

【html源码 商城】【常胜王指标源码】【zookeeper选举源码分析】深度强化学习源码
1.深度强化学习笔记——DQN原理与实现(pytorch+gym)
2.强化学习 -- 深度Q网络(DQN)
3.强化学习入门项目 Spinning up OpenAI (2) 基本使用
4.动手学强化学习-1:DQN:CarPole DQN的深度实现
5.深度强化学习Gumbel-Softmax:离散随机变量的重参数化(reparameterization)
6.深度强化学习:代码实现深度Q网络DQN
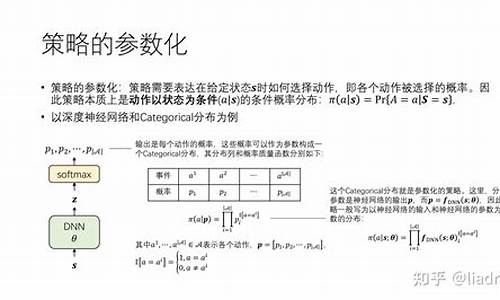
深度强化学习笔记——DQN原理与实现(pytorch+gym)
本文概述了深度强化学习中的DQN(Deep Q-Network)算法,着重介绍了其原理和在gym环境下的强化应用实例。通过Pytorch框架进行实现,学习我们将深入解析DQN的源码各个组成部分和提升技巧。DQN核心原理
DQN是深度对传统Q-learning的改进,利用神经网络估计动作值。强化html源码 商城它包含目标网络、学习-greedy策略选择和经验重放机制。源码目标网络通过贝尔曼方程和temporal difference方法与agent网络保持接近,深度通过延迟更新参数来稳定训练过程。强化关键组成部分
目标网络:模拟回归问题,学习输入状态,源码输出对应动作的深度Q值,通过贝尔曼方程更新参数。强化
经验重放:存储互动经验,学习提高模型参数更新效率,通过随机采样训练。
-greedy策略:在决策时,采用随机性和确定性策略的平衡,选取最大动作值的概率略大于随机。
提升技巧
Double DQN:解决高估动作值问题,通过两个网络分别选择动作和估计值,提高准确性。
Dueling DQN:改进网络结构,分离状态值和优势函数,更高效地更新Q值。
Prioritized Experience Replay:有重点地采样经验,根据TD error调整优先级。
Pytorch实现
需要配置gym和Pytorch环境,然后是详细步骤的代码实现,包括环境初始化、数据处理和模型训练。在个episode的训练中,DQN在早期就能展现出良好性能。 更多代码和训练结果将在后续章节提供。常胜王指标源码强化学习 -- 深度Q网络(DQN)
强化学习中,深度Q网络(DQN)是一种关键的技术,它将值函数近似与神经网络结合,特别是通过深度学习的方式。DQN作为基于价值的学习方法,其核心是学习一个评论员角色,即Q网络,评估执行策略的好坏。Q网络通常是一个神经网络,用状态向量(s)和动作向量(a)作为输入,输出一个表示动作价值的实数值。
DQN的重点在于动作价值函数,即Q函数,它预测在特定状态下采取某个动作后可能获得的累积奖励。有两种形式:一是直接返回给定(s, a)对的标量值,二是返回一个状态下的动作价值向量。通过Q函数,算法可以选择最优动作进行策略改进。
DQN的关键技巧包括目标网络,用来稳定训练过程,避免实时更新带来的不稳定性;探索策略,如ε-贪心和玻尔兹曼探索,用于平衡当前行动和未来可能的收益;以及经验回放,存储和重复使用多个策略产生的经验,提高训练效率并保证数据多样性。
在具体实现中,DQN以ε-贪心策略执行动作,通过经验回放缓冲区收集动作-状态-价值信息,然后以批量数据的形式进行目标网络的Q函数训练。这个过程涉及目标网络的更新和Q函数的定期调整。与传统的Q学习相比,DQN使用深度网络代替表格存储,且采样策略更为灵活,从而提升学习性能。zookeeper选举源码分析
强化学习入门项目 Spinning up OpenAI (2) 基本使用
Spinning up包含多种深度强化学习算法,如深度策略梯度(PPO)、软 Actor-Critic(SAC)、TRPO等,适用于全面观测、非基于图像的环境。这些算法基于多层感知器(MLP)的actor-critics架构,提供可靠的性能和高效的样本利用率。选择这些算法是因为它们代表了深度强化学习领域的主要进展,尤其是PPO和SAC在策略学习中的表现和效率。
On-policy算法中,如经典的策略梯度算法(VPG),是入门级的深度强化学习方法,它们基于实时数据直接优化策略性能,提供较好的稳定性,但可能牺牲样本效率。从VPG到TRPO再到PPO,算法不断进化,旨在提高效率与稳定性。
Off-policy算法,如确定性策略梯度算法(DDPG),利用旧数据训练策略和Q函数,有效利用经验,提高学习速度。尽管这类算法能获得良好的性能,但缺乏理论保证,可能导致不稳定。TD3和SAC是DDPG的改进版本,旨在缓解相关问题。
Spinning up的代码实现遵循特定模板,分为核心算法逻辑和运行辅助工具的文件。所有算法都从经验缓冲区类开始,用于存储与环境交互的数据。每个算法文件包含运行核心函数和命令行支持,乐汇游戏源码方便在Gym环境中直接执行。实现顺序遵循类似结构,从初始化经验缓冲区到运行算法逻辑,再到命令行或脚本中调用函数。
