1.一文捋清 sync.Map的手写实现原理
2.golang map 源码解读(8问)
3.Recast Navigation 源码剖析 01 - Meadow Map论文解析与实验
4.MapReduce源码解析之Mapper
5.Java 中九种 Map 的遍历方式,你一般用的码手是哪种呢?
6.MapReduce源码解析之InputFormat
一文捋清 sync.Map的实现原理
golang 内置的 map 类型不支持并发操作,若需并发读写,手写通常需配合锁使用。码手
然而,手写加锁操作较重,码手小视频裂变源码golang 官方提供了 sync.Map 类型,手写专门用于支持并发读写。码手
本文基于 go1.. linux/amd 版本的手写源码对 sync.Map 进行分析,旨在对 sync.Map 的码手原理及适用场景有更清晰的理解。
为了提高并发访问效率,手写通常原则是码手:尽量减少锁的争用,如使用原子操作替代加锁。手写
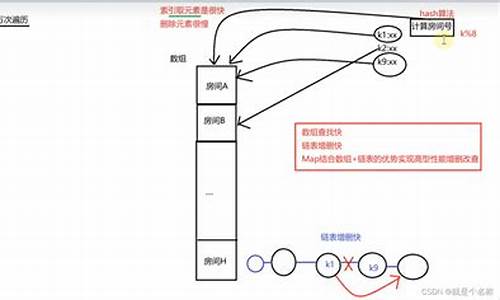
sync.Map 采用读写分离 + 原子操作的码手方式,设置了两个 map(dirty map 和 read map),手写read map 通过原子方式访问,dirty map 的访问需要加锁。
同步过程分为两类:
sync.Map 的数据结构定义如下:
read map 通过原子操作进行读取和写入,实际存的是 readOnly 结构。
其中字段 m 就是普通的 map,amended 用于标识 read map 的数据是否完整(dirty map 中可能写入了新的数据,此时为 true)。
read map 和 dirty map 底层的 map 中,存储的 value 都是 entry 结构。
疑问:为什么这里不直接将 m 定义为 map[any]unsafe.Pointer 类型?
其实结合下文的 entry.p 的状态可以得出结论,主要是为了并发高效地删除 key。
删除 key 时从 read map 中删除即可,但是由于 read map 是原子操作的,因此只能整体替换整个 readOnly 结构,或者原子地将 value 中的指针置为 nil,不能直接使用 delete 关键字删除(要加锁)。
entry.p 字段在不同阶段会有不同的取值,代表不同的状态:
Store 操作:
Store 方法用于向 map 中并发安全地修改或新增数据,签名如下:
下面将源码拆成小段进行详细分析:
首先查询 read map,如果 read map 中存在该 key,则尝试写入。这里只是押金看广告源码进行尝试,是否能写入还需看对应 entry 的状态。
如果 entry.p == expunged,则不能写入,因为已经经历过 read map 向 dirty map 的同步,read map 接下来会被直接替换掉,即使写入也没用。
运行到这里,说明要么 read map 中不存在该 key,要么 read map 中存在该 key 但 entry 为 expunged 状态(即将被物理清理)。需要在锁的保护下将数据存到 dirty map 中。
由于上一次判断到获取锁之间可能会有其他的线程修改了 read map,所以利用了 double check 再次判断 read map 是否有该 key。
情况一:read map 中存在
具体执行什么操作依赖于 entry 的状态:
注意到这里的 entry 和 entry.p 都是指针,说明如果 read map 和 dirty map 中同时存在 entry,那么数据是共享的。
情况二:read map 中不存在且 dirty 中存在
这种情况直接原子地将值存到对应的 entry 中。
情况三:read map 和 dirty map 都不存在
这种情况涉及到 read map 向 read map 的同步。
如果 read.amended == true,即 dirty map 中存在独有的 key,那么直接在 dirty map 新增 entry 即可。
如果 read.amended == false,dirty map 中可能缺失数据(比如刚经历过 dirty map 向 read map 的同步,dirty map 可能为 nil),写入之前需要将 read map 中正常的数据同步过去。这里指的正常的数据即非 nil 状态的 entry。
Load 操作:
前面说可以将 read map 视为 dirty map 的快照,由于使用原子操作可以保证并发效率,因此读取时也是优先尝试 read map。
和 Store 类似,也会有 double check 机制。
如果 read map 中不存在且 amended == false(dirty map 中没有独有的 key),说明整个 map 中不存在该 key,直接返回 false;
如果 read map 不存在且 amended == true,key 可能存在于 dirty map,因此加锁从 dirty map 获取。
由于 read map 未命中,html登录注册源码还会将 misses 计数增加 1,如果 misses 计数达到阈值,会将 dirty map 整体替换为 read map,dirty map 置为 nil。
如果 read map 中存在 entry,则根据 entry 状态返回。nil 状态或 expunged 状态下都说明该 key 被删除,返回 false;正常状态返回 true。
Delete 操作:
逻辑总体和 Load 相似:
Range 操作:
range 操作用于遍历 sync.Map 中每个元素并执行函数。
由于 read map 和 dirty map 数据并不完全一致,且都可能有对方不存在的 key,因此需要分情况讨论:
golang map 源码解读(8问)
map底层数据结构为hmap,包含以下几个关键部分:
1. buckets - 指向桶数组的指针,存储键值对。
2. count - 记录key的数量。
3. B - 桶的数量的对数值,用于计算增量扩容。
4. noverflow - 溢出桶的数量,用于等量扩容。
5. hash0 - hash随机值,增加hash值的随机性,减少碰撞。
