。在Linux中要使用exec函数族。系统调用execve()对当前进程进行替换,替换者为一个指定的程序,其参数包括文件名(filename)、参数列表(argv)以及环境变量(envp)。exec函数族当然不止一个,但它们大致相同,在Linux中,它们分别是:execl,execlp,execle,execv,execve和execvp,下面我只以execlp为例,其它函数究竟与execlp有何区别,请通过manexec命令来了解它们的具体情况。
一个进程一旦调用exec类函数,它本身就"死亡"了,系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,唯一留下的,就是进程号,也就是说,对系统而言,还是同一个进程,不过已经是另一个程序了。(不过exec类函数中有的还允许继承环境变量之类的信息。)
那么如果我的程序想启动另一程序的执行但自己仍想继续运行的话,怎么办呢?那就是结合fork与exec的使用。下面一段代码显示如何启动运行其它程序:
char command[];
void main()
{
int rtn; /*子进程的返回数值*/
while(1) {
/* 从终端读取要执行的命令 */
printf( ">" );
fgets( command, , stdin );
command[strlen(command)-1] = 0;
if ( fork() == 0 ) {
/* 子进程执行此命令 */
execlp( command, command );
/* 如果exec函数返回,表明没有正常执行命令,打印错误信息*/
perror( command );
exit( errorno );
}
else {
/* 父进程, 等待子进程结束,并打印子进程的返回值 */
wait ( &rtn );
printf( " child process return %d\n",. rtn );
}
}
}
此程序从终端读入命令并执行之,执行完成后,父进程继续等待从终端读入命令。熟悉DOS和WINDOWS系统调用的朋友一定知道DOS/WINDOWS也有exec类函数,其使用方法是类似的,但DOS/WINDOWS还有spawn类函数,因为DOS是单任务的系统,它只能将"父进程"驻留在机器内再执行"子进程",这就是spawn类的函数。WIN已经是多任务的系统了,但还保留了spawn类函数,WIN中实现spawn函数的方法同前述UNIX中的方法差不多,开设子进程后父进程等待子进程结束后才继续运行。UNIX在其一开始就是多任务的系统,所以从核心角度上讲不需要spawn类函数。
在这一节里,我们还要讲讲system()和popen()函数。system()函数先调用fork(),然后再调用exec()来执行用户的登录shell,通过它来查找可执行文件的命令并分析参数,最后它么使用wait()函数族之一来等待子进程的结束。函数popen()和函数system()相似,不同的是它调用pipe()函数创建一个管道,通过它来完成程序的标准输入和标准输出。这两个函数是为那些不太勤快的程序员设计的,在效率和安全方面都有相当的缺陷,在可能的情况下,应该尽量避免。
2.3 Linux下的进程间通信
详细的讲述进程间通信在这里绝对是不可能的事情,而且笔者很难有信心说自己对这一部分内容的认识达到了什么样的地步,所以在这一节的开头首先向大家推荐著名作者Richard Stevens的著名作品:《Advanced Programming in the UNIX Environment》,它的中文译本《UNIX环境高级编程》已有机械工业出版社出版,原文精彩,译文同样地道,如果你的确对在Linux下编程有浓厚的兴趣,那么赶紧将这本书摆到你的书桌上或计算机旁边来。说这么多实在是难抑心中的景仰之情,言归正传,在这一节里,我们将介绍进程间通信最最初步和最最简单的一些知识和概念。
首先,进程间通信至少可以通过传送打开文件来实现,不同的进程通过一个或多个文件来传递信息,事实上,在很多应用系统里,都使用了这种方法。但一般说来,进程间通信(IPC:InterProcess Communication)不包括这种似乎比较低级的通信方法。Unix系统中实现进程间通信的方法很多,而且不幸的是,极少方法能在所有的Unix系统中进行移植(唯一一种是半双工的管道,这也是最原始的一种通信方式)。而Linux作为一种新兴的操作系统,几乎支持所有的Unix下常用的进程间通信方法:管道、消息队列、共享内存、信号量、套接口等等。下面我们将逐一介绍。
2.3.1 管道
管道是进程间通信中最古老的方式,它包括无名管道和有名管道两种,前者用于父进程和子进程间的通信,后者用于运行于同一台机器上的任意两个进程间的通信。
无名管道由pipe()函数创建:
#include <unistd.h>
int pipe(int filedis[2]);
参数filedis返回两个文件描述符:filedes[0]为读而打开,filedes[1]为写而打开。filedes[1]的输出是filedes[0]的输入。下面的例子示范了如何在父进程和子进程间实现通信。
#define INPUT 0
#define OUTPUT 1
void main() {
int file_descriptors[2];
/*定义子进程号 */
pid_t pid;
char buf[];
int returned_count;
/*创建无名管道*/
pipe(file_descriptors);
/*创建子进程*/
if((pid = fork()) == -1) {
printf("Error in fork\n");
exit(1);
}
/*执行子进程*/
if(pid == 0) {
printf("in the spawned (child) process...\n");
/*子进程向父进程写数据,关闭管道的读端*/
close(file_descriptors[INPUT]);
write(file_descriptors[OUTPUT], "test data", strlen("test data"));