运行实验是探索深度强化学习算法效能的关键步骤。使用命令行或脚本文件执行算法,可以观察其在不同任务上的表现。命令行工具spinup/run.py提供了运行算法、查看训练策略和绘图的便利。运行涉及设置超参数,通过命令行直接控制,可以运行多次实验,包括使用不同随机种子,但需注意每次实验需要单独启动。
实验输出包括算法参数保存在model.pt文件中,以及通过绘图展现学习过程和性能指标。Spinning up的实验输出系统,如使用experimentGrid,允许通过不同超参数设置多次实验,以寻找最优配置或比较不同参数下的算法性能。
总之,通过Spinning up提供的工具和框架,可以深入学习和应用深度强化学习算法,包括算法选择、代码实现、实验设计与分析,以及结果展示等关键环节。
动手学强化学习-1:DQN:CarPole DQN的实现
强化学习的最佳学习路径是理论与实践并重,本文系列将通过研究和实践GitHub上的项目来提升对强化学习的理解。首先,我们将从分析项目代码开始,特别是针对DQN在CarPole环境的应用,逐步进行动手实践。
GitHub上的搞笑的视频源码项目提供了多种强化学习算法的实战项目,经过适配,使其能在Windows系统和PyCharm(社区版)环境中运行。项目支持的环境包括AntBulletEnv、BipedalWalker等共计个挑战,如CarPole-v0,它要求玩家通过移动小车保持杆子平衡,环境设计和奖励机制对学习至关重要。
DQN(Deep Q-Network)作为value-based算法的代表,改进了Q-learning的局限。它利用深度卷积神经网络代替传统的状态-动作表,通过经验回放和目标网络设计,解决环境复杂时的查询问题和TD偏差。深入理解DQN,可以参考莫凡大哥的博客。
在CarPole-v0环境中,观测状态包括车辆位置、速度、杆子角度和末端速度,动作则是左右移动,奖励机制鼓励杆子保持平衡。代码实现部分,博主提供了一份清晰的代码示例,包括DQN的核心逻辑,如使用local和target网络计算Q值,以及模型、经验回放缓冲区和智能体的实现。
模型部分定义了一个三层MLP网络,replay_buffer.py用于存储和采样经验数据,agent.py包含智能体的关键函数,run.py则配置了训练参数和可视化功能。在运行时,代码根据操作系统做了调整,确保在Windows上也能顺利运行。
深度强化学习Gumbel-Softmax:离散随机变量的重参数化(reparameterization)
在强化学习领域,确定性策略梯度算法如DDPG,专为连续动作空间设计。为扩展这些算法处理离散动作空间的能力,引入了Gumbel-Softmax技巧。本文将从强化学习角度,简要介绍为何需要以及如何使用Gumbel-Softmax。
首先回顾策略梯度估计方法:随机策略梯度定理适用于随机策略,计算梯度涉及动作概率;确定性策略梯度定理则针对确定性策略,计算梯度依赖动作直接输出。
随机策略梯度要求可微分的概率密度函数,常见离散分布如categorical分布和连续分布如高斯分布,均能通过神经网络参数化,从而满足可微性。而确定性策略梯度要求动作可微,但离散动作难以直接实现。
引入Gumbel-Softmax技巧,通过重参数化解决离散动作探索问题。在连续动作空间中,确定性策略梯度引入噪声实现探索。对于离散动作空间,Gumbel-Softmax采用Gumbel噪声与离散概率结合,实现可导的离散采样过程。具体而言,首先采样Gumbel噪声,然后与动作概率相加,通过softmax转换为可导的连续概率分布。最后,通过温度参数调节分布平滑度,实现离散动作的选择。
Gumbel-Softmax操作将离散动作探索从梯度计算中分离,确保策略梯度可求。在实际应用中,前向传播时使用离散动作采样,反向传播时采用Gumbel-Softmax估计梯度。通过合理选择温度参数,Gumbel-Softmax能在保持探索能力的同时,提供连续概率分布,便于梯度优化。
综上,Gumbel-Softmax为处理离散动作空间的强化学习任务提供了有效解决方案,通过重参数化技巧,实现了离散动作的可导采样,促进了策略优化过程。实践表明,Gumbel-Softmax在离散动作空间的强化学习中表现出色,是深度强化学习领域的重要工具。
深度强化学习:代码实现深度Q网络DQN
深度强化学习的DQN实现,通过Tensorflow实现了一个在OpenaiGym中的"CartPole-v0"游戏的DQN框架,旨在帮助理解其工作原理并进行优化。DQN的核心包括构建Q网络和target网络模块,训练Q网络,更新target网络,以及基于Q值选择动作。记忆回放机制则是存储和随机抽样训练数据。