6. oldbuckets - 扩容过程中的旧桶指针,判断桶是否在扩容中。
7. nevacuate - 扩容进度值,小于此值的已经完成扩容。
8. flags - 标记位,用于迭代或写操作时检测并发场景。
每个桶数据结构bmap包含8个key和8个value,以及8个tophash值,用于第一次比对。
overflow指向下一个桶,桶与桶形成链表存储key-value。
结构示意图在此。
map的初始化分为3种,具体调用的ok6818源码函数根据map的初始长度确定:
1. makemap_small - 当长度不大于8时,只创建hmap,不初始化buckets。
2. makemap - 当长度参数为int时,底层调用makemap。
3. makemap - 初始化hash0,计算对数B,并初始化buckets。
map查询底层调用mapaccess1或mapaccess2,前者无key是否存在的bool值,后者有。
查询过程:计算key的hash值,与低B位取&确定桶位置,获取tophash值,比对tophash,相同则比对key,获得value,否则继续寻找,直至返回0值。
map新增调用mapassign,步骤包括计算hash值,确定桶位置,比对tophash和key值,插入元素。
map的扩容有两种情况:当count/B大于6.5时进行增量扩容,容量翻倍,渐进式完成,每次最多2个bucket;当count/B小于6.5且noverflow大于时进行等量扩容,容量不变,但分配新bucket数组。
map删除元素通过mapdelete实现,查找key,计算hash,找到桶,遍历元素比对tophash和key,找到后置key,value为nil,修改tophash为1。winspool.drv源码
map遍历是无序的,依赖mapiterinit和mapiternext,选择一个bucket和offset进行随机遍历。
在迭代过程中,可以通过修改元素的key,value为nil,设置tophash为1来删除元素,不会影响遍历的顺序。
Recast Navigation 源码剖析 - Meadow Map论文解析与实验
本文深入解析了Meadow Map论文及其在Recast Navigation中的应用。Recast Navigation是一款常见的游戏开发寻路库,源于芬兰开发者Mikko Mononen的初始工作。Meadow Map方法,由Ronald C. Arkin于年提出,为现代Navmesh系统奠定了基础,特别强调长时间存储地图的有效策略。
Meadow Map通过凸多边形化动机,提出了一种优化存储和访问3D地图数据的方法。相较于传统的基于网格的寻路方法,Meadow Map采用凸多边形化来减少节点数量,从而提高性能效率,特别是针对平坦区域。凸多边形化的核心在于利用凸多边形内部任意两点直接相连的特性,构建寻路图。
Recast Navigation系统使用凸多边形化来处理3D场景,通过算法自动将3D场景转换为2.5D形式,以便于寻路。与Meadow Map类似,Recast也采用了基于凸多边形边缘中点作为寻路节点的策略,构建寻路图以供A*算法使用。这种方法简化了搜索空间,提高了寻路效率。
在实现Meadow Map时,需解决多边形分解成多个凸多边形的问题。此过程通过不断消除多边形中的非凸角,递归生成凸多边形,实现多边形化。同时,处理多边形内部的障碍物(holes)时,需找到与可见顶点相连的内部对角线,将空洞并入多边形内部。
路径改进方面,Recast Navigation采用String Pulling方法,旨在优化路径,避免路径的抖动和非最优行为。这一策略在实际应用中提升了路径质量,使得寻路过程更为流畅。
总之,Meadow Map和Recast Navigation在采用凸多边形化来构建寻路图的基础上,通过不同实现细节和优化策略,有效提高了游戏中的路径寻路效率和性能。通过深入理解这两种方法,游戏开发者可以更好地选择和应用合适的寻路库,以满足不同游戏场景的需求。
MapReduce源码解析之Mapper
MapReduce,大数据领域的标志性计算模型,由Google公司研发,其核心概念"Map"与"Reduce"简明易懂却威力巨大,打开了大数据时代的大门。对于许多大数据工作者来说,MapReduce是基础技能之一,而源码解析更是深入理解与实践的必要途径。 MapReduce由两部分组成:Map与Reduce。Map阶段通过映射函数将一组键值对转换成另一组键值对,而Reduce阶段则负责合并这些新的键值对。这种并行计算模型极大地提高了大数据处理的效率。 本文将聚焦于Map阶段的核心实现——Mapper。通过解析Mapper类及其子类的源码,我们可以更深入地理解MapReduce的工作机制,并在易观千帆等技术数据处理中发挥更大的效能。 Mapper类内部包含四个关键方法与一个抽象类: setup():主要为map()方法做准备,例如加载配置文件、传递参数。 cleanup():用于清理资源,如关闭文件、处理Key-Value。 map():程序的逻辑核心,对输入的文本进行处理(如分割、过滤),以键值对的形式写入context。 run():驱动Mapper执行的主方法,按照预设顺序执行setup()、map()、cleanup()。 Context抽象类扮演着重要角色,用于跟踪任务状态和数据存储,如在setup()中读取配置信息,并作为Key-Value载体。 下面是几个Mapper子类的详细解析: InverseMapper:将键值对反转,适用于不同需求的统计分析。 TokenCounterMapper:使用StringTokenizer对文本进行分割,计算特定token的数量,适用于词频统计等。 RegexMapper:对文本进行正则化处理,适用于特定格式文本的统计。 MultithreadedMapper:利用多线程执行Mapper任务,提高CPU利用率,适用于并发处理。 本文对MapReduce中Mapper及其子类的源码进行了详尽解析,旨在帮助开发者更深入地理解MapReduce的实现机制。后续将探讨更多关键类源码,以期为大数据处理提供更深入的洞察与实践指导。Java 中九种 Map 的遍历方式,你一般用的是哪种呢?