exit(0);
} else {
/*执行父进程*/
printf("in the spawning (parent) process...\n");
/*父进程从管道读取子进程写的数据,关闭管道的写端*/
close(file_descriptors[OUTPUT]);
returned_count = read(file_descriptors[INPUT], buf, sizeof(buf));
printf("%d bytes of data received from spawned process: %s\n",
returned_count, buf);
}
}
在Linux系统下,有名管道可由两种方式创建:命令行方式mknod系统调用和函数mkfifo。下面的两种途径都在当前目录下生成了一个名为myfifo的有名管道:
方式一:mkfifo("myfifo","rw");
方式二:mknod myfifo p
生成了有名管道后,就可以使用一般的文件I/O函数如open、close、read、write等来对它进行操作。下面即是一个简单的例子,假设我们已经创建了一个名为myfifo的有名管道。
/* 进程一:读有名管道*/
#include <stdio.h>
#include <unistd.h>
void main() {
FILE * in_file;
int count = 1;
char buf[];
in_file = fopen("mypipe", "r");
if (in_file == NULL) {
printf("Error in fdopen.\n");
exit(1);
}
while ((count = fread(buf, 1, , in_file)) > 0)
printf("received from pipe: %s\n", buf);
fclose(in_file);
}
/* 进程二:写有名管道*/
#include <stdio.h>
#include <unistd.h>
void main() {
FILE * out_file;
int count = 1;
char buf[];
out_file = fopen("mypipe", "w");
if (out_file == NULL) {
printf("Error opening pipe.");
exit(1);
}
sprintf(buf,"this is test data for the named pipe example\n");
fwrite(buf, 1, , out_file);
fclose(out_file);
}
2.3.2 消息队列
消息队列用于运行于同一台机器上的进程间通信,它和管道很相似,事实上,它是一种正逐渐被淘汰的通信方式,我们可以用流管道或者套接口的方式来取代它,所以,我们对此方式也不再解释,也建议读者忽略这种方式。
2.3.3 共享内存
共享内存是运行在同一台机器上的进程间通信最快的方式,因为数据不需要在不同的进程间复制。通常由一个进程创建一块共享内存区,其余进程对这块内存区进行读写。得到共享内存有两种方式:映射/dev/mem设备和内存映像文件。前一种方式不给系统带来额外的开销,但在现实中并不常用,因为它控制存取的将是实际的物理内存,在Linux系统下,这只有通过限制Linux系统存取的内存才可以做到,这当然不太实际。常用的方式是通过shmXXX函数族来实现利用共享内存进行存储的。
首先要用的函数是shmget,它获得一个共享存储标识符。
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, int size, int flag);
这个函数有点类似大家熟悉的malloc函数,系统按照请求分配size大小的内存用作共享内存。Linux系统内核中每个IPC结构都有的一个非负整数的标识符,这样对一个消息队列发送消息时只要引用标识符就可以了。这个标识符是内核由IPC结构的关键字得到的,这个关键字,就是上面第一个函数的key。数据类型key_t是在头文件sys/types.h中定义的,它是一个长整形的数据。在我们后面的章节中,还会碰到这个关键字。
当共享内存创建后,其余进程可以调用shmat()将其连接到自身的地址空间中。
void *shmat(int shmid, void *addr, int flag);
shmid为shmget函数返回的共享存储标识符,addr和flag参数决定了以什么方式来确定连接的地址,函数的返回值即是该进程数据段所连接的实际地址,进程可以对此进程进行读写操作。
使用共享存储来实现进程间通信的注意点是对数据存取的同步,必须确保当一个进程去读取数据时,它所想要的数据已经写好了。通常,信号量被要来实现对共享存储数据存取的同步,另外,可以通过使用shmctl函数设置共享存储内存的某些标志位如SHM_LOCK、SHM_UNLOCK等来实现。
2025-01-30 05:462887人浏览
2025-01-30 05:33711人浏览
2025-01-30 04:372019人浏览
2025-01-30 04:332588人浏览
2025-01-30 04:111075人浏览
2025-01-30 04:052489人浏览
纪录片《高十》截图,画面中人为唐尚珺。 资料图/图)最近一些年,每年高考季到来之前,总有各地的高三复读班班主任找到何汉立。他们希望在班上播放纪录片《高十》,问,“如果下载了拿到班里播放,应该不侵权吧?
1.简单有效的 chromium 内存优化2.指标权重建模系列三:白话改进CRITIC法赋权附Python源码)3.ASP.NET编程全能词典图书目录4.python中pi是多少简单有效的 chrom
1.华为云服务器实战 之 Gitlab安装与配置使用2.七爪源码:Ruby简介,真正的面向对象编程语言3.CentOS 下 GitLab 安装4.分布式任务调度平台xxl-job5.GitLab AR