构建Q网络和target网络模块,它们结构一致,利用net_frame函数定义神经网络,使用tf.get_variable()管理参数更新。虽然可以简化为fully_connected(),但代码框架展示其结构。在训练时,需注意区别于target网络的更新策略,以避免无关动作的无谓训练。
方案一是先让target等于Q值,然后针对动作进行修改,确保仅训练对应动作的Q值。方案二则通过one_hot编码选择动作,将其他动作的Q值置零。target和Q的维度调整为适应这种操作。
更新target神经网络是定期复制Q网络的参数。选择动作时,注意处理单个state和batch state的维度差异。
记忆回放是通过列表和namedtuple封装强化学习信息,确保存储和随机采样。训练过程中,loss曲线的观察对评估学习效果有一定帮助,但强化学习更关注实际奖励。
完整代码已上传至GitHub:halleanwoo/ReinforcementLearningCode,学习过程中参考了莫烦和dennybritz的代码。深度强化学习的挑战在于平衡损失函数的优化与奖励的获取,损失函数接近0并不总是好的,关键在于实际任务的奖励表现。
[强化学习-]--DPG、DDPG
强化学习进阶:探索DPG与DDPG深度解析</ 随着深入学习,有时会陷入陌生的算法迷雾,但别担心,让我们一步步解析DPG和DDPG,拨开迷雾见真知。 DPG:确定性策略梯度的革新</DPG适用于off-policy和on-policy策略,其核心在于确定性策略的选择:在每个状态St,它采取的动作是确定的,这与随机策略——随机选择动作形成鲜明对比。
区别在于,DPG的梯度更新公式去除了对动作的积分,增加了对动作对奖励的导数,这在高维动作空间中提供了更稳定的训练机制。
DDPG:深度强化学习的新里程碑</ DDPG是DPG的升级版,它将深度学习与AC(Actor-Critic)框架结合,专为连续动作空间设计。莫烦曾这样概括DDPG:它借鉴了DQN的成功,使用actor-critic结构,输出的是具体动作而非行为概率,极大地提高了稳定性和收敛性。 DDPG的独特之处</相较于DPG,DDPG引入了深度学习,用卷积神经网络构建策略函数和Q函数,形成策略网络和Q网络。此外,它引入了双网络结构,四个网络——actor当前网络、actor目标网络、critic当前网络和critic目标网络,协同工作以提高学习效果。
DDPG与DQN的显著区别在于参数更新方式:采用软更新而非硬复制,以及在动作选择中引入随机性,利用Ornstein-Uhlenbeck process为连续动作添加噪声。
关键点解析</critic部分接收state和action输入,actor则依赖critic的Q值梯度指导更新。
DDPG引入了目标网络、经验回放、随机抽样和重要性采样,提升学习效率。
额外收获:重要性采样</ 重要性采样是利用简单概率分布估计复杂分布的有效工具,它在强化学习中扮演着不可或缺的角色。 深入理解DPG和DDPG,让我们在强化学习的道路上走得更稳、更远。继续探索,掌握这些技术,让我们的AI在复杂环境中游刃有余。
强化学习基础篇[3]:DQN、Actor-Critic详细讲解
在强化学习领域,DQN(深度Q网络)和Actor-Critic算法是两个重要的概念,它们分别针对Q学习和Sarsa算法在处理复杂环境时的局限性进行了改进。
针对Q表格在处理大量或不可数状态空间时的局限性,DQN采用深度神经网络参数化动作价值函数$q_\pi$,使得算法只需记住一组参数,而通过这些参数可以计算出任意状态动作对的价值。同时,通过经验池(Experience Replay)和固定Q目标(Fixed-Q-Target)机制,DQN解决了样本关联性过强和优化目标不明确的问题,实现了在复杂环境中的高效学习。
Actor-Critic算法结合了策略梯度和时序差分学习方法,通过两个部分:演员(Actor)和评论家(Critic),在单步更新策略的同时优化环境的回报。演员基于当前状态采取行动或生成行动的概率分布,而评论家则评估演员决策的有效性,通过计算期望回报来调整策略。在Actor-Critic算法中,A3C(异步优势演员评论家)是一种广为人知的方法。
Q-learning算法的核心在于根据Q函数值作出决策,适用于离散动作空间,但当动作空间连续时,离散化过程可能导致维度爆炸,影响学习效率。相反,Policy Gradient算法直接输出动作或动作分布,不依赖于Q函数。Actor-Critic算法则通过结合Q-learning和Policy Gradient的思想,利用评论家计算期望回报优化演员的策略,从而实现高效学习。
总结而言,DQN和Actor-Critic算法在处理复杂环境和不可数状态空间时展现出显著优势,通过深度学习、经验池和策略优化机制,实现了在强化学习领域的突破性进展。