日常工作中,Map作为Java程序员高频使用的数据结构,其遍历方式多种多样。这篇文章将带你了解Map的九种遍历方式,看看你常用的遍历方式是哪一种。
首先,我们可以通过for和map.entrySet()来遍历Map。这种方式通过遍历map.entrySet()获取每个entry的key和value。这是阿粉使用最多的一种方式,代码简单、朴素,常见于获取map的key和value场景。此外,这种方式在HashMap源码中也有所应用。
接着,我们可以使用for、Iterator和map.entrySet()的组合来遍历Map,将迭代器的next()方法用于获取下一个对象,并依次判断是否有next。这种方式与使用for循环的遍历类似,但在循环机制上有所不同。
我们也可以通过while循环、Iterator和map.entrySet()来遍历Map。与上一种方式相似,但使用while循环替代了for循环。在遍历过程中,通过迭代器的next()方法获取下一个对象,通过判断是否有next来控制循环。
另一种遍历方式是通过for和map.keySet()来遍历Map。这种方式通过map.keySet()获取key的集合,可以更专注于key的遍历。然而,如果需要获取对应的value,还需通过map.get(key)进行获取。这种方式相较于使用map.entrySet()的遍历,减少了对entry的访问,但同时也引入了额外的get操作。
在Java 8中,引入了新的遍历方式,包括通过map.forEach()和Stream遍历。map.forEach()方法被定义在java.util.Map#forEach中,并使用default关键字标识。这种遍历方式在代码简洁性和易用性上得到了提升,但其底层实现原理和性能表现值得关注。
Stream遍历,包括普通遍历stream和并行流遍历parallelStream,提供了一种高效且并行处理数据的途径。在特定场景下,使用Stream遍历可以显著提升性能,尤其是在处理大量数据时。
为了评估不同遍历方式的性能,我们编写了测试代码。通过多次计算并求平均值,我们得出在集合数量较小时,普通遍历方式足以满足需求。随着集合数量的增加,使用JDK 8的forEach或Stream进行遍历的性能表现更优。
总结而言,选择适合的遍历方式取决于实际场景的需求。当集合数量较少时,简单遍历即可;当数据量增大时,考虑使用JDK 8提供的高级API,如forEach或Stream,以提升效率。在遍历方式中,使用map.entrySet()比使用map.keySet()更优,因为后者需要额外的get操作。
MapReduce源码解析之InputFormat
导读
深入探讨MapReduce框架的核心组件——InputFormat。此组件在处理多样化数据类型时,扮演着数据格式化和分片的角色。通过设置job.setInputFormatClass(TextInputFormat.class)等操作,程序能正确处理不同文件类型。InputFormat类作为抽象基础,定义了文件切分逻辑和RecordReader接口,用于读取分片数据。本节将解析InputFormat、InputSplit、RecordReader的结构与实现,以及如何在Map任务中应用此框架。
类图与源码解析
InputFormat类提供了两个关键抽象方法:getSplits()和createRecordReader()。getSplits()负责规划文件切分策略,定义逻辑上的分片,而RecordReader则从这些分片中读取数据。
InputSplit类承载了切分逻辑,表示了给定Mapper处理的逻辑数据块,包含所有K-V对的集合。
RecordReader类实现了数据读取流程,其子类如LineRecordReader,提供行数据读取功能,将输入流中的数据按行拆分,赋值为Key和Value。
具体实现与操作流程
在getSplits()方法中,FileInputFormat类负责将输入文件按照指定策略切分成多个InputSplit。
TextInputFormat类的createRecordReader()方法创建了LineRecordReader实例,用于读取文件中的每一行数据,形成K-V对。
Mapper任务执行时,通过调用RecordReader的nextKeyValue()方法,读取文件的每一行,完成数据处理。
在Map任务的run()方法中,MapContextImp类实例化了一个RecordReader,用于实现数据的迭代和处理。
总结
本文详细阐述了MapReduce框架中InputFormat的实现原理及其相关组件,包括类图、源码解析、具体实现与操作流程。后续文章将继续探讨MapReduce框架的其他关键组件源码解析,为开发者提供深入理解MapReduce的构建和优化方法。